Аргументы поиска
Простейший способ снизить объем ввода/вывода, необходимого для обработки запроса - это уменьшить количество строк, которые должен проанализировать SQL Server. Это делается с помощью задания выборочных критериев поиска в обороте WHERE, входящем в структуру запроса. Эти критерии обычно называются аргументами поиска. Они помогают оптимизатору запросов, давая подсказки относительно того, какой метод доступа к данным окажется самым быстрым. Аргументы поиска представляются в виде следующей записи:
Имя Столбца оператор [Имя Столбца или константа]
где оператором может быть один из следующих знаков сравнения =, <, >, <=, <=. Аргументы поиска могут быть соединены булевским оператором AND. Фраза BETWEEN ..... AND также допустима, поскольку задаваемое ею условие может быть по-другому сформулировано с помощью операторов >= и <=. Ниже приведено несколько примеров аргументов поиска:
LastName = ..... LastName >= ..... OrderDate .....
Обратите внимание на то, что не был упомянут ни один отрицательный оператор. Для обработки запроса, содержащего оборот WHERE (ProductId <>2) SQL Server просматривает каждую строку, проверяя, не равно ли ее значение двум. Даже индекс по ProductId не так уж сильно облегчает ситуацию, если только строки, содержащие значение 2 не составляют весьма незначительную часть таблицы. Почти во всех случаях SQL Server выполнит этот запрос просмотром таблицы, а не индекса.
С точки зрения оптимизации запросов оператор LIKE почти столь же неэффективен, как и оператор NOT. Если в вашем запросе присутствует, например, такой оборот
WHERE LastName LIKE '%Мс%',
то SQL Server выполнит поиск заданного образца во всем столбце. Индекс не поможет, поэтому можно предполагать, что оптимизатор запросов выберет сканирование таблицы. Существует только один тип исключений, - когда аргумент поиска выглядят, к примеру, следующим образом:
WHERE LastName LIKE 'Le%'.
Разница заключается в том, что этот критерий поиска логически эквивалентен выражению
WHERE LastName >= 'Le' AND LastName < 'LF',
которое по определению представляет собой аргумент поиска.
Вообще говоря, аргументы поиска помогают запросам тем, что облегчают оптимизатору запросов определение степени селективности индекса при обработке данного запроса. Обороты, использующие операторы =, <, >, являются именно такими аргументами поиска, поскольку они ограничивают область поиска только строками, попадающими в результирующий набор. Оператор = ограничивает область поиска до единственной строки, а операторы < и > сужают ее до некоторого диапазона.
Селективность оборота отражает, насколько эффективно аргумент поиска сужает область просмотра. Этот показатель может быть измерен отношением числа возвращаемых строк к суммарному количеству строк в таблице. (Приведенное определение нарочно немного упрощено, для того чтобы сделать обсуждение более наглядным.) Низкий процент означает, что оборот обладает высокой селективностью; напротив, высокий процент соответствует слабой селективности. Поскольку оператор AND коммутативен (то есть, a AND b означает то же самое, что и b AND a), оптимизатор запросов может выбирать для обработки запроса наиболее селективный оборот из числа оборотов, объединенных оператором AND. Это оправдано, ведь выбор наиболее селективного оборота способен заметно снизить объем выполняемых операций ввода/вывода.
В качестве примера рассмотрим запрос
SELECT .... "213-46-8915"....
Оба оборота, составляющие оборот WHERE, являются аргументами поиска. Но столбец state (штат), скорее всего, не обеспечит получение единственного значения, а столбец au_id непременно гарантирует это, так как он является первичным ключом таблицы. Чтобы понять, что оборот au_id = "213-46- 8915" обладает очень высокой селективностью, а оборот state = "СА", наоборот, средней или даже низкой, вряд ли требуется знать что-либо еще. Конечно, если бы нашлась только одна строка, в столбце state которой было бы значение, соответствующее штату СА, то оба оборота были бы одинаково селективны.
Оптимизатор запросов решает, насколько селективен аргумент поиска, исходя из статистики соответствующего индекса. Статистика дает приблизительное представление о том, сколько записей будет удовлетворять заданному критерию. В таком случае, если оптимизатор запросов знает, сколько строк содержится в таблице, и сколько строк будет возвращено при использовании условий обеих частей оборота WHERE, то не составит труда решить, какой индекс целесообразно использовать. (Применение статистики в SQL Server 7.0 более подробно описано в статье Кэйлен Дилани "Статистика SQL Server : полезный инструмент оптимизатора запросов".) В рассматриваемом запросе, если имеются индексы и по столбцу state, и по столбцу au_id, то оптимизатор запросов выберет индекс по au_id. Если же индекс по au_id отсутствует, а по state создан, то оптимизатор запросов выберет его. Это вполне логично, поскольку в любом случае применение индекса более селективно, чем сканирование всей таблицы. При отсутствии обоих индексов единственным остающимся решением является сканирование таблицы для выявления всех строк, которые удовлетворяют условиям.
(Более подробно работа оптимизатора запросов изложена в книге "SQL Server 6.5 корпорации Microsoft " ("Microsoft SQL Server 6.5 unleashed"), выпущенной издательством в 1998 году. В ней рассмотрено несколько наиболее распространенных сценариев. Конечно, проработка каждого примера займет время, но зато вы станете гораздо лучше писать запросы, если разберетесь в том, каким образом действует оптимизатор. В книге "Внутри SQL Server 6.5" ("Inside SQL Server 6.5" ) также хорошо рассказано о работе оптимизатора запросов.)
Что оптимизировать?
SQL Server 6.5 использует стоимостной оптимизатор запросов. Для большинства запросов наибольший вклад в стоимость вносят операции ввода/вывода, связанные с использованием диска. Поскольку скорость работы жесткого диска в сотни раз ниже скорости выполнения операций в оперативной памяти, то что бы ни предпринималось для уменьшения числа обращений к диску, безусловно, окажет влияние на производительность. Поэтому на базовом уровне сначала следует попробовать оптимизировать физический ввод/вывод, - считывание страницы с жесткого диска, а уже затем логический ввод/вывод, - считывание страницы памяти.
Для оптимизации сервера прежде всего следует убедиться в том, что для SQL Server выделен максимально возможный объем оперативной памяти. Логическое чтение всегда происходит во много раз быстрее, чем физическое. В идеальном случае места в кэше оперативной памяти должно быть достаточно для размещения всей базы данных. К сожалению, нельзя остановиться только на минимизации физических операций чтения. Даже логическое чтение занимает какое-то время, а тысячи и даже миллионы таких операций потребуют значительно больше времени.
В качестве примера рассмотрим простое объединение двух таблиц:
SELECT ..... ......
Один из клиентов спросил автора статьи, почему этот запрос выполняется так долго. После того, как автор статьи запустил утилиту SHOWPLAN и взглянул на план запроса, ответ стал очевиден: таблица Payroll_Checks не имела индекса по столбцу empId. В таблице Employees содержалось около 10000 записей, а таблицу Payroll_Checks составляли 750 000 строк. Поскольку индекс отсутствовал, SQL Server сканировал таблицу Payroll_Checks 10 000 раз. Когда автор прервал выполнение запроса, сервер уже выполнил 15 миллионов логических операций ввода/вывода. Создание индекса по столбцу сократило время обработки до секунд, а число логических операций ввода/вывода до приблизительно 750000.
В предлагаемой статье рассматриваются способы
, #03/2000
Татьяна Крамарская
В предлагаемой статье рассматриваются способы получения информации о физической структуре базы данных, отражение этой структуры в служебных таблицах и динамика работы SQL Server 7.0 с экстентами.
Я думаю, этот материал будет интересен специалистам, которые знакомы с документацией по SQL Server 7.0, уже имеют опыт работы и хотят глубже проникнуть в механизмы, используемые сервером.
Физическая структура данных SQL Server 7.0, в курсах Microsoft Official Curriculum (MOC), к сожалению, не рассматривается. В документации общая схема, конечно, изложена, но не описана динамика роста таблиц и индексов. Предлагаю рассмотреть динамику использования сервером физической структуры данных на простых примерах.
Не буду повторять сведения из документации, напомню лишь, что страница - это 8К, а экстентом называют последовательно расположенные 8 страниц (64К). SQL Server использует два типа экстентов: однородные и смешанные. Однородные экстенты всегда принадлежат только одному объекту. Смешанный экстент может использоваться восемью объектами.
Для изучения физической структуры данных проведем простой эксперимент.
Создадим несколько маленьких таблиц, которые не имеют кластеризованного индекса, т. е. расположены на диске вперемежку.
Итак, три таблицы TA1, TA2 и ТA3 в базе данных MYDB.
USE MYDB
CREATE TABLE TA1 (COL_1 CHAR (8000) NOT NULL)
CREATE TABLE TA2 (COL_1 CHAR (8000) NOT NULL)
CREATE TABLE TA3 (COL_1 CHAR (8000) NOT NULL)
Проверим, где расположена первая страница каждой таблицы и сколько места выделено и используется в таблице TA1. Вспомним, что поле FIRST - это первая страница, ROOT - последняя, FIRSTIAM - первая страница в списке IAM-страниц, индексных карт размещения.
В SQL Server 7.0 страница всегда идентифицируется парой параметров <fileid><pageno>, где <fileid> - идентификатор файла, а<pageno> - номер страницы в этом файле. Номера страниц уникальны только внутри одного файла. Поэтому, когда мы говорим о номере страницы, то подразумеваем именно два параметра. Именно в таком виде, в двух частях, эта информация и хранится в полях системной таблицы sysindexes. В таблице sysindexes все идентификаторы страниц хранятся в шестнадцатеричном виде с обратным порядком байтов. Для прочтения идентификаторов нужно сначала поменять порядок байтов, а потом перевести результат в десятичный вид.
Ниже приведена программа, которая выполняет эту работу, см. Листинг 1.
Результат имеет вид, показанный на Рисунке 1:

РИСУНОК 1.
Итак, мы видим, что первые страницы таблиц расположены не подряд, а через одну. Потому что сразу за первой страницей данных таблицы следует ее индексная карта размещения, IAM-страница.
Добавим одну запись и посмотрим на занимаемое таблицей пространство.
INSERT INTO TA1(COL_1) VALUES ('1')
EXEC SP_SPACEUSED TA1
name rows reserved data index_size unused -------------------------------------------
TA1 116 KB 8 KB 8 KB 0 KB
Теперь добавим еще одну запись и посмотрим, как изменилось значение поля ROOT, указывающего на последнюю страницу (Листинг 2).
Один из возможных результатов выглядит так:
Root converted root -------------------------------
1:100 0x6400000000100
Повторим эту процедуру семь раз, увеличивая соответственно значение поля COL_1, пока в таблице не появится 9 записей.
Еще раз выберем информацию из таблицы sysindexes, как мы делали ранее, результат представлен на Рисунке 2:
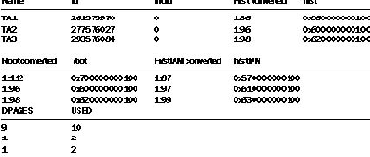
РИСУНОК 2.
Выполним хранимую процедуру
EXEC SP_SPACEUSED TA1
name rows reserved data index_size unused -------------------------------------------
TA1 9 136 Kв 72 Kв 8 Kв 56 Kв
Как видно из результата выполнения sp_spaceused, размер зарезервированного пространства 136 Кбайт, а размер данных 72 Кбайт.
Исследуем теперь заголовок страницы данных и индексной карты размещения.
Чтобы прочитать заголовок страницы, используем команду DBCC PAGE.
В качестве номера страницы будем подставлять значение полей FIRST, ROOT и FIRSTIAM из таблицы sysindexes, предварительно преобразовав их.
Например, для первой страницы таблицы TA1:
DBCC TRACEON (3604)
DBCC page ('MYDB', 1,86,0,0)
Результат на Рисунке 3.
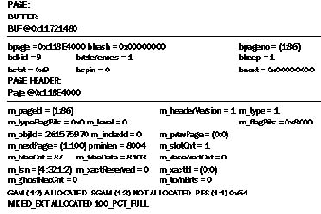
РИСУНОК 3.
Заметьте, что идентификатор объекта (m_objId) в заголовке страницы соответствует результату выполнения оператора SELECT OBJECT_ID ('TAl'), и страница принадлежит таблице ТA1.
Тип экстента смешанный, страница заполнена на 100%.
Аналогичным образом можно прочитать заголовок индексной карты размещения.
DBCC TRACEON (3604)
DBCC page ('MYDB', 1,87,0,0)
Результат представлен на Рисунке 4.

РИСУНОК 4.
Заметим, что в заголовке страницы указан ее тип IAM_PG, тип экстента и заполнение.
Прочитаем заголовок последней страницы таблицы ТA1.
DBCC TRACEON (3604)
DBCC page ('MYDB', 1,112,0,0)
Результат на Рисунке 5.

РИСУНОК 5.
Тип экстента в данном случае не смешанный, а однородный.
Для более эффективного управления дисковым пространством SQL Server не выделяет маленьким таблицам сразу целый экстент. Для новой таблицы или индекса, как правило, выделяется место на смешанном экстенте. Когда объем таблицы или индекса увеличивается до восьми страниц, все последующие экстенты будут однородными. Место выделяется на доступных смешанных экстентах до тех пор, пока данные не займут по объему восемь страниц, тогда следующий выделенный экстент будет полностью принадлежать таблице. Если на смешанных экстентах места нет, а объем таблицы не достиг восьми страниц, выделяется новый экстент, но он будет объявлен смешанным. Например, таблица занимает две страницы на смешанном экстенте, и в нее еще добавляется сразу шесть записей; а если свободных страниц на смешанных экстентах нет, будет выделен новый смешанный экстент, и на нем разместится 6 записей. Потом добавляется еще одна запись. Будет выделен полный новый однородный экстент, и на нем размещена новая запись. Таким образом, начало таблицы в подобных случаях располагается на смешанном экстенте. Однако возможны и другие варианты. Например, используем оператор SELECT INTO. Выберем из нашей таблицы ТА1 7 записей и поместим их во вновь созданную таблицу ТА4.
SELECT * INTO TA4 FROM TT1 WHERE COL_1 NOT IN ('8','9')
Каким образом при этом будет выделено место? Результат чтения из sysindexes может выглядеть так, как показано на Рисунке 6.

РИСУНОК 6.
Индексирование: скорее искусство, чем наука
Невозможно писать эффективные запросы, ничего не зная про индексы таблиц. Без хороших индексов даже самые простенькие запросы могут ужасающим образом замедлить работу системы. Единственный способ защиты от этого, - знать строение данных и рассматривать индексы в качестве неотъемлемой части ваших запросов.
Те индексы, которые прекрасно работали во время проектирования и тестирования, могут оказаться практически неприемлемыми на этапе промышленной эксплуатации системы. Это часто вызвано тем, что представление разработчиков о структуре данных имеет мало общего с реальностью. Автор данной статьи видел системы, которые замечательно работали у одних клиентов, и показывали совершенно неудовлетворительные результаты у других. Это было связано с тем, что способ кластеризации данных в таблице не позволял оптимизатору запросов должным образом применять индексы. Если вам поступают жалобы на производительность вашей системы, то имейте в виду эту ситуацию и не полагайтесь на то, что одни и те же индексы подойдут всем вашим клиентам.
А теперь очертим основы концепции правильного выбора типа индексов и столбцов, по которым они должны строиться. Прежде всего, поскольку для каждой таблицы можно создать только один кластеризованный индекс, его надо строить так, чтобы удовлетворить максимально возможное число запросов. Кластеризованные индексы более всего полезны для запросов, использующих условия на диапазон значений. Это обусловлено тем, что уровень листьев такого индекса содержит данные, отсортированные в порядке значений индекса. Наибольший выигрыш от применения кластеризованного индекса получается в тех случаях, когда оборот WHERE запроса содержит операторы >, < или BETWEEN .... AND, а также оборот GROUP BY, в которых столбцы перечислены в том же порядке, что и в индексе. Хотя это может и не помочь в поиске строк, но кластеризованный индекс способен улучшить производительность системы при обработке оборотов ORDER BY, если и в индексе и в обороте ORDER BY использованы одни и те же столбцы, причем в совпадающем порядке.
Поскольку промежуточный уровень кластеризованного индекса крайне мал, он прекрасно работает при поиске уникальных значений. Однако некластеризованные индексы лучше работают для "точечных" запросов, которые должны найти небольшое число строк. Обороты WHERE с оператором = являются первыми кандидатами на построение некластеризованных индексов по соответствующим столбцам. Этот тип индекса также очень хорош для функций агрегирования MIN и MAX, потому что легко найти первую и последнюю записи для диапазона значений, если воспользоваться уровнем листьев индекса. Наконец, некластеризованные индексы очень существенно ускоряют выполнение функции COUNT, так как сканирование уровня листьев индекса происходит намного быстрее сканирования таблицы.
Куда двигаться дальше?
Полезно воспользоваться окном ISQL, для того чтобы проследить за изменением реакции SQL Server на введение различных индексов для одной и той же таблицы. Enterprise Manager может показать сведения о селективности индексов таблицы, а SQL Trace позволяет получить сценарии всех запросов, направляемых на сервер. Настраивая индексы, переделывая сценарии и отмечая изменения времени обработки запросов, можно получить представление о том, какие индексы будут наилучшими при промышленной эксплуатации системы. Просто следите за количеством операций ввода/вывода, необходимых для обработки ваших запросов, и не забывайте, что любое средство снижения их числа окажет положительное влияние и на производительность системы в целом.
Морис Льюис () является президентом компании Holitech, специализирующейся на консалтинге и обучении технологиям Internet и разработкам корпорации Microsoft в области баз данных.
Литература
С. Кузнецов. Развитие идей и приложений реляционной СУБД System R.
Воссоединение SQL в 1995 г.: люди, проекты, политика. Под редакцией Пола МакДжонса, в переводе С. Кузнецова.
Michael Stonebraker, Eugene Wong, Peter Kreps, Gerald Held. The Design and Implementation of INGRES. TODS 1 (3), 1976. Patricia G. Selinger, Morton M. Astrahan, Donald D. Chamberlin, Raymond A. Lorie, Thomas G. Price. Access Path Selection in a Relational Database Management System. SIGMOD Conference, 1979. С. Кузнецов. Методы оптимизации выполнения запросов в реляционных СУБД.
С. Чаудхари. Методы оптимизации запросов в реляционных системах. // СУБД, № 3, 1998. M. Jarke, J. Koch. Query Optimization in Database Systems. ACM Comput. Surv., 1984, 16, No. 2. W. On Optimizing an SQL-Like Nested Query. ACM Trans. Database Syst., 1982, 7, No. 3. R.A. Ganski, H.K.T. Wong. Optimization of Nested SQL Queries Revisited. Proc. ACM SIGMOD Int. Conf. Manag. Data, San Francisco, Calif., 1987 May. New York. U. Dayal. Of Nests and Trees: A Unified Approach to Processing Queries That Contain Nested Subqueries, Aggregates, and Quantifiers. Proc. 13th Int. Conf. Very Large Data Bases, Brington, England, 1987 Sept.. G. Piatetski-Shapiro, C. Connel. Accurate Estimation of the Number of Tuples Satisfying a Condition. ACM SIGMOD Record. 1984, 19, No. 2. M. Lee, J. Freytag, G. Lohman. Implementing an Interpreter for Functional Rules in a Query Optimizers. Proc. 14th Int. Conf. Very Large Data Bases, Los Angeles, Calif., 1988 Aug.-Sept.
document.write('');

02.08 - 02.08 - 02.08 - 02.08 - 02.08 - 01.08 - 01.08 - 01.08 - 01.08 - 01.08 - 01.08 - 01.08 - 01.08 - 01.08 - 01.08 - 31.07 - 31.07 - 31.07 - 31.07 - 31.07 -
Архив новостей
(66)
2 Август, 17:53
(19)
2 Август, 17:51
(34)
2 Август, 15:40
(42)
2 Август, 15:35
(1)
2 Август, 14:54
(3)
2 Август, 14:34
(3)
2 Август, 14:15
(2)
2 Август, 13:34
(7)
2 Август, 13:04
(3)
2 Август, 12:28
BrainBoard.ru
Море работы для программистов, сисадминов, вебмастеров.
Иди и выбирай!
google.load('search', '1', {language : 'ru'}); google.setOnLoadCallback(function() { var customSearchControl = new google.search.CustomSearchControl('018117224161927867877:xbac02ystjy'); customSearchControl.setResultSetSize(google.search.Search.FILTERED_CSE_RESULTSET); customSearchControl.draw('cse'); }, true);
|
|
| IT-консалтинг | Software Engineering | Программирование | СУБД | Безопасность | Internet | Сети | Операционные системы | Hardware |
| PR-акции, размещение рекламы — , тел. +7 495 6608306, ICQ 232284597 | Пресс-релизы — |
|
|
|
| This Web server launched on February 24, 1997 Copyright © 1997-2000 CIT, © 2001-2009 |
|
|
| Внимание! Любой из материалов, опубликованных на этом сервере, не может быть воспроизведен в какой бы то ни было форме и какими бы то ни было средствами без письменного разрешения владельцев авторских прав. |
|
Покупайте — легендарный автомобиль, который обладает превосходной эргономикой, проходимостью, дизайном, созданным в итальянском дизайн-ателье Bertone. |
Магический размер строки
Первый шаг в минимизации операций ввода/вывода - убедиться в том, что строка сделана настолько компактной, насколько это возможно. В SQL Server строки не могут простираться на несколько страниц. В SQL Server 6.5 заголовок страницы не может превышать 32 байтов, а данные - занимать более 2016 байтов. Каждая строка данных содержит также область переполнения строки. Максимально допустимая длина отдельной строки составляет 1962 байта, включая область переполнения. Это ограничение выбрано с таким расчетом, чтобы вставляемая или удаляемая строка базы данных смогла бы также поместиться в строку журнала транзакций. Поэтому, хотя длина одной строки и не превысит 1962 байтов, две строки могут полностью занять все 2016 байтов, отведенных под данные на странице. Следствием этого является тот факт, что определенные значения длины строки могут существенно понизить процент операций ввода/вывода. Например, если длина строки составляет 1009 байтов, то на странице уместится только одна строка. Если же уменьшить длину строки всего только на один байт, то на страницу поместятся две строки. То есть, можно наполовину снизить обращения к вводу/выводу для таблицы, убрав всего один байт! Аналогичные ситуации имеют место для следующих размеров строк: 673, 505, 404 байтов и т.д. Если вам удастся сохранить размер строки ниже указанных пределов, то тем самым вы уменьшите долю операций ввода/вывода соответственно на 33, 25 и 20 процентов.
Все строки могут иметь несколько байтов переполнения, которые следует учитывать в расчетах. Отметим, что переполнение строк переменной длины больше, чем переполнение строк фиксированной длины. Чтобы выяснить, имеется ли у вас на страницах неиспользуемое место, запустите DBCC SHOWCONTIG. Это позволит вам определить среднюю плотность страницы и среднее число свободных байтов на странице. Наиболее вероятными кандидатами на звание "чемпиона по расточительству пространства" будут те таблицы, у которых среднее число свободных байтов близко к размеру строки.
Аналогичным образом, ситуации неэкономного использования памяти часто возникают у таблиц, в которых было произведено удаление большого количества строк, и отсутствуют кластеризованные индексы. В результате удалений на страницах образуются пустые места, а поскольку SQL Server не может повторно использовать пространство страницы, если у таблицы нет кластеризованного индекса, то все новые строки данной таблицы располагаются на последней странице. В результате этого страницы такой таблицы будут заполнены менее, чем на 100 процентов, что увеличит число операций ввода/вывода. Прежде чем пытаться ужать длину строки подобной таблицы, создайте для нее кластеризованный индекс. После этого запустите еще раз DBCC SHOWCONTIG, чтобы увидеть, сколько у таблицы остается свободного места.
Настройка SQL Server 6.5 на обработку запросов c высокой производительностью
Журнал , #01/2000
Морис Льюис
Администраторам баз данных наверняка приходилось настраивать сервер базы данных на быструю и эффективную обработку посылаемых приложениями запросов. Независимо от того, кем было разработано приложение, - сторонними фирмами или своей командой программистов, на программу лучше смотреть, как на черный ящик, в котором ничего изменить нельзя. Выполнить настройку производительности на уровне сервера можно различными способами: улучшением организации ввода/вывода данных на диски, увеличением памяти или созданием и модификацией индексов. Но с другой стороны, производительность прикладной системы зависит от конструкции базы данных и от написанных для нее запросов. Те разработчики приложений, использующих базы данных, которые понимают, каким образом SQL Server оптимизирует и обрабатывает запросы, обычно создают программное обеспечение, обладающее наилучшей производительностью. И у них не возникает проблем и неприятных сюрпризов при расширении масштаба приложения от небольшой системы до крупного проекта. Существует несколько простых приемов для SQL Server 6.5, которые обеспечат оптимальную производительность, если применить их к базе данных и к запросам.
Непредвиденный ввод/вывод при обновлениях
Вы можете думать, будто вашей таблице не нужен кластеризованный индекс, потому что строки из нее не удаляются. В таком случае, для вас может стать неприятным сюрпризом известие о том, что оператор UPDATE тоже может создавать пустые места в таблице. На первый взгляд кажется, что такое прямолинейное обновление, как в следующем примере, не таит никаких опасностей:
UPDATE .... 9102 .....
Однако это обновление может потенциально стать причиной колоссального числа записей в журнал транзакций. Проблема проистекает из способа, которым SQL Server структурирует серии операций для предотвращения нарушения ограничений целостности. Приведем простой пример:
UPDATE .....
Если au_id является первичным (или уникальным) ключом, то обновление первой строки может привести к нарушению ограничения уникальности, особенно если au_id - монотонно возрастающая величина. Но ведь оператор UPDATE корректен, так каким же образом SQL Server сможет выполнить его без нарушения ограничений? Здесь SQL Server прибегает к использованию режима отсроченного обновления, при котором операция обновления разбивается на две части: сначала удаляется старая строка, а затем вводится новая, содержащая требуемое значение.
SQL Server обрабатывает эту ситуацию, помещая в журнал транзакций не операционные записи, говорящие о том, какую операцию необходимо выполнить. Затем, после выявления всех затрагиваемых строк, и записи в журнал операций удаления и вставки, SQL Server возвращается к началу транзакции и приступает к выполнению операций удаления. Когда все удаления будут произведены, SQL Server начинает вставлять строки. Все эти удаления и вставки теперь представляют собой полноценные операции, а потому сопровождаются модификацией всех затрагиваемых индексов.
Отсроченные обновления могут существенно снизить производительность как базы данных, так и приложения, поскольку они не только приводят к большим расходам пространства под записи журнала транзакций, но и выполняются медленнее, чем обновления в прямом режиме. Чем дольше происходит обновление, тем больше времени длятся исключающие блокировки, а следовательно, другим пользователям приходится дольше ждать освобождения страницы. Это повышает вероятность возникновения тупиковой ситуации.
SQL Server 6.5 способен выполнять операции обновления четырьмя различными способами. Самым быстрым является прямое обновление замещением. При этом не происходит никаких перемещений, а в журнал транзакций помещается единственная запись, содержащая информацию о том, какие байты получили новые значения. Самым медленным способом является отсроченное обновление, которое было описано выше. Оба других способа представляют собой прямые обновления (то есть никаких лишних записей в журнал транзакций не производится), но запись новых значений происходит не на то же самое место, на котором помещались обновляемые данные. Поэтому некоторые перемещения данных все-таки имеют место. Чтобы обновление, которое вы собираетесь сделать, проводилось в режиме прямого обновления замещением, должен быть исполнен такой длинный список условий, что в данной статье просто не представляется возможным все это изложить. В "SQL Server 6.5 Books Online" (BOL) есть раздел, называемый "Прямой режим обновления" (The update mode is direct). В нем перечислены некоторые условия, которые непременно должны выполнены, чтобы SQL Server произвел обновление прямым замещением. Однако в BOL иногда путаются прямое обновление и замещение, что приводит к некорректности некоторых рассуждений. Самым полным опубликованным описанием различных типов обновлений признана книга "Внутри SQL Server 6.5" (Inside SQL Server 6.5) Рона Саукапа, выпущенная в 1997 году издательством Microsoft Press.
Два основных условия, которые непременно должны быть выполнены, чтобы обновление проводилось в прямом режиме методом замещения, заключаются в следующем. Во-первых, нельзя обновлять ключевые столбцы в кластеризованном индексе, а во-вторых, таблица не может быть помечена для репликации. Модификации кластеризованного индекса заставляют SQL Server перемещать строку на новое физическое место, отвечающее ее содержанию. А это всегда сопровождается сначала удалением, а затем вставкой строки. При репликациях происходит чтение журнала и формирование команд ODBC для подписчиков. Поэтому комбинация удаление/вставка представляется наиболее простым описанием операции обновления. Обе ситуации исключают обновление прямым замещением.
Аналогичные правила применимы к столбцам переменной длины и к столбцам, содержащим неопределенные значения. При обновлениях, затрагивающих многие строки, столбец обязан иметь фиксированную длину, чтобы допустить замещение старого значения новым. SQL Server хранит столбец с неопределенными значениями как столбец переменной длины, даже в тех случаях, когда программист объявил его в качестве столбца с фиксированной длиной. Для обновления множества строк столбца с неопределенными значениями SQL Server всегда применяет отложенное обновление.
Прекрасные результаты приносит знание этих ограничений и их учет при конфигурировании базы данных, особенно когда вы стремитесь выжать все возможное из производительности при обновлениях. Применение методов, обеспечивающих прямое замещение, позволяет сэкономить на вводе/выводе при записи в журнал, на вводе/выводе при чтении логических страниц журнала, и кроме того, сберечь время на резервировании и восстановлении журнала, а также при восстановлении базы данных. При проектировании баз данных полезно придерживаться стандарта, в соответствии с которым следует использовать только столбцы фиксированной длины, не содержащие неопределенные значения. Если вы, читатель, программируете, то помните о свойствах обновляемых столбцов и учитывайте их влияние на производительность при написании операторов UPDATE. Кроме того, тщательно выбирайте момент для запуска этих операторов.
Оптимизация запросов: вечнозеленая область
Сергей Кузнецов
24.04.2003
Оптимизаторы запросов — наиболее хитроумные, наиболее сложные и наиболее интересные компоненты СУБД. Историю этого направления принято отсчитывать с середины 70-х годов, хотя наверняка исследования проводились и раньше. Пионерские работы, в которых были получены фундаментальные результаты, относящиеся к оптимизации запросов, были выполнены в рамках проектов System R корпорации IBM [1, 2] и Ingres университета Беркли [3]. В System R были заложены основы техники оптимизации запросов на основе оценок стоимости плана выполнения запроса [4]. В университетском проекте Ingres, фактически использовались методы, которые позже стали называть семантической оптимизацией запросов.
В маленькой редакторской заметке невозможно привести обзор подходов к оптимизации запросов в SQL-ориентированных СУБД. Могу порекомендовать собственный обзор [5] (достаточно старый, но остающийся актуальным) и существенно более новый обзор Чаудхари [6]. Здесь же мне бы хотелось отметить некоторые вехи в истории развития методов оптимизации, которые имеют непосредственное отношение к статье Маркла, Лохмана и Рамана.
Начнем с формулировки проблемы оптимизации SQL-запросов. (Трудно сказать, насколько тесно эта проблема и имеющиеся методы ее решения связаны со спецификой языка SQL; как показывает текущий опыт, многие аспекты оптимизации перекладываются, например, на совсем иной язык запросов Xquery.) Язык SQL декларативен. В формулировках SQL-запросов указывается, какими свойствами должны обладать данные, которые хочет получить пользователь, но ничего не говорится о том, как система должна реально выполнить запрос. Проблема в том, чтобы по декларативной формулировке запроса найти — или построить — программу (в мире SQL такую программу принято называть планом выполнения запроса), которая выполнялась бы максимально эффективно и выдавала бы результаты, соответствующие указанным в запросе свойствам. Более точно, основная трудность состоит в том, что нужно уметь (1) построить все возможные программы, результаты которых соответствуют указанным свойствам, и (2) выбрать из множества этих программ (найти в пространстве планов выполнения запроса) такую программу, выполнение которой было бы наиболее эффективным.
Заметной в этом направлении была работа [7], в которой, в частности, было показано, что всегда имеет смысл преобразовывать формулировку запроса к такому виду, чтобы ограничения индивидуальных таблиц производились до их соединения (predicate push down). Очень важную роль в истории логической оптимизации запросов сыграла серия статей, начало которой положил Вон Ким [8]. В них было показано, как можно преобразовать SQL-запросы, в разделе FROM которых присутствуют подзапросы, в запросы с соединениями. Важность этих результатов в том, что: (1) SQL стимулирует использование запросов с вложенными подзапросами; (2) в большинстве оптимизаторов запросов для реализации таких запросов используется некоторая фиксированная стратегия генерации планов (в основном, вложенные циклы); (3) альтернативные формулировки запросов с соединениями допускают порождения большего числа планов, среди которых могут находиться наиболее эффективные. Другими словами, этот подход позволяет разумным образом расширить пространство поиска оптимальных планов выполнения запросов.
Что касается второй части проблемы, то в подходе, предложенном IBM, общая оценка стоимости плана выполнения запроса базировалась на оценках селективности простых предикатов сравнения. Основной изъян работы Селинджер состоял в том, что эта работа основывалась на двух неправомерных предположениях о том, что распределение значений любого столбца любой таблицы базы данных является равномерным, а распределения значений любых двух столбцов одной или двух таблиц являются независимыми. Собственно, уже тогда было понятно, что опираясь на эти предположения, оптимизатор запросов может выбрать для исполнения далеко не самый оптимальный план запроса (а иногда и самый неэффективный план). Непреодолимая трудность заключалась в том, что было непонятно, каким образом надежно оценивать реальное распределение значений в данном столбце данной таблицы.
Абсолютно пионерская работа в этом направлении была выполнена Пятецким-Шапиро (кстати, этот господин является выпускником кафедры математической логики механико-математического факультета МГУ) [11]. Опираясь на статистику Колмогорова и используя оригинальный подход псевдогистограмм, он показал, каким образом можно достаточно строго аппроксимировать функцию распределения значений столбца таблицы на основе небольшого числа выборок из текущего содержимого базы данных. В большинстве современных СУБД оптимизаторы запросов основывают свои оценки на статистике в виде гистограмм Пятецкого-Шапиро.
Исключительно важную роль в истории оптимизации запросов сыграл экспериментальный проект IBM Starburst. Этот замечательный проект, на результатах которого основана современная DB2 Universal Database, преследовал цель создания действующего стенда СУБД, на котором можно было бы опробовать и сравнить разные методы организации систем, в том числе и методы оптимизации запросов. Проект продемонстрировал возможность построения системы и, в частности, подсистемы оптимизации запросов некоторым унифицированным образом, когда СУБД работает под управлением заданного набора правил в среде продукционной системы.
Теперь, что касается самонастраивающихся оптимизаторов запросов. Эта идея (как и большинство идей вообще) не нова. В конце 70-х — начале 80-х годов много писалось о так называемой «глобальной» оптимизации запросов, под которой, главным образом, понимался механизм автоматического поддержания набора индексов, обеспечивающих возможность оптимального выполнения запросов данной рабочей нагрузки СУБД. В то время результаты исследований не нашли практического применения. В конце 90-х к этой идее обратились исследователи корпораций Microsoft и Oracle (см., в частности, [6]).
Статья, представляемая вниманию читателей, имеет несколько иное направление. Это не столько самонастраиваемая, сколько адаптивная оптимизация, поскольку во время выполнения запроса собираются реальные (а не статистические) данные о состоянии базы данных, которые могут быть использованы как для оптимизации последующих запросов, так и для повторной оптимизации текущего запроса. Замечу, что Гай Лохман относится к старожилам лаборатории IBM Almaden Research Center; он начинал работать еще во время проекта System R. Мне было очень интересно читать и редактировать эту статью, чего и вам желаю.
SQL Server в вопросах и ответах
#01/99
 | Карен Уоттерсон независимый журналист, редактор и консультант по клиент-серверным системам и хранилищам данных. Ей можно написать по адресу . Брайан Моран президент группы пользователей и директор по технологиям СУБД Spectrum Technology Group. Имеет сертификаты MCSE, MCSD и MCT. Ему можно написать по адресу . |
В: Я установил SQL Server 7.0, но когда я запускаю Enterprise Manager, я не вижу баз данных master, model и msdb. Кроме того, я не вижу системных таблиц в пользовательских базах данных. В чем причина?
О: Вы указали SQL Server не отображать системные объекты. Щелкните правой клавишей мыши на имени сервера в Enterprise Manager и выберите Edit SQL Server Registration Properties. Поставьте метку в окошке напротив надписи Show system databases and objects.
В SQL Server 7.0 предусмотрена удобная функция, позволяющая включить или отключить отображение системных объектов и таблиц. Однако на наш взгляд, она могла бы быть более гибкой. В частности, можно было бы сделать так, чтобы пользователи могли видеть определенные системные объекты, например таблицу sysobjects.
В: Из-за особенности типа datetime в SQL Server 6.5 затруднены арифметические действия над датами и их форматирование. Почему в SQL 7.0 Microsoft не устранила этот недостаток и не добавила функции вроде LAST_DAY (последний день месяца) и NEXT_DAY (следующий день недели)?
О: Мы согласны, что работать с типом datetime трудно. В частности, в SQL Server для выполнения простых арифметических действий над датами (например, для прибавления к заданной дате нескольких дней), приходится пользоваться функцией DATEPART(). Однако при внесении изменений в основные типы данных могут возникнуть серьезные проблемы с обратной совместимостью. В SQL Server 7.0 операции с датами стало осуществлять несколько легче. В качестве примера приведем следующий SQL-код: DECLARE @datevalue datetime SELECT @datevalue = "1/1/99" PRINT "Добавим 5 суток" SELECT @datevalue + 5 PRINT "Теперь добавим 5.25 суток (или 5 суток 6 часов)" SELECT @datevalue + 5.25 Его выполнение на SQL Server 7.0 приводит к следующим результатам: z Добавим 5 суток 1999-01-06 00:00:00.000 Теперь добавим 5,25 суток (или 5 суток 6 часов) 1999-01-06 06:00:00:00.000
Как видно, SQL Server 7.0 позволяет добавлять время к заданной дате (в сутках) с помощью оператора сложения (+). Кроме того, для выполнения той же операции можно воспользоваться командой T-SQL DATEADD, хотя на наш взгляд, с оператором сложения работать проще.
Кроме того, упоминания заслуживает функция GETDATE(). Ею можно пользоваться для вывода текущей даты и времени в отчетах, а также при сравнениях и для датирования результатов контрольных проверок. Кроме того, GETDATE() можно пользоваться в качестве значения по умолчанию при вводе данных.
В: Для соединения системы на базе SQL Server 6.5 с системой на основе SQL Server 7.0 (я обладаю правами системного администратора) я испробовал следующий метод. На системе с SQL Server 7.0 я выполнил команду sp_addlinkedsrvlogin. Для создания одинакового набора параметров входа на обоих серверах я последовательно присвоил @useself значения FALSE и TRUE. Затем я выполнил sp_addlinkedserver и обновил каталог хранимых процедур на системе с SQL Server 6.5. Однако при попытке выполнить распределенный гетерогенный запрос я получил следующее сообщение об ошибке: Что я сделал неправильно?
О: Лучший путь устранения этой проблемы - просмотреть каждый шаг, разобраться, что делает SQL Server, и постараться понять, где ошибка. В данном случае вы, возможно, не разобрались с новой для SQL Server функцией связанных серверов; между тем, у процессов выполнения распределенных гетерогенных запросов и запросов более привычных видов есть немало общих этапов.
Провести диагностику данной проблемы без доступа к серверам нелегко, но в подобных случаях причину нередко следует искать в конфигурации NetLib или в конфликтах пользовательских прав на уровне системы безопасности самой NT. Чтобы упростить рассмотрение проблемы, назовем сервер, осуществляющий запрос, , а связанный сервер - . Приведенное сообщение об ошибке говорит о том, что используется соединение Named Pipes, и что SQL Server 7.0 не видит системы с SQL Server 6.5 в сети.
Для успешного выполнения распределенного запроса на обоих серверах должен работать компонент Named Pipes. Кроме того, пользователь, осуществляющий запрос, должен иметь право доступа к сервису NT Server, работающему на физической машине с TargetServer. При инсталляции SQL Server компонент Named Pipes устанавливается по умолчанию, поэтому мы предполагаем, что эта важная часть NetLibs установлена на обе системы, и причина проблемы не в ней.
Если причина не в Named Pipes, то в проблема, возможно, в профиле пользователя, от имени которого осуществляется запрос к TargetServer. Запрос осуществляется от имени пользователя, по регистрации которого на SourceServer был запущен сервис MSSQLServer. Таким образом мы можем сузить круг возможных источников проблемы до двух: либо MSSQLServer работает на SourceServer в пользовательском профиле LocalSystem, который не имеет права доступа к сети; либо MSSQLServer был запущен пользователем, не располагающим правом доступа к сервису NT Server, работающему на TargetServer.
В данном случае сервис MSSQLServer запущен в пользовательском профиле LocalSystem. Чтобы решить проблему, вам необходимо при загрузке войти в систему от имени пользователя, имеющего разрешение на доступ к удаленным машинам.
В: Я воспользовался входящим в состав SQL Server 7.0 мастером создания комплектов сервисов преобразования данных (Data Transformations Services, DTS). Для соединений я сохранил имена, предложенные мне по умолчанию, но я теперь хочу изменить их, придав им более описательный характер. Как это сделать?
О: DTS и мастер создания комплектов DTS - замечательные новые функции SQL Server. Однако они обладают рядом мелких, но неприятных недостатков, таких как невозможность переименовать соединения. К счастью, это ограничение можно обойти.
Допустим, к примеру, вы создали простой комплект, который экспортирует данные из таблицы authors в базе данных pubs в двумерный файл, и вы не снабдили комплект документацией. Для простоты вы сохранили имена соединений, предложенные вам по умолчанию источником OLE DB, на котором они основаны. Другими словами, эти имена практически ничего не говорят об источнике соединения. Когда вы завершили работу над комплектом, ваш начальник потребовал от вас, чтобы названия соединений соответствовали принятым в компании правилам назначения имен.
Экран 1: Создание нового соединения
Решить задачу, казалось бы, просто - переименовать соединение. Однако мастер создания комплектов DTS этого сделать не позволяет. Самый простой выход из положения - воспользоваться следующим примером для создания нового соединения.
Вначале щелкните правой клавишей мыши на названии соединения и выберите Properties. Затем в показанном на экране 1 диалоге Connection Properties выберите New Connection. Введите в текстовом окне New Connection новое название соединения и нажмите Оk. Система спросит "хотите ли вы, чтобы заданные вами ранее преобразования при создании данного соединения были сброшены?" Нажмите No. Нажмите No еще раз в ответ на следующий вопрос и процесс переименования будет завершен.
О: SQL Server 2000 позволяет хранить дополнительные свойства многих типов объектов базы данных. Дополнительные свойства определяются пользователем и имеют тип SQL_ VARIANT. Программисты, работающие с VB, знакомы с типом данных VARIANT. Подобно типу данных в VB, SQL_VARIANT позволяет хранить различные типы данных в поле, параметре или переменной. Каждый экземпляр столбца SQL_VARIANT состоит из двух частей: собственно данные и метаданные, описывающие значение (например базовый тип данных поля, максимальный размер, точность и collation - сопоставление). Для получения мета-данных экземпляра SQL_VARIANT можно использовать функцию SQL_VARIANT_ PROPERTY.
Например, чтобы сохранить описание столбца au_id в таблице authors в базе данных pubs, нужно щелкнуть правой кнопкой мыши на имени столбца в окне Object Browser (новый интерфейс Query Analyzer), затем выбрать Extended Properties. Теперь следует добавить новое свойство WhatAmI и внести значение "I am the author id column!!!". То же самое можно сделать, используя процедуру sp_addextendedproperty:
sp_addextendedproperty 'WhatAmI2','This is a new property value','user', dbo, 'table', authors, 'column', au_id
Затем можно применить стандартный оператор SELECT с новой функцией fn_listextendedproperty, чтобы извлечь информацию:
SELECT * FROM ::fn_listextendedproperty(NULL, 'user', 'dbo','table','authors', 'column', default)
Objtype objname name value COLUMN au_id WhatAmI I am the author id column!!! COLUMN au_id WhatAmI2 This is a new property value SELECT * FROM ::fn_listextendedproperty(NULL,'user','dbo','table', 'authors', 'column',default)
В: Я имею сертификат MCSE и собираюсь получить сертификат администратора БД (MCDBA). Я знаю, что для развертывания приложений SQL Server недостаточно прочитать специальную литературу. Тем не менее могли бы Вы рекомендовать какие-то источники информации для начинающих? У меня уже есть "Microsoft SQL Server 7.0 System Administration Training Kit" (Microsoft Press, 1999) и William Robert Stanek's "Microsoft SQL Server 7.0 Administrator's Pocket Consultant" (Microsoft Press, 1999).
О: Лучше всего разработать приложение (или прототип), которое решает реальные задачи. Советую придумать приложение для себя или создать базу данных для небольшой организации.
Чтобы приобрести дополнительный опыт, импортируйте необработанные статистические данные в новую базу данных MS SQL или OLAP куб и представьте, что Вы - конечный пользователь, который хочет проанализировать данные. Изучите OLAP и приложение Food Mart. Можно поэкспериментировать с приложением "Duwamish" - его Вы найдете в Microsoft Developer Network (MSDN). Установите и исследуйте его в целом и покомпонентно, пересоберите. Более полную информацию и примеры Вы найдете на сайте Microsoft: и .
Помимо этого, стоит присоединиться к группе новостей news://msnews.microsoft.com/microsoft.public.msdn.duwamish, а также посмотреть новые примеры приложений - Fitch и Mather Stocks на сайте
В: Я писал хранимую процедуру и столкнулся с проблемой при использовании оператора TOP с локальной переменной вместо фиксированного числа. Например, когда я пишу:
DECLARE @Counter INT SELECT @Counter=5 SELECT TOP @Counter * FROM <mytable>
процедура возвращает ошибку. Но строка
SELECT TOP 5 * FROM <mytable>
работает. Что делать в таком случае?
О: Согласно SQL Server Books Online (BOL), можно использовать N в разделе TOP, чтобы ограничить количество строк, возвращаемых в результате исполнения SELECT запроса. Но N должно быть числом типа integer. В SQL Server 7.0 язык Transact SQL (T-SQL) не позволяет задействовать локальную переменную в разделе TOP N, даже если та имеет тип integer. Локальные и глобальные переменные можно идентифицировать с помощью префиксов: @ - для локальных и @@ - для глобальных переменных. Можно также использовать оператор SET, чтобы присвоить значение локальной переменной, или же определить локальные переменные, ссылаясь на них в списке полей оператора SELECT. Следующий пример, вероятно, поможет решить Вашу задачу:
DECLARE @counter INT DECLARE @sql VARCHAR(255) SET @Counter=5 SELECT @sql = <SELECT TOP < + str(@counter) + < * FROM authors> EXEC (@sql)
Это T-SQL-предложение динамически строит и выполняет строку T-SQL, возвращающую первые N строк запроса. Динамический T- SQL позволяет создавать такие команды T-SQL, которые невозможно применять при использовании стандартных T-SQL методов.
В: Как использовать функции, определяемые пользователем (UDF) с SQL Server 2000?
О: Использование UDF в хранимых процедурах позволяет переместить дополнительную бизнес-логику приложения на сервер. При разработке SQL Server 2000 специалисты Microsoft собирались включать поддержку для независимых от языка UDF (например, UDF, записанное в VBScript). К сожалению, в силу существующих программных ограничений, UDFs пока можно создавать лишь на языке SQL (T-SQL). Приведу пример из SQL Server 2000 Books Online (BOL), показывающий, как используется типичная UDF, написанная на T-SQL:
CREATE FUNCTION CubicVolume -- Входные размеры в сантиметрах. (@CubeLength decimal(4,1), @CubeWidth decimal(4,1), @CubeHeight decimal(4,1) ) RETURNS decimal(12,3) - Cubic centimeters. AS BEGIN RETURN ( @CubeLength * @CubeWidth * @CubeHeight ) END
Данный сценарий создает функцию (хранимую на сервере), которая может использоваться в любом контексте, где SQL Server допускает применение десятичного выражения.
Карен Уоттерсон
независимый журналист, редактор и консультант по клиент-серверным системам и хранилищам данных. Ей можно написать по адресу: .
Брайан Моран
президент группы пользователей и директор по технологиям СУБД Spectrum Technology Group. Имеет сертификаты MCSE, MCSD и MCT. Ему можно написать по адресу: .
Sqlservqa_01.shtml
ЭКРАН 1. Создание файла ScriptPkg.exe в VB.
Microsoft SQL Server OLAP Services. Ознакомительные упражнения.
| SQL7Set.exe | 356 Кбайт | Обучение установке SQL-сервера. |
| FoodMart.exe | 4,9 Мбайт | Установка примера базы данных English Query. |
| DataTraS.exe | 283 Кбайт | Обучение работе с Data Transformation Services (DTS) для to перемещения данных из одной базы в другую. |
| LAPServ.exe | 650 Кбайт | Обучение возможностям MSOLAP 7.0 через построение многомерной базы данных, которую затем можно использовать для быстрого анализа больших массивов данных. |