Анонимные строчные типы
Анонимный строчный тип2) – это конструктор типов ROW, позволяющий производить безымянные типы строк (кортежей). Любой возможный строчный тип получается путем использования конструктора ROW. При определении столбца, значения которого должны принадлежать некоторому строчному типу, используется конструкция ROW (fld1, fld2, ѕ, fldn ), где каждый элемент fldi, определяющий поле строчного типа, задается в виде тройки fldname, fldtype, fldoptions. Подэлемент fldname задает имя соответствующего поля строчного типа. Подэлемент fldtype специфицирует тип данных этого поля. В качестве типа данных поля строчного типа можно использовать любой допустимый в SQL тип данных, включая типы коллекций, определяемые пользователями типы и другие строчные типы. Необязательный подэлемент fldoptions может задаваться для указания применяемого по умолчанию порядка сортировки, если соответствующий подэлемент fldtype указывает на тип символьных строк, а также должен задаваться, если fldtype указывает на ссылочный тип (см. ниже). Степенью строчного типа называется число его полей.
Анонимные строчные типы
Анонимный строчный тип16) – это конструктор типов ROW, позволяющий производить безымянные типы строк (кортежей). Любой возможный строчный тип получается путем использования конструктора ROW. При определении столбца, значения которого должны принадлежать некоторому строчному типу, используется конструкция ROW (fld1, fld2, ѕ, fldn ), где каждый элемент fldi, определяющий поле строчного типа, задается в виде тройки fldname, fldtype, fldoptions. Подэлемент fldname задает имя соответствующего поля строчного типа. Подэлемент fldtype специфицирует тип данных этого поля. В качестве типа данных поля строчного типа можно использовать любой допустимый в SQL тип данных, включая типы коллекций, определяемые пользователями типы и другие строчные типы. Необязательный подэлемент fldoptions может задаваться для указания применяемого по умолчанию порядка сортировки, если соответствующий подэлемент fldtype указывает на тип символьных строк, а также должен задаваться, если fldtype указывает на ссылочный тип (см. ниже). Степенью строчного типа называется число его полей.
Булевский тип
При определении столбца булевского типа указывается просто спецификация BOOLEAN. Булевский тип состоит из трех значений: true, false и unknown (соответствующие литералы обозначаются TRUE, FALSE и UNKNOWN). Поддерживается возможность построения булевских выражений, которые вычисляются в трехзначной логике. Таблицы истинности основных логических операций показаны на рис. 11.2.
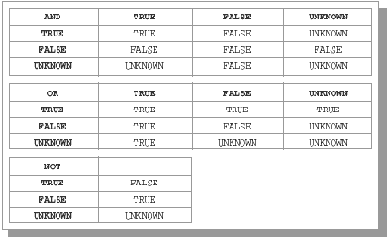
Рис. 11.2. Таблицы истинности основных логических операций в трехзначной логике
Булевский тип
При определении столбца булевского типа указывается просто спецификация BOOLEAN. Булевский тип состоит из трех значений: true, false и unknown (соответствующие литералы обозначаются TRUE, FALSE и UNKNOWN). Поддерживается возможность построения булевских выражений, которые вычисляются в трехзначной логике. Таблицы истинности основных логических операций показаны на рис. 11.2.
Рис. 11.2. Таблицы истинности основных логических операций в трехзначной логике
В этом абзаце применяется терминология,
| В этом абзаце применяется терминология, которая использовалась в публикациях, посвященных System R. |
| Закрыть окно |
Как это ни странно, компания
| Как это ни странно, компания IBM, имевшая уникальный и положительный опыт реализации экспериментальной реляционной СУБД System R, не стала первой компанией, выпустившей на рынок коммерческую реляционную СУБД. Компанию IBM опередила на два года незадолго до того образованная компания Oracle, выпустившая свою первую систему в 1979 г. Современные эксперты по разному объясняют причины этой «заторможенности» IBM, но, по всей видимости, основная причина кроется в традиционном консерватизме руководства компании. |
| Закрыть окно |
одной из выигрышных черт SQL
| Например, одной из выигрышных черт SQL System R являлось то, что в одной транзакции разрешалось комбинировать все возможные операторы SQL. Поскольку технически это обеспечить достаточно трудно, почти во всех сегодняшних SQL-ориентированных СУБД имеются ограничения на состав операторов, которые можно выполнять в одной транзакции. |
| Закрыть окно |
с точки зрения программистов приложений
| Это практически обесценивает стандарт с точки зрения программистов приложений баз данных, поскольку не дает возможности создавать приложения, не привязанные к особенностям конкретных СУБД. |
| Закрыть окно |
R нельзя не отметить то,
| Среди прочих достижений System R нельзя не отметить то, что в базах данных, управляемых этой СУБД, хранились как данные, так и метаданные – описатели отношений, их полей, представлений, ограничения целостности и т.д. Для хранения метаданных использовались специальные служебные отношения, которые стали называть отношениями-каталогами. Из отношений-каталогов можно было выбрать данные с помощью обычных средств языка SQL. Конечно, организация служебных данных – это вопрос реализации SQL, но этот вопрос непосредственно касается потенциальных пользователей SQL-ориентированных СУБД, и поэтому стандартизация представления пользователю отношений-каталогов (в стандарте SQL, информационной схемы базы данных) является исключительно важным делом. |
| Закрыть окно |
К сожалению, приходится использовать термин
| К сожалению, приходится использовать термин строка в двух смыслах: строка таблицы (table row) и символьная или битовая строка (character or bit string). Постараемся обеспечить правильное понимание смысла термина в контексте его использования. |
| Закрыть окно |
Спецификация предопределенного типа данных битовых
| Спецификация предопределенного типа данных битовых строк была удалена в стандарте SQL:2003. Но поскольку эта спецификация повилась только в SQL:1999, мы сочли уместным оставить в курсе обсуждение этого типа данных. |
| Закрыть окно |
в стандарте SQL не определяется
| Следует подчеркнуть, что в стандарте SQL не определяется число байт, занимаемых при хранении в памяти значений целых типов. Не следует думать, что в SQL для хранения значения типа INTEGER требуется четыре байта, а SMALLINT требует двух байтов. |
| Закрыть окно |
в стандарт языка) можно определить
| В контексте локализации SQL-ориентированной СУБД (средства локализации входят в стандарт языка) можно определить еще три типа символьных строк – NATIONAL CHARACTER, NATIONAL CHARACTER VARYING и NATIONAL CHARACTER LARGE OBJECT. Аспекты интернационализации и локализации составляют отдельное измерение языка и не обсуждаются в данном курсе. |
| Закрыть окно |
Именно пробелами,
| Именно пробелами, а не «пустыми» символами! |
| Закрыть окно |
Максимально допустимая длина строк постоянного
| Максимально допустимая длина строк постоянного и переменного размера (значение параметра x) определяется в реализации. |
| Закрыть окно |
z могут быть очень большими,
| Поскольку значения z могут быть очень большими, допускается сокращенная форма их задания в виде nK, nM и nG, где n – положительное целое число, а K, M и G означают кило, мега и гига соответственно. |
| Закрыть окно |
В литерале BLOB всегда должно
| В литерале BLOB всегда должно содержаться четное число шестнадцатиричных цифр. |
| Закрыть окно |
на практике такие ограничения устанавливаются
| Конечно, на практике такие ограничения устанавливаются в документации конкретной используемой СУБД, либо даже администратором конкретной базы данных. |
| Закрыть окно |
используется термин anonymous row
| В тексте стандарта SQL: 1999 используется термин anonymous row type. Следуя соглашениям предыдущего пункта, мы должны были бы использовать термин анонимные типы строк. Но тогда уж точно возникла бы путаница с типами символьных строк. Конечно, можно было бы радикально отказаться от использования термина строка таблицы и вернуться к кортежам отношений. Но, к сожалению, этого сделать нельзя, покольку в SQL таблицы – это не совсем (а иногда и совсем не) отношения, а строки таблиц – не совсем (совсем не) кортежи. |
| Закрыть окно |
Соответствующие определения сохраняются как часть
| Соответствующие определения сохраняются как часть метаданных базы данных (другими словами, являются частью схемы базы данных). |
| Закрыть окно |
A использовались только те типы,
| Требуется, чтобы в определении структурного типа A использовались только те типы, которые были определены ранее. |
| Закрыть окно |
с этого места мы будем
| Начиная с этого места мы будем приводить более или менее точный синтаксис конструкций языка SQL (не злоупотребляя излишествами). Без этого текст был бы менее точным и более объемным. Прописными буквами показываются «терминалы» – ключевые слова языка SQL. |
| Закрыть окно |
с именем объекта базы данных.
| Здесь мы в первый раз сталкиваемся с именем объекта базы данных. Не будем углублять ся в детали, но в общем случае имена объектов SQL-ориентированных баз данных имеют вид имя_каталога.имя_схемы.имя_объекта. Этот подход к именованию объектов базы данных позволяет независимо создавать объекты в разных схемах, не заботясь о том, чтобы эти объекты имели разные простые имена. При использовании в операторе SQL простого имени объекта система должна автоматически уточнить это имя, исходя из идентификатора пользователя, от имени которого выполняется оператор. |
| Закрыть окно |
в качестве значения по умолчанию
| Это значение будет использоваться в качестве значения по умолчанию для любого столбца, определенного на данном домене, для которого не определено собственное значение по умолчанию (см. следующую лекцию). |
| Закрыть окно |
в данной синтаксической конструкции должен
| { element1, | element2, |…| elementn } означает, что в данной синтаксической конструкции должен присутствовать один и только один elementi. |
| Закрыть окно |
в тот момент, когда требуется
| Значение niladic_function «вычисляется» в тот момент, когда требуется значение по умолчанию (обычно при вставке в таблицу новой строки, значение соответствующего столбца которой явно не указано). Смысл CURRENT_DATE, CURRENT_TIME и CURRENT_TIMESTAMP очевиден. USER (или, что то же, CURRENT USER), SESSION_USER и SYSTEM_USER задают идентификатор пользователя, от имени которого выполняется текущая транзакция, текущая сессия, и идентификатор операционной системы, в которой работает пользователь, соответственно. В стандарте не определяется представление этих идентификаторов, но в реализациях они обычно представляются в виде символьных строк. |
| Закрыть окно |
Более подробно мы обсудим допустимые
| Более подробно мы обсудим допустимые в SQL виды условных выражений в следующих лекциях. |
| Закрыть окно |
Истинно целые типы
Тип INTEGER. Тип служит для представления целых чисел. Точность чисел (число сохраняемых бит) определяется в реализации. При определении столбца данного типа достаточно указать просто INTEGER.Тип SMALLINT. Тип также служит для представления целых чисел. Точность определяется в реализации, но она не должна быть больше точности типа INTEGER. При определении столбца указывается просто SMALLINT.3)Литералы типов целых чисел представляются в виде строк символов, изображающих десятичные числа; в начале строки могут присутствовать символы «+» или «-» (если символ знака отсутствует, подразумевается «+»). Примеры литералов типов INTEGER и SMALLINT: 1826545, 876.
Истинно целые типы
Тип INTEGER. Тип служит для представления целых чисел. Точность чисел (число сохраняемых бит) определяется в реализации. При определении столбца данного типа достаточно указать просто INTEGER.Тип SMALLINT. Тип также служит для представления целых чисел. Точность определяется в реализации, но она не должна быть больше точности типа INTEGER. При определении столбца указывается просто SMALLINT.9)Литералы типов целых чисел представляются в виде строк символов, изображающих десятичные числа; в начале строки могут присутствовать символы «+» или «-» (если символ знака отсутствует, подразумевается «+»). Примеры литералов типов INTEGER и SMALLINT: 1826545, 876.
Изменение определения домена
Для изменения характеристик ранее определенного домена используется оператор SQL ALTER DOMAIN. Синтаксис этого оператора выглядит следующим образом:
domain_alternation ::= ALTER DOMAIN domain_name domain_alternation_action domain_alternation_action ::= domain_default_alternation_action | domain_constraint_alternation_action
Как видно из синтаксических правил, при изменении определения домена можно выполнить действие по изменению раздела значения по умолчанию либо изменить ограничение домена. Для первого варианта действует следующий синтаксис:
domain_default_alternation_action ::= SET default_definition | DROP DEFAULT
В случае установки нового значения по умолчанию (SET) это значение автоматически применяется ко всем столбцам, определенным на данном домене. Более точно, это значение становится новым значением по умолчанию. Операция не оказывает влияния на состояние существующих строк таблиц базы данных. В случае отмены раздела значения по умолчанию в определении домена (DROP) существовашее значение домена по умолчанию становится значением по умолчанию каждого столбца, который определен на данном домене и для которого не специфицировано собственное значение по умолчанию.
Действие по изменению ограничения домена определяется следующим синтаксисом:
domain_constraint_alternation_action ::= ADD domain_constraint_definition | DROP CONSTRAINT constraint_name
Действие по добавлению нового определения ограничения домена (ADD) приводит к тому, что новое условие добавляется через AND к существующему ограничению домена. Если к моменту выполнения соответствующего оператора ALTER DOMAIN существуют столбцы некоторых таблиц, текущие значения которых противоречат новому ограничению, то СУБД должна отвергнуть этот оператор ALTER DOMAIN. Действие по отмене ограничения домена (DROP) приводит к исчезновению соответствующей части общего ограничения соответствующего домена, что, естественно, не влияет на существующие значения столбцов имеющихся таблиц.
Изменение определения домена
Для изменения характеристик ранее определенного домена используется оператор SQL ALTER DOMAIN. Синтаксис этого оператора выглядит следующим образом:
domain_alternation ::= ALTER DOMAIN domain_name domain_alternation_action domain_alternation_action ::= domain_default_alternation_action | domain_constraint_alternation_action
Как видно из синтаксических правил, при изменении определения домена можно выполнить действие по изменению раздела значения по умолчанию либо изменить ограничение домена. Для первого варианта действует следующий синтаксис:
domain_default_alternation_action ::= SET default_definition | DROP DEFAULT
В случае установки нового значения по умолчанию (SET) это значение автоматически применяется ко всем столбцам, определенным на данном домене. Более точно, это значение становится новым значением по умолчанию. Операция не оказывает влияния на состояние существующих строк таблиц базы данных. В случае отмены раздела значения по умолчанию в определении домена (DROP) существовашее значение домена по умолчанию становится значением по умолчанию каждого столбца, который определен на данном домене и для которого не специфицировано собственное значение по умолчанию.
Действие по изменению ограничения домена определяется следующим синтаксисом:
domain_constraint_alternation_action ::= ADD domain_constraint_definition | DROP CONSTRAINT constraint_name
Действие по добавлению нового определения ограничения домена (ADD) приводит к тому, что новое условие добавляется через AND к существующему ограничению домена. Если к моменту выполнения соответствующего оператора ALTER DOMAIN существуют столбцы некоторых таблиц, текущие значения которых противоречат новому ограничению, то СУБД должна отвергнуть этот оператор ALTER DOMAIN. Действие по отмене ограничения домена (DROP) приводит к исчезновению соответствующей части общего ограничения соответствующего домена, что, естественно, не влияет на существующие значения столбцов имеющихся таблиц.
Явные преобразования типов или доменов и оператор CAST
Неявные преобразования типов не всегда удобны, недостаточно гибки и иногда могут вызывать ошибки. В SQL существует специальный оператор CAST, с помощью которого можно явно преобразовывать типы или домены в пределах допускаемых преобразований. Конструкция имеет следующий синтаксис:
CAST ({scalar-expression | NULL } AS {data_type | domain_name})
Оператор преобразует значение заданного скалярного выражения к указанному типу или к базовому типу указанного домена. Результатом применения оператора CAST к неопределенному значению является неопределенное значение. Для значений, отличных от неопределенных, в стандарте приводятся подробные правила выполнения преобразований, которые интуитивно понятны.
Поясним действие оператора CAST в наиболее важных случаях. Примем следующие обозначения типов данных:
EN – точные числовые типы (Exact Numeric)
AN – приблизительные числовые типы (Approximate Numeric)
C – типы символьных строк (Character)
FC – типы символьных строк постоянной длины (Fixed-length Character)
VC – типы символьных строк переменной длины (Variable-length Character)
B – типы битовых строк (Bit String)
FB – типы битовых строк постоянной длины (Fixed-length Bit String)
VB – типы битовых строк переменной длины (Variable-length Bit String)
D – тип Date
T – типы Time
TS – типы Timestamp
YM – типы Interval Year-Month
DT – типы Interval Day-Time
Пусть TD – это тип данных, к которому производится преобразование, а SD – тип данных операнда. Тогда допустимы следующие комбинации («да» означает безусловную допустимость, «нет» – безусловную недопустимость и «?» – допустимость с оговорками).
| Да | Да | Да | Да | Нет | Нет | Нет | Нет | Нет | ? | ? |
| Да | Да | Да | Да | Нет | Нет | Нет | Нет | Нет | Нет | Нет |
| Да | Да | ? | ? | Да | Да | Да | Да | Да | Да | Да |
| Нет | Нет | Да | Да | Да | Да | Нет | Нет | Нет | Нет | Нет |
| Нет | Нет | Да | Да | Нет | Нет | Да | Нет | Да | Нет | Нет |
| Нет | Нет | Да | Да | Нет | Нет | Нет | Да | Да | Нет | Нет |
| Нет | Нет | Да | Да | Нет | Нет | Да | Да | Да | Нет | Нет |
| ? | Нет | Да | Да | Нет | Нет | Нет | Нет | Нет | Да | Нет |
| ? | Нет | Да | Да | Нет | Нет | Нет | Нет | Нет | Нет | Да |
По поводу ячеек таблицы, содержащих знак вопроса, необходимо сделать несколько оговорок:
если TD – интервал и SD – тип точных чисел, то TD должен содержать единственное поле даты-времени; если TD – тип точных чисел и SD – интервал, то SD должен содержать единственное поле даты-времени; если SD – тип символьных строк и TD – тип символьных строк постоянной или переменной длины, то набор символов SD и TD должен быть одним и тем же.
Явные преобразования типов или доменов и оператор CAST
Неявные преобразования типов не всегда удобны, недостаточно гибки и иногда могут вызывать ошибки. В SQL существует специальный оператор CAST, с помощью которого можно явно преобразовывать типы или домены в пределах допускаемых преобразований. Конструкция имеет следующий синтаксис:
CAST ({scalar-expression | NULL } AS {data_type | domain_name})
Оператор преобразует значение заданного скалярного выражения к указанному типу или к базовому типу указанного домена. Результатом применения оператора CAST к неопределенному значению является неопределенное значение. Для значений, отличных от неопределенных, в стандарте приводятся подробные правила выполнения преобразований, которые интуитивно понятны.
Поясним действие оператора CAST в наиболее важных случаях. Примем следующие обозначения типов данных:
EN – точные числовые типы (Exact Numeric)
AN – приблизительные числовые типы (Approximate Numeric)
C – типы символьных строк (Character)
FC – типы символьных строк постоянной длины (Fixed-length Character)
VC – типы символьных строк переменной длины (Variable-length Character)
B – типы битовых строк (Bit String)
FB – типы битовых строк постоянной длины (Fixed-length Bit String)
VB – типы битовых строк переменной длины (Variable-length Bit String)
D – тип Date
T – типы Time
TS – типы Timestamp
YM – типы Interval Year-Month
DT – типы Interval Day-Time
Пусть TD – это тип данных, к которому производится преобразование, а SD – тип данных операнда. Тогда допустимы следующие комбинации («да» означает безусловную допустимость, «нет» – безусловную недопустимость и «?» – допустимость с оговорками).
| Да | Да | Да | Да | Нет | Нет | Нет | Нет | Нет | ? | ? |
| Да | Да | Да | Да | Нет | Нет | Нет | Нет | Нет | Нет | Нет |
| Да | Да | ? | ? | Да | Да | Да | Да | Да | Да | Да |
| Нет | Нет | Да | Да | Да | Да | Нет | Нет | Нет | Нет | Нет |
| Нет | Нет | Да | Да | Нет | Нет | Да | Нет | Да | Нет | Нет |
| Нет | Нет | Да | Да | Нет | Нет | Нет | Да | Да | Нет | Нет |
| Нет | Нет | Да | Да | Нет | Нет | Да | Да | Да | Нет | Нет |
| ? | Нет | Да | Да | Нет | Нет | Нет | Нет | Нет | Да | Нет |
| ? | Нет | Да | Да | Нет | Нет | Нет | Нет | Нет | Нет | Да |
По поводу ячеек таблицы, содержащих знак вопроса, необходимо сделать несколько оговорок:
если TD – интервал и SD – тип точных чисел, то TD должен содержать единственное поле даты-времени; если TD – тип точных чисел и SD – интервал, то SD должен содержать единственное поле даты-времени; если SD – тип символьных строк и TD – тип символьных строк постоянной или переменной длины, то набор символов SD и TD должен быть одним и тем же.
Краткая история языка SQL
Язык SQL, предназначенный для взаимодействия с базами данных, появился в середине 70-х гг. (первые публикации датируются 1974 г.) и был разработан в компании IBM в рамках проекта экспериментальной реляционной СУБД System R. Исходное название языка SEQUEL (Structured English Query Language) только частично отражало суть этого языка. Конечно, язык был ориентирован главным образом на удобную и понятную пользователям формулировку запросов к реляционным БД. Но, в действительности, он почти с самого начала являлся полным языком БД, обеспечивающим помимо средств формулирования запросов и манипулирования БД следующие возможности:
средства определения и манипулирования схемой БД; средства определения ограничений целостности и триггеров; средства определения представлений БД; средства определения структур физического уровня, поддерживающих эффективное выполнение запросов; средства авторизации доступа к отношениям и их полям1); средства определения точек сохранения транзакции, и выполнения фиксации и откатов транзакций.
В языке отсутствовали средства явной синхронизации доступа к объектам БД со стороны параллельно выполняемых транзакций: с самого начала предполагалось, что необходимую синхронизацию неявно выполняет СУБД.
В настоящее время язык SQL реализован во всех коммерческих реляционных СУБД и почти во всех СУБД, которые изначально основывались не на реляционном подходе. Все компании-производители провозглашают соответствие своей реализации стандарту SQL, и на самом деле реализованные диалекты SQL очень близки. Этого удалось добиться не сразу.
Наиболее близки к System R были две системы компании IBM – SQL/DS и DB22). Разработчики обеих систем использовали опыт проекта System R, а СУБД SQL/DS напрямую основывалась на программном коде System R. Отсюда предельная близость диалектов SQL, реализованных в этих системах, к SQL System R. Из SQL System R были удалены только те части, которые были недостаточно проработаны (например, точки сохранения) или реализация которых вызывала слишком большие технические трудности (например, ограничения целостности и триггеры). Можно назвать этот путь к коммерческой реализации SQL движением сверху вниз.
Другой подход применялся в таких системах, как Oracle, Informix и Sybase. Несмотря на различие в способах разработки систем, реализация SQL везде происходила «снизу вверх». В первых выпущенных на рынок версиях этих систем использовалось ограниченное подмножество SQL System R. В частности, в первой известной нам реализации SQL в СУБД Oracle в операторах выборки не допускалось использование вложенных подзапросов и отсутствовала возможность формулировки запросов с соединениями нескольких отношений.
Тем не менее, несмотря на эти ограничения и на очень слабую, на первых порах, эффективность СУБД, ориентация компаний на поддержку разных аппаратных платформ и заинтересованность пользователей в переходе к реляционным системам позволили компаниям добиться коммерческого успеха и приступить к совершенствованию своих реализаций. В текущих версиях Oracle, Informix, Sybase и Microsoft SQL Server поддерживаются достаточно мощные диалекты SQL, хотя реализация иногда вызывает сомнения.3)
Особенностью большинства современных коммерческих СУБД, затрудняющей сравнение существующих диалектов SQL, является отсутствие единообразного описания языка. Обычно описание разбросано по разным руководствам и перемешано с описанием специфических для данной системы языковых средств, не имеющих прямого отношения к SQL. Тем не менее можно сказать, что базовый набор операторов SQL, включающий операторы определения схемы БД, выборки и манипулирования данными, авторизации доступа к данным, поддержки встраивания SQL в языки программирования и операторы динамического SQL, в коммерческих реализациях устоялся и более или менее соответствует стандарту.
Деятельность по стандартизации языка SQL началась практически одновременно с появлением его первых коммерческих реализаций. В 1982 г. комитету по базам данных Американского национального института стандартов (ANSI) было поручено разработать спецификацию стандартного языка реляционных баз данных. Первый документ из числа имеющихся у автора проектов стандарта датирован октябрем 1985 г. и является уже не первым проектом стандарта ANSI. Стандарт был принят ANSI в 1986 г., а в 1987 г. одобрен Международной организацией по стандартизации (ISO). Этот стандарт принято называть SQL/86.
Понятно, что в качестве основы стандарта нельзя было использовать SQL System R. Во-первых, этот вариант языка не был должным образом технически проработан. Во-вторых, его слишком сложно было бы реализовать (кто знает, как бы сложилась судьба SQL, если бы все идеи проекта System R были реализованы полностью). Поэтому за основу был взят диалект языка SQL, сложившийся в IBM к началу 1980-х гг. В сущности, этот диалект представлял собой технически проработанное подмножество SQL System R.
К 1989 г. стандарт SQL/86 был несколько расширен, и был подготовлен и принят следующий стандарт, получивший название ANSI/ISO SQL/89. Анализ доступных документов показывает, что процесс стандартизации SQL происходил очень сложно с использованием не только научных доводов. В результате SQL/89 во многих частях имеет чрезвычайно общий характер и допускает очень широкое толкование. В этом стандарте полностью отсутствуют такие важные разделы, как манипулирование схемой БД и динамический SQL. Многие важные аспекты языка в соответствии со стандартом определяются в реализации.4)
Возможно, наиболее важными достижениями стандарта SQL/89 являются четкая стандартизация синтаксиса и семантики операторов выборки данных и манипулирования данными и фиксация средств ограничения целостности БД. Были специфицированы средства определения первичного и внешних ключей отношений и так называемых проверочных ограничений целостности, которые представляют собой подмножество немедленно проверяемых ограничений целостности SQL System R. Средства определения внешних ключей позволяют легко формулировать требования так называемой ссылочной целостности БД. Это распространенное в реляционных БД требование можно было сформулировать и на основе общего механизма ограничений целостности SQL System R, но формулировка на основе понятия внешнего ключа более проста и понятна.
Осознавая неполноту стандарта SQL, на фоне завершения разработки этого стандарта специалисты различных компаний начали работу над стандартом SQL2. Эта работа также длилась несколько лет, было выпущено множество проектов стандарта, пока наконец в марте 1992 г. не был принят окончательный проект стандарта (SQL/92). Этот стандарт существенно полнее стандарта SQL/89 и охватывает практически все аспекты, необходимые для реализации приложений: манипулирование схемой БД, управление транзакциями (появились точки сохранения) и сессиями (сессия – это последовательность транзакций, в пределах которой сохраняются временные отношения), подключения к БД, динамический SQL. Наконец, были стандартизованы отношения-каталоги БД, что вообще-то не связано непосредственно с языком, но очень сильно влияет на реализацию.5)
В 1995 г. стандарт был дополнен спецификацией интерфейса уровня вызова (Call-Level Interface – SQL/CLI). SQL/CLI представляет собой набор спецификаций интерфейсов процедур, вызовы которых позволяют выполнять динамически задаваемые операторы SQL. По сути дела, SQL/CLI представляет собой альтернативу динамическому SQL. Интерфейсы процедур определены для всех основных языков программирования: С, Ada, Pascal, PL/1 и т. д. Следует заметить, что стандарт SQL/CLI послужил основой для создания повсеместно распространенных сегодня интерфейсов ODBC (Open Database Connectivity) и JDBC (Java Database Connectivity).
В 1996 г. к стандарту SQL/92 был добавлен еще один компонент – SQL/PSM (Persistent Stored Modules). Основная цель этой спецификации состоит в том, чтобы стандартизировать способы определения и использования хранимых процедур, т. е. специальным образом оформленных программ, включающих операторы SQL, которые сохраняются в базе данных, могут вызываться приложениями и выполняются внутри СУБД.
Незадолго до завершения работ по определению стандарта SQL2 была начата разработка стандарта SQL3. Первоначально планировалось завершить проект в 1995 г. и включить в язык некоторые объектные возможности: определяемые пользователями типы данных, поддержку триггеров, поддержку темпоральных свойств данных и т. д. Реально работу над новым стандартом удалось частично завершить только в 1999 г., и по этой причине (а также в связи с проблемой 2000 года) стандарт получил название SQL:1999.
Приведем краткую характеристику текущего состояния стандарта SQL:1999 и перспектив его развития. Прежде всего, заметим, что каждый новый вариант стандарта языка SQL был существенно объемнее предыдущих версий. Так, если стандарт SQL/89 занимал около 600 страниц, то объем SQL/92 составлял на 300 с лишним страниц больше. Самые первые проекты SQL3 занимали около 1500 страниц. Это вполне естественно, потому что язык усложняется, а его спецификации становятся более детальными и точными. Но разработчики SQL3 пришли к выводу, что при таких объемах стандарта вероятность его принятия и последующей успешной поддержки заметно уменьшается. Поэтому было принято решение разбить стандарт на относительно независимые части, которые можно было бы разрабатывать и поддерживать по отдельности.
В 1999 г. были приняты пять первых частей стандарта SQL:1999. Первая часть (SQL/Framework) посвящена описанию концептуальной структуры стандарта. В этой части приводится развернутая аннотация следующих четырех частей и формулируются требования к реализациям, претендующим на соответствие стандарту.
Вторая часть SQL:1999 (SQL/Foundation) образует базис стандарта. Вводится система типов языка, формулируются правила определения функциональных зависимостей и возможных ключей, определяются синтаксис и семантика основных операторов SQL:
операторов определения и манипулирования схемой базы данных;операторов манипулирования данными;операторов управления транзакциями;операторов управления подключениями к базе данных и т. д.
Краткая история языка SQL
Язык SQL, предназначенный для взаимодействия с базами данных, появился в середине 70-х гг. (первые публикации датируются 1974 г.) и был разработан в компании IBM в рамках проекта экспериментальной реляционной СУБД System R. Исходное название языка SEQUEL (Structured English Query Language) только частично отражало суть этого языка. Конечно, язык был ориентирован главным образом на удобную и понятную пользователям формулировку запросов к реляционным БД. Но, в действительности, он почти с самого начала являлся полным языком БД, обеспечивающим помимо средств формулирования запросов и манипулирования БД следующие возможности:
средства определения и манипулирования схемой БД; средства определения ограничений целостности и триггеров; средства определения представлений БД; средства определения структур физического уровня, поддерживающих эффективное выполнение запросов; средства авторизации доступа к отношениям и их полям1); средства определения точек сохранения транзакции, и выполнения фиксации и откатов транзакций.
В языке отсутствовали средства явной синхронизации доступа к объектам БД со стороны параллельно выполняемых транзакций: с самого начала предполагалось, что необходимую синхронизацию неявно выполняет СУБД.
В настоящее время язык SQL реализован во всех коммерческих реляционных СУБД и почти во всех СУБД, которые изначально основывались не на реляционном подходе. Все компании-производители провозглашают соответствие своей реализации стандарту SQL, и на самом деле реализованные диалекты SQL очень близки. Этого удалось добиться не сразу.
Наиболее близки к System R были две системы компании IBM – SQL/DS и DB22). Разработчики обеих систем использовали опыт проекта System R, а СУБД SQL/DS напрямую основывалась на программном коде System R. Отсюда предельная близость диалектов SQL, реализованных в этих системах, к SQL System R. Из SQL System R были удалены только те части, которые были недостаточно проработаны (например, точки сохранения) или реализация которых вызывала слишком большие технические трудности (например, ограничения целостности и триггеры). Можно назвать этот путь к коммерческой реализации SQL движением сверху вниз.
Другой подход применялся в таких системах, как Oracle, Informix и Sybase. Несмотря на различие в способах разработки систем, реализация SQL везде происходила «снизу вверх». В первых выпущенных на рынок версиях этих систем использовалось ограниченное подмножество SQL System R. В частности, в первой известной нам реализации SQL в СУБД Oracle в операторах выборки не допускалось использование вложенных подзапросов и отсутствовала возможность формулировки запросов с соединениями нескольких отношений.
Тем не менее, несмотря на эти ограничения и на очень слабую, на первых порах, эффективность СУБД, ориентация компаний на поддержку разных аппаратных платформ и заинтересованность пользователей в переходе к реляционным системам позволили компаниям добиться коммерческого успеха и приступить к совершенствованию своих реализаций. В текущих версиях Oracle, Informix, Sybase и Microsoft SQL Server поддерживаются достаточно мощные диалекты SQL, хотя реализация иногда вызывает сомнения.3)
Особенностью большинства современных коммерческих СУБД, затрудняющей сравнение существующих диалектов SQL, является отсутствие единообразного описания языка. Обычно описание разбросано по разным руководствам и перемешано с описанием специфических для данной системы языковых средств, не имеющих прямого отношения к SQL. Тем не менее можно сказать, что базовый набор операторов SQL, включающий операторы определения схемы БД, выборки и манипулирования данными, авторизации доступа к данным, поддержки встраивания SQL в языки программирования и операторы динамического SQL, в коммерческих реализациях устоялся и более или менее соответствует стандарту.
Деятельность по стандартизации языка SQL началась практически одновременно с появлением его первых коммерческих реализаций. В 1982 г. комитету по базам данных Американского национального института стандартов (ANSI) было поручено разработать спецификацию стандартного языка реляционных баз данных. Первый документ из числа имеющихся у автора проектов стандарта датирован октябрем 1985 г. и является уже не первым проектом стандарта ANSI. Стандарт был принят ANSI в 1986 г., а в 1987 г. одобрен Международной организацией по стандартизации (ISO). Этот стандарт принято называть SQL/86.
Понятно, что в качестве основы стандарта нельзя было использовать SQL System R. Во-первых, этот вариант языка не был должным образом технически проработан. Во-вторых, его слишком сложно было бы реализовать (кто знает, как бы сложилась судьба SQL, если бы все идеи проекта System R были реализованы полностью). Поэтому за основу был взят диалект языка SQL, сложившийся в IBM к началу 1980-х гг. В сущности, этот диалект представлял собой технически проработанное подмножество SQL System R.
К 1989 г. стандарт SQL/86 был несколько расширен, и был подготовлен и принят следующий стандарт, получивший название ANSI/ISO SQL/89. Анализ доступных документов показывает, что процесс стандартизации SQL происходил очень сложно с использованием не только научных доводов. В результате SQL/89 во многих частях имеет чрезвычайно общий характер и допускает очень широкое толкование. В этом стандарте полностью отсутствуют такие важные разделы, как манипулирование схемой БД и динамический SQL. Многие важные аспекты языка в соответствии со стандартом определяются в реализации.4)
Возможно, наиболее важными достижениями стандарта SQL/89 являются четкая стандартизация синтаксиса и семантики операторов выборки данных и манипулирования данными и фиксация средств ограничения целостности БД. Были специфицированы средства определения первичного и внешних ключей отношений и так называемых проверочных ограничений целостности, которые представляют собой подмножество немедленно проверяемых ограничений целостности SQL System R. Средства определения внешних ключей позволяют легко формулировать требования так называемой ссылочной целостности БД. Это распространенное в реляционных БД требование можно было сформулировать и на основе общего механизма ограничений целостности SQL System R, но формулировка на основе понятия внешнего ключа более проста и понятна.
Осознавая неполноту стандарта SQL, на фоне завершения разработки этого стандарта специалисты различных компаний начали работу над стандартом SQL2. Эта работа также длилась несколько лет, было выпущено множество проектов стандарта, пока наконец в марте 1992 г. не был принят окончательный проект стандарта (SQL/92). Этот стандарт существенно полнее стандарта SQL/89 и охватывает практически все аспекты, необходимые для реализации приложений: манипулирование схемой БД, управление транзакциями (появились точки сохранения) и сессиями (сессия – это последовательность транзакций, в пределах которой сохраняются временные отношения), подключения к БД, динамический SQL. Наконец, были стандартизованы отношения-каталоги БД, что вообще-то не связано непосредственно с языком, но очень сильно влияет на реализацию.5)
В 1995 г. стандарт был дополнен спецификацией интерфейса уровня вызова (Call-Level Interface – SQL/CLI). SQL/CLI представляет собой набор спецификаций интерфейсов процедур, вызовы которых позволяют выполнять динамически задаваемые операторы SQL. По сути дела, SQL/CLI представляет собой альтернативу динамическому SQL. Интерфейсы процедур определены для всех основных языков программирования: С, Ada, Pascal, PL/1 и т. д. Следует заметить, что стандарт SQL/CLI послужил основой для создания повсеместно распространенных сегодня интерфейсов ODBC (Open Database Connectivity) и JDBC (Java Database Connectivity).
В 1996 г. к стандарту SQL/92 был добавлен еще один компонент – SQL/PSM (Persistent Stored Modules). Основная цель этой спецификации состоит в том, чтобы стандартизировать способы определения и использования хранимых процедур, т. е. специальным образом оформленных программ, включающих операторы SQL, которые сохраняются в базе данных, могут вызываться приложениями и выполняются внутри СУБД.
Незадолго до завершения работ по определению стандарта SQL2 была начата разработка стандарта SQL3. Первоначально планировалось завершить проект в 1995 г. и включить в язык некоторые объектные возможности: определяемые пользователями типы данных, поддержку триггеров, поддержку темпоральных свойств данных и т. д. Реально работу над новым стандартом удалось частично завершить только в 1999 г., и по этой причине (а также в связи с проблемой 2000 года) стандарт получил название SQL:1999.
Приведем краткую характеристику текущего состояния стандарта SQL:1999 и перспектив его развития. Прежде всего, заметим, что каждый новый вариант стандарта языка SQL был существенно объемнее предыдущих версий. Так, если стандарт SQL/89 занимал около 600 страниц, то объем SQL/92 составлял на 300 с лишним страниц больше. Самые первые проекты SQL3 занимали около 1500 страниц. Это вполне естественно, потому что язык усложняется, а его спецификации становятся более детальными и точными. Но разработчики SQL3 пришли к выводу, что при таких объемах стандарта вероятность его принятия и последующей успешной поддержки заметно уменьшается. Поэтому было принято решение разбить стандарт на относительно независимые части, которые можно было бы разрабатывать и поддерживать по отдельности.
В 1999 г. были приняты пять первых частей стандарта SQL:1999. Первая часть (SQL/Framework) посвящена описанию концептуальной структуры стандарта. В этой части приводится развернутая аннотация следующих четырех частей и формулируются требования к реализациям, претендующим на соответствие стандарту.
Вторая часть SQL:1999 (SQL/Foundation) образует базис стандарта. Вводится система типов языка, формулируются правила определения функциональных зависимостей и возможных ключей, определяются синтаксис и семантика основных операторов SQL:
операторов определения и манипулирования схемой базы данных;операторов манипулирования данными;операторов управления транзакциями;операторов управления подключениями к базе данных и т. д.
Третью часть занимает уточненная по
Третью часть занимает уточненная по сравнению с SQL/92 спецификация SQL/CLI. В четвертой части специфицируется SQL/PSM – синтаксис и семантика языка определения хранимых процедур. Наконец, в пятой части – SQL/Bindings – определяются правила связывания SQL для стандартных версий языков программирования FORTRAN, COBOL, PL/1, Pascal, Ada, C и MUMPS.
В стандарт SQL:1999 должны были войти еще несколько частей. Среди них спецификации следующих средств:
управление распределенными транзакциями (SQL/Transaction); поддержка темпоральных свойств данных (SQL/Temporal);управление внешними данными (SQL/MED);связывание с объектно-ориентированными языками программирования (SQL/OLB);поддержка оперативной аналитической обработки (SQL/OLAP).
В конце 2003 г. был принят и опубликован новый вариант международного стандарта SQL:2003. Многие специалисты считали, что в варианте стандарта, следующем за SQL:1999, будут всего лишь исправлены неточности SQL:1999. Но на самом деле, в SQL:2003 специфицирован ряд новых и важных свойств, часть из которых мы затронем в этом курсе.
Претерпела некоторые изменения общая организация стандарта. Стандарт SQL:2003 состоит из следующих частей:
9075-1, SQL/Framework;9075-2, SQL/Foundation;9075-3, SQL/CLI;9075-4, SQL/PSM;9075-9, SQL/MED;9075-10, SQL/OLB;9075-11, SQL/Schemata;9075-13, SQL/JRT;9075-14, SQL/XML.
Части 1-4 и 9-10 с необходимыми изменениями остались такими же, как и в SQL:1999 (разд. 7.4). Часть 5 (SQL/Bindings) перестала существовать; соответствующие спецификации включены в часть 2. Раздел части 2 SQL:1999, посвященный информационной схеме, выделен в отдельную часть 11. Появились две новые части – 13 и 14. Часть 13 полностью называется «SQL Routines and Types Using the Java Programming Language» («Использование подпрограмм и типов SQL в языке программирования Java»). Появление такой части стандарта оправдано повышенным вниманием к языку Java со стороны ведущих производителей SQL-ориентированных СУБД. Наконец, последняя часть SQL:2003 посвящена спецификациям языковых средств, позволяющих работать с XML-документами в среде SQL.
На мой взгляд, текущее состояние процесса стандартизации языка SQL отражает текущее состояние технологии SQL-ориентированных баз данных. Ведущие поставщики соответствующих СУБД (сегодня это компании IBM, Oracle и Microsoft) стараются максимально быстро реагировать на потребности и конъюнктуру рынка и расширяют свои продукты все новыми и новыми возможностями. Очевидна потребность в стандартизации соответствующих языковых средств, но процесс стандартизации явно не поспевает за происходящими изменениями.
Третью часть занимает уточненная по
Третью часть занимает уточненная по сравнению с SQL/92 спецификация SQL/CLI. В четвертой части специфицируется SQL/PSM – синтаксис и семантика языка определения хранимых процедур. Наконец, в пятой части – SQL/Bindings – определяются правила связывания SQL для стандартных версий языков программирования FORTRAN, COBOL, PL/1, Pascal, Ada, C и MUMPS.
В стандарт SQL:1999 должны были войти еще несколько частей. Среди них спецификации следующих средств:
управление распределенными транзакциями (SQL/Transaction); поддержка темпоральных свойств данных (SQL/Temporal);управление внешними данными (SQL/MED);связывание с объектно-ориентированными языками программирования (SQL/OLB);поддержка оперативной аналитической обработки (SQL/OLAP).
В конце 2003 г. был принят и опубликован новый вариант международного стандарта SQL:2003. Многие специалисты считали, что в варианте стандарта, следующем за SQL:1999, будут всего лишь исправлены неточности SQL:1999. Но на самом деле, в SQL:2003 специфицирован ряд новых и важных свойств, часть из которых мы затронем в этом курсе.
Претерпела некоторые изменения общая организация стандарта. Стандарт SQL:2003 состоит из следующих частей:
9075-1, SQL/Framework;9075-2, SQL/Foundation;9075-3, SQL/CLI;9075-4, SQL/PSM;9075-9, SQL/MED;9075-10, SQL/OLB;9075-11, SQL/Schemata;9075-13, SQL/JRT;9075-14, SQL/XML.
Части 1-4 и 9-10 с необходимыми изменениями остались такими же, как и в SQL:1999 (разд. 7.4). Часть 5 (SQL/Bindings) перестала существовать; соответствующие спецификации включены в часть 2. Раздел части 2 SQL:1999, посвященный информационной схеме, выделен в отдельную часть 11. Появились две новые части – 13 и 14. Часть 13 полностью называется «SQL Routines and Types Using the Java Programming Language» («Использование подпрограмм и типов SQL в языке программирования Java»). Появление такой части стандарта оправдано повышенным вниманием к языку Java со стороны ведущих производителей SQL-ориентированных СУБД. Наконец, последняя часть SQL:2003 посвящена спецификациям языковых средств, позволяющих работать с XML-документами в среде SQL.
На мой взгляд, текущее состояние процесса стандартизации языка SQL отражает текущее состояние технологии SQL-ориентированных баз данных. Ведущие поставщики соответствующих СУБД (сегодня это компании IBM, Oracle и Microsoft) стараются максимально быстро реагировать на потребности и конъюнктуру рынка и расширяют свои продукты все новыми и новыми возможностями. Очевидна потребность в стандартизации соответствующих языковых средств, но процесс стандартизации явно не поспевает за происходящими изменениями.
Неявные и явные преобразования типа или домена
В языке SQL обеспечивается возможность использования в различных операциях не только значений тех типов, для которых предопределена операция, но и значений типов, неявным или явным образом приводимых к требуемому типу.
Неявные и явные преобразования типа или домена
В языке SQL обеспечивается возможность использования в различных операциях не только значений тех типов, для которых предопределена операция, но и значений типов, неявным или явным образом приводимых к требуемому типу.
Неявные преобразования типов в SQL
В SQL поддерживается совместимость некоторых типов данных за счет неявного преобразования значений одного типа к значениям другого типа данных (например, при необходимости FLOAT неявно приводится к DOUBLE). Опишем наиболее важные правила совместимости типов, принятые в SQL:1999. Начнем с определения приводимости типов. Тип данных A приводим к типу данных B в том и только в том случае, когда в любом месте, где ожидается значение типа B, может быть использовано значение типа A.
Основные правила приводимости типов состоят в следующем.
Типы символьных строк. Тип CHARACTER (x) приводим к любому типу CHARACTER (y), если y

Неявные преобразования типов в SQL
В SQL поддерживается совместимость некоторых типов данных за счет неявного преобразования значений одного типа к значениям другого типа данных (например, при необходимости FLOAT неявно приводится к DOUBLE). Опишем наиболее важные правила совместимости типов, принятые в SQL:1999. Начнем с определения приводимости типов. Тип данных A приводим к типу данных B в том и только в том случае, когда в любом месте, где ожидается значение типа B, может быть использовано значение типа A.
Основные правила приводимости типов состоят в следующем.
Типы символьных строк. Тип CHARACTER (x) приводим к любому типу CHARACTER (y), если y
Определение домена
Для определения домена в SQL используется оператор CREATE DOMAIN. Общий синтаксис этого оператора следующий:1)
domain_definition ::= CREATE DOMAIN domain_name [AS] data_type [ default_definition ] [ domain_constraint_definition_list ]
Здесь domain_name задает имя создаваемого домена2), data_type есть спецификация определяющего типа данных. В необязательных разделах default_definition и domain_constraint_definition_list специфицируются значение домена по умолчанию3) и набор ограничений целостности, которые будут применяться к любому столбцу, определенному на этом домене.
Раздел default_definition имеет вид
DEFAULT { literal | niladic_function | NULL }4)
Здесь literal представляет любое допустимое литеральное значение определяющего типа домена, NULL обозначает неопределенное значение, а niladic_function может задаваться в одной из следующих форм:
USER
CURRENT_USER
SESSION_USER
SYSTEM_USER
CURRENT_DATE
CURRENT_TIME
CURRENT_TIMESTAMP5)
Если в операторе CREATE DOMAIN значение по умолчанию не специфицируется, считается, что такого значения нет. Однако позже к определению домена можно добавить раздел значения по умолчанию с помощью оператора ALTER DOMAIN. Кроме того, этот оператор позволяет удалить раздел значения по умолчанию из существующего определения домена.
Элемент списка domain_constraint_definition_list имеет вид
[CONSTRAINT constraint_name] CHECK (conditional_expression)
Необязательный раздел CONSTRAINT constraint_name позволяет определить имя нового ограничения целостности. Если явное указание имени отсутствует, ограничению назначается имя, автоматически генерируемое системой. Что касается вида условного выражения, служащего собственно ограничением целостности, то в стандарте запрещается лишь прямое или косвенное использование в нем домена, в определение которого входит данное условное выражение.6) Однако наиболее естественным (и наиболее распространенным) видом ограничения домена является следующий:
CHECK (VALUE IN (list_of_valid_values))
Такое ограничение запрещает появление в любом столбце, определенном на данном домене, любого значения определяющего типа, не входящего в список допустимых значений.
Определение домена
Для определения домена в SQL используется оператор CREATE DOMAIN. Общий синтаксис этого оператора следующий:19)
domain_definition ::= CREATE DOMAIN domain_name [AS] data_type [ default_definition ] [ domain_constraint_definition_list ]
Здесь domain_name задает имя создаваемого домена20), data_type есть спецификация определяющего типа данных. В необязательных разделах default_definition и domain_constraint_definition_list специфицируются значение домена по умолчанию21) и набор ограничений целостности, которые будут применяться к любому столбцу, определенному на этом домене.
Раздел default_definition имеет вид
DEFAULT { literal | niladic_function | NULL }22)
Здесь literal представляет любое допустимое литеральное значение определяющего типа домена, NULL обозначает неопределенное значение, а niladic_function может задаваться в одной из следующих форм:
USER
CURRENT_USER
SESSION_USER
SYSTEM_USER
CURRENT_DATE
CURRENT_TIME
CURRENT_TIMESTAMP23)
Если в операторе CREATE DOMAIN значение по умолчанию не специфицируется, считается, что такого значения нет. Однако позже к определению домена можно добавить раздел значения по умолчанию с помощью оператора ALTER DOMAIN. Кроме того, этот оператор позволяет удалить раздел значения по умолчанию из существующего определения домена.
Элемент списка domain_constraint_definition_list имеет вид
[CONSTRAINT constraint_name] CHECK (conditional_expression)
Необязательный раздел CONSTRAINT constraint_name позволяет определить имя нового ограничения целостности. Если явное указание имени отсутствует, ограничению назначается имя, автоматически генерируемое системой. Что касается вида условного выражения, служащего собственно ограничением целостности, то в стандарте запрещается лишь прямое или косвенное использование в нем домена, в определение которого входит данное условное выражение.24) Однако наиболее естественным (и наиболее распространенным) видом ограничения домена является следующий:
CHECK (VALUE IN (list_of_valid_values))
Такое ограничение запрещает появление в любом столбце, определенном на данном домене, любого значения определяющего типа, не входящего в список допустимых значений.
Отмена определения домена
Чтобы отменить ранее созданное определение домена, нужно воспользоваться оператором DROP DOMAIN в следующем синтаксисе:
DROP DOMAIN domain_name {RESTRICT | CASCADES}
Если в операторе указано RESTRICT и если соответствующий домен использован в определении некоторого столбца, в определении некоторого представления или в определении ограничения целостности (см. следующие лекции), то оператор DROP DOMAIN отвергается. В противном случае определение домена ликвидируется.
Если в операторе DROP DOMAIN указано CASCADES, то оператор выполняется всегда. При этом уничтожаются все представления и ограничения целостности, в определении которых использовалось имя данного домена. Столбцы, определенные на этом домене, автоматически переопределяются следующим образом:
считается, что каждый такой столбец теперь относится к определяющему типу уничтожаемого домена;если у столбца не было определено собственное значение по умолчанию, то считается, что теперь у него имеется такое значение по умолчанию, совпадающее со значением по умолчанию уничтожаемого домена;каждый столбец наследует все ограничения уничтожаемого домена.
Отмена определения домена
Чтобы отменить ранее созданное определение домена, нужно воспользоваться оператором DROP DOMAIN в следующем синтаксисе:
DROP DOMAIN domain_name {RESTRICT | CASCADES}
Если в операторе указано RESTRICT и если соответствующий домен использован в определении некоторого столбца, в определении некоторого представления или в определении ограничения целостности (см. следующие лекции), то оператор DROP DOMAIN отвергается. В противном случае определение домена ликвидируется.
Если в операторе DROP DOMAIN указано CASCADES, то оператор выполняется всегда. При этом уничтожаются все представления и ограничения целостности, в определении которых использовалось имя данного домена. Столбцы, определенные на этом домене, автоматически переопределяются следующим образом:
считается, что каждый такой столбец теперь относится к определяющему типу уничтожаемого домена;если у столбца не было определено собственное значение по умолчанию, то считается, что теперь у него имеется такое значение по умолчанию, совпадающее со значением по умолчанию уничтожаемого домена;каждый столбец наследует все ограничения уничтожаемого домена.
Приближенные числовые типы
К категории приближенных числовых типов в SQL относятся те типы, значения которых представляют числа приближенным образом. Приближенные числа представляются в виде пары <мантисса, порядок>, где мантисса состоит из значащих цифр числа, а порядок определяет реальный размер числа. В реализациях приближенным числовым типам SQL обычно соответствуют типы с плавающей точкой. В SQL поддерживаются три варианта приближенных числовых типов.
Тип REAL. Значения типа соответствуют числам с плавающей точкой одинарной точности. Точность определяется в реализации, но обычно совпадает с точностью одинарной плавающей арифметики, поддерживаемой на аппаратной платформе, которая используется реализацией. При определении столбца указывается просто REAL.Тип DOUBLE PRECISION. Точность значений этого типа определяется в реализации, но она должна быть больше точности типа REAL. Обычно приближенным числам SQL с двойной точностью соответствуют поддерживаемые аппаратурой числа с плавающей точкой двойной точности. При определении столбца указывается просто DOUBLE PRECISION.Тип FLOAT. Это параметризуемый тип, значение параметра p которого задает необходимую точность значений. Требуется, чтобы реально обеспечиваемая реализацией точность значений была не меньше p. Допустимый диапазон значений параметра p определяется в реализации. При определении столбца можно указать либо FLOAT (p), либо просто FLOAT. В последнем случае подразумевается точность, определяемая реализацией по умолчанию.Литералы приближенных числовых типов представляются в виде литерала точного числового типа, за которым могут следовать символ «E» и литерал целого числового типа. Примеры литералов приближенных числовых типов: 123, 123.12, 123E12, 123.12E12. Литеральное выражение xEy представляет значение x*(10y).
Приближенные числовые типы
К категории приближенных числовых типов в SQL относятся те типы, значения которых представляют числа приближенным образом. Приближенные числа представляются в виде пары <мантисса, порядок>, где мантисса состоит из значащих цифр числа, а порядок определяет реальный размер числа. В реализациях приближенным числовым типам SQL обычно соответствуют типы с плавающей точкой. В SQL поддерживаются три варианта приближенных числовых типов.
Тип REAL. Значения типа соответствуют числам с плавающей точкой одинарной точности. Точность определяется в реализации, но обычно совпадает с точностью одинарной плавающей арифметики, поддерживаемой на аппаратной платформе, которая используется реализацией. При определении столбца указывается просто REAL.Тип DOUBLE PRECISION. Точность значений этого типа определяется в реализации, но она должна быть больше точности типа REAL. Обычно приближенным числам SQL с двойной точностью соответствуют поддерживаемые аппаратурой числа с плавающей точкой двойной точности. При определении столбца указывается просто DOUBLE PRECISION.Тип FLOAT. Это параметризуемый тип, значение параметра p которого задает необходимую точность значений. Требуется, чтобы реально обеспечиваемая реализацией точность значений была не меньше p. Допустимый диапазон значений параметра p определяется в реализации. При определении столбца можно указать либо FLOAT (p), либо просто FLOAT. В последнем случае подразумевается точность, определяемая реализацией по умолчанию.Литералы приближенных числовых типов представляются в виде литерала точного числового типа, за которым могут следовать символ «E» и литерал целого числового типа. Примеры литералов приближенных числовых типов: 123, 123.12, 123E12, 123.12E12. Литеральное выражение xEy представляет значение x*(10y).
Примеры изменения определения домена
Немного поупражняемся с доменом SALARY. Для изменения значения заработной платы по умолчанию с 10000 на 11000 руб. нужно выполнить оператор
ALTER DOMAIN SALARY SET DEFAULT 11000.00;
Для отмены значения по умолчанию в домене SALARY следует воспользоваться оператором
ALTER DOMAIN SALARY DROP DEFAULT;
Если к определению домена SALARY требуется добавить ограничение (например, запретить значение зарплаты, равное 15000 руб.), необходимо выполнить оператор
ALTER DOMAIN SALARY ADD CHECK (VALUE <> 15000.00);
Наконец, если требуется отменить (именованное!) ограничение целостности, препятствующее наличию неопределенных значений в столбцах, которые определены на домене SALARY, то нужно выполнить оператор
ALTER DOMAIN SALARY DROP CONSTRAINT SAL_NOT_NULL;
Примеры изменения определения домена
Немного поупражняемся с доменом SALARY. Для изменения значения заработной платы по умолчанию с 10000 на 11000 руб. нужно выполнить оператор
ALTER DOMAIN SALARY SET DEFAULT 11000.00;
Для отмены значения по умолчанию в домене SALARY следует воспользоваться оператором
ALTER DOMAIN SALARY DROP DEFAULT;
Если к определению домена SALARY требуется добавить ограничение (например, запретить значение зарплаты, равное 15000 руб.), необходимо выполнить оператор
ALTER DOMAIN SALARY ADD CHECK (VALUE <> 15000.00);
Наконец, если требуется отменить (именованное!) ограничение целостности, препятствующее наличию неопределенных значений в столбцах, которые определены на домене SALARY, то нужно выполнить оператор
ALTER DOMAIN SALARY DROP CONSTRAINT SAL_NOT_NULL;
Примеры определений доменов
В дальнейших примерах нам понадобятся определения нескольких доменов. Приведем их в этом подразделе. В примерах мы будем иметь дело с таблицами служащих (EMP), отделов (DEPT) и проектов (PRO). Каждый служащий обладает уникальным номером (EMP_NO) и получает заработную плату (SALARY). Определим домены EMP_NO и SALARY.
CREATE DOMAIN EMP_NO AS INTEGER CHECK (VALUE BETWEEN 1 AND 10000);
Номера служащих являются целыми числами, поэтому базовый тип домена EMP_NO есть тип INTEGER. Кроме того, на значения этого домена устанавливается следующее ограничение: они должны быть больше нуля и не превосходить целое значение 10000.
Домен SALARY определим следующим образом:
CREATE DOMAIN SALARY AS NUMERIC (10, 2) DEFAULT 10000.00 CHECK (VALUE BETWEEN 10000.00 AND 20000000.00) CONSTRAINT SAL_NOT_NULL CHECK (VALUE IS NOT NULL);
Размер заработной платы является значением точного числового типа NUMERIC из десяти десятичных цифр, две из которых составляют дробную часть. По умолчанию размер заработной платы составляет 10000 руб. Установлен диапазон допустимого размера зарплаты от 10000 руб. до 20000000 руб. Неопределенное значение зарплаты не допускается (на уровне определения домена).
Примеры определений доменов
В дальнейших примерах нам понадобятся определения нескольких доменов. Приведем их в этом подразделе. В примерах мы будем иметь дело с таблицами служащих (EMP), отделов (DEPT) и проектов (PRO). Каждый служащий обладает уникальным номером (EMP_NO) и получает заработную плату (SALARY). Определим домены EMP_NO и SALARY.
CREATE DOMAIN EMP_NO AS INTEGER CHECK (VALUE BETWEEN 1 AND 10000);
Номера служащих являются целыми числами, поэтому базовый тип домена EMP_NO есть тип INTEGER. Кроме того, на значения этого домена устанавливается следующее ограничение: они должны быть больше нуля и не превосходить целое значение 10000.
Домен SALARY определим следующим образом:
CREATE DOMAIN SALARY AS NUMERIC (10, 2) DEFAULT 10000.00 CHECK (VALUE BETWEEN 10000.00 AND 20000000.00) CONSTRAINT SAL_NOT_NULL CHECK (VALUE IS NOT NULL);
Размер заработной платы является значением точного числового типа NUMERIC из десяти десятичных цифр, две из которых составляют дробную часть. По умолчанию размер заработной платы составляет 10000 руб. Установлен диапазон допустимого размера зарплаты от 10000 руб. до 20000000 руб. Неопределенное значение зарплаты не допускается (на уровне определения домена).
Средства определения, изменения определения и отмены определения доменов
Как неоднократно упоминалось выше, при определении столбцов таблицы требуется явно указывать тип данных каждого столбца. Для этого можно использовать описанные выше средства спецификации типа. Но в SQL поддерживается и другой механизм— механизм доменов. Домен является долговременно хранимым, именованным объектом схемы базы данных. Домены можно создавать (определять), изменять (изменять определения) и ликвидировать (отменять определение). Имена доменов можно использовать при определении столбцов таблиц. Можно считать, что в SQL определение домена представляет собой вынесенное за пределы определения индивидуальной таблицы «родовое» определение столбца, которое можно использовать для определения различных реальных столбцов реальных базовых таблиц. В языке SQL обеспечиваются средства определения доменов, изменения и отмены существующих определений.
Средства определения, изменения определения и отмены определения доменов
Как неоднократно упоминалось выше, при определении столбцов таблицы требуется явно указывать тип данных каждого столбца. Для этого можно использовать описанные выше средства спецификации типа. Но в SQL поддерживается и другой механизм— механизм доменов. Домен является долговременно хранимым, именованным объектом схемы базы данных. Домены можно создавать (определять), изменять (изменять определения) и ликвидировать (отменять определение). Имена доменов можно использовать при определении столбцов таблиц. Можно считать, что в SQL определение домена представляет собой вынесенное за пределы определения индивидуальной таблицы «родовое» определение столбца, которое можно использовать для определения различных реальных столбцов реальных базовых таблиц. В языке SQL обеспечиваются средства определения доменов, изменения и отмены существующих определений.
Ссылочные типы
Эта категория типов данных связана с объектными расширениями языка SQL, и мы снова отложим подробное обсуждение этого механизма до заключительной лекции курса и рассмотрим его здесь очень коротко. Обеспечивается механизм конструирования типов (ссылочных типов), которые могут использоваться в качестве типов столбцов некоторого вида таблиц (типизированных таблиц). Фактически значениями ссылочного типа являются строки соответствующей типизированной таблицы. Более точно, каждой строке типизированной таблицы приписывается уникальное значение (нечто вроде первичного ключа, назначаемого системой или приложением), которое может использоваться в методах, определенных для табличного типа, для уникальной идентификации строк соответствующей таблицы. Эти уникальные значения называются ссылочными значениями, а их тип – ссылочным типом. Ссылочный тип может содержать только те значения, которые действительно ссылаются на экземпляры указанного типа (т. е. на строки соответствующей типизированной таблицы).
Ссылочные типы
Эта категория типов данных связана с объектными расширениями языка SQL, и мы снова отложим подробное обсуждение этого механизма до заключительной лекции курса и рассмотрим его здесь очень коротко. Обеспечивается механизм конструирования типов (ссылочных типов), которые могут использоваться в качестве типов столбцов некоторого вида таблиц (типизированных таблиц). Фактически значениями ссылочного типа являются строки соответствующей типизированной таблицы. Более точно, каждой строке типизированной таблицы приписывается уникальное значение (нечто вроде первичного ключа, назначаемого системой или приложением), которое может использоваться в методах, определенных для табличного типа, для уникальной идентификации строк соответствующей таблицы. Эти уникальные значения называются ссылочными значениями, а их тип – ссылочным типом. Ссылочный тип может содержать только те значения, которые действительно ссылаются на экземпляры указанного типа (т. е. на строки соответствующей типизированной таблицы).
Структура языка SQL
В данной лекции мы начинаем систематически описывать базовые механизмы языка SQL. Чтобы пояснить, о какой части языка пойдет речь в этой и следующих лекциях, обратимся к рис. 11.1.
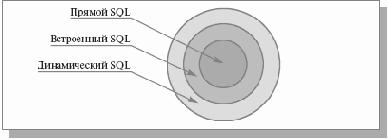
Рис. 11.1. Один из способов разделения языка SQL на уровни
Язык SQL, соответствующий последним стандартам SQL:2003, SQL:1999 (и даже SQL/92), представляет собой очень богатый и сложный язык, все возможности которого трудно сразу осознать и тем более понять. Поэтому приходится разбивать язык на уровни, или слои, такие, что каждый уровень языка включает все конструкции, входящие в более низкие уровни. В стандарте определяется несколько способов разбиения языка на уровни. В одной из классификаций язык разбивается на «базовый» (entry), «промежуточный» (intermediate) и «полный» (full) уровни.
Эта классификация ориентирована, прежде всего, на производителей СУБД, в которых поддерживается SQL. Реализация базового уровня языка является обязательным условием хотя бы какого-то соответствия стандарту. Реализация промежуточного уровня желательна, и обычно именно такой уровень языка поддерживается ведущими компаниями-производителями SQL-ориентированных СУБД. Наконец, полный уровень языка является целью, к достижению которой следует стремиться. В данной классификации критерием отнесения той или иной возможности языка к некоторому уровню является оцениваемая создателями стандарта SQL (большая часть которых является сотрудниками ведущих компаний, производящих SQL-ориентированные СУБД) техническая сложность реализации этой возможности. Конечно, такая классификация важна и для программистов приложений баз данных, но только для того, чтобы оценить реальные возможности конкретной СУБД. Для понимания языка SQL это разбиение на уровни несущественно.
Другая классификация показана на рис. 11.1. Среди всех конструкций языка SQL можно выделить такие конструкции, которые можно было использовать при «прямом» (direct) взаимодействии конечного пользователя с СУБД (например, в интерактивном режиме). В некотором смысле этот уровень также является базовым, поскольку соответствующие средства языка в наибольшей степени отражают его ориентированность на работу с множествами. На следующем уровне, уровне «встраиваемого» (embedded) SQL, язык расширяется конструкциями, позволяющими использовать возможности прямого SQL в программах, написанных на традиционных языках программирования. Наконец, на уровне «динамического» (dynamic) SQL во встраиваемый SQL добавляются конструкции, позволяющие приложениям обращаться к СУБД с конструкциями прямого SQL, которые динамически образуются во время выполнения программы.
Нам кажется, что вторая классификация является более полезной для читателя, постигающего основы языка SQL. По нашему мнению, дополнительные возможности, присутствующие во встраиваемом и в динамическом SQL, не слишком сильно влияют на модельное представление языка. Конечно, возможности встраиваемого и динамического SQL необходимо хорошо знать разработчикам приложений SQL-ориентированных баз данных. Но поскольку задачей этого курса не является обучение использованию языка SQL при программировании приложений баз данных, мы не будем затрагивать эти темы. Обратимся к прямому SQL, причем не в полном объеме стандартов SQL:2003 и SQL:1999 (этого не позволяет сделать объем курса). Обсудим только наиболее важные аспекты.
В этой лекции обсуждаются основные аспекты системы типов данных языка SQL и средства определения доменов.
Замечание: Лекции, посвященные языку SQL, опираются, главным образом, на стандарт SQL:1999. В тех случаях, когда будут упоминаться дополнительные возможности, специфицированные в наиболее свежей версии стандарта – SQL:2003, мы будем явно на это указывать. Поэтому здесь мы используем терминологию стандарта (таблицы, строки, столбцы и т. д.).6)
Структура языка SQL
В данной лекции мы начинаем систематически описывать базовые механизмы языка SQL. Чтобы пояснить, о какой части языка пойдет речь в этой и следующих лекциях, обратимся к рис. 11.1.
Рис. 11.1. Один из способов разделения языка SQL на уровни
Язык SQL, соответствующий последним стандартам SQL:2003, SQL:1999 (и даже SQL/92), представляет собой очень богатый и сложный язык, все возможности которого трудно сразу осознать и тем более понять. Поэтому приходится разбивать язык на уровни, или слои, такие, что каждый уровень языка включает все конструкции, входящие в более низкие уровни. В стандарте определяется несколько способов разбиения языка на уровни. В одной из классификаций язык разбивается на «базовый» (entry), «промежуточный» (intermediate) и «полный» (full) уровни.
Эта классификация ориентирована, прежде всего, на производителей СУБД, в которых поддерживается SQL. Реализация базового уровня языка является обязательным условием хотя бы какого-то соответствия стандарту. Реализация промежуточного уровня желательна, и обычно именно такой уровень языка поддерживается ведущими компаниями-производителями SQL-ориентированных СУБД. Наконец, полный уровень языка является целью, к достижению которой следует стремиться. В данной классификации критерием отнесения той или иной возможности языка к некоторому уровню является оцениваемая создателями стандарта SQL (большая часть которых является сотрудниками ведущих компаний, производящих SQL-ориентированные СУБД) техническая сложность реализации этой возможности. Конечно, такая классификация важна и для программистов приложений баз данных, но только для того, чтобы оценить реальные возможности конкретной СУБД. Для понимания языка SQL это разбиение на уровни несущественно.
Другая классификация показана на рис. 11.1. Среди всех конструкций языка SQL можно выделить такие конструкции, которые можно было использовать при «прямом» (direct) взаимодействии конечного пользователя с СУБД (например, в интерактивном режиме). В некотором смысле этот уровень также является базовым, поскольку соответствующие средства языка в наибольшей степени отражают его ориентированность на работу с множествами. На следующем уровне, уровне «встраиваемого» (embedded) SQL, язык расширяется конструкциями, позволяющими использовать возможности прямого SQL в программах, написанных на традиционных языках программирования. Наконец, на уровне «динамического» (dynamic) SQL во встраиваемый SQL добавляются конструкции, позволяющие приложениям обращаться к СУБД с конструкциями прямого SQL, которые динамически образуются во время выполнения программы.
Нам кажется, что вторая классификация является более полезной для читателя, постигающего основы языка SQL. По нашему мнению, дополнительные возможности, присутствующие во встраиваемом и в динамическом SQL, не слишком сильно влияют на модельное представление языка. Конечно, возможности встраиваемого и динамического SQL необходимо хорошо знать разработчикам приложений SQL-ориентированных баз данных. Но поскольку задачей этого курса не является обучение использованию языка SQL при программировании приложений баз данных, мы не будем затрагивать эти темы. Обратимся к прямому SQL, причем не в полном объеме стандартов SQL:2003 и SQL:1999 (этого не позволяет сделать объем курса). Обсудим только наиболее важные аспекты.
В этой лекции обсуждаются основные аспекты системы типов данных языка SQL и средства определения доменов.
Замечание: Лекции, посвященные языку SQL, опираются, главным образом, на стандарт SQL:1999. В тех случаях, когда будут упоминаться дополнительные возможности, специфицированные в наиболее свежей версии стандарта – SQL:2003, мы будем явно на это указывать. Поэтому здесь мы используем терминологию стандарта (таблицы, строки, столбцы и т. д.).6)
Тип даты
Тип DATE. Значения этого типа состоят из компонентов-значений года, месяца и дня некоторой даты. Значение года состоит из четырех десятичных цифр и соответствует летоисчислению от Рождества Христова до 9999 г. Значение месяца состоит из двух десятичных цифр и варьируется от 01 до 12. Значение номера дня месяца состоит из двух десятичных цифр и варьируется от 01 до 31, хотя значение месяца даты может накладывать ограничения на возможность использования значений дня месяца 29, 30 и 31. В стандарте SQL не накладываются какие-либо ограничения на внутренний способ представления дат, используемый в реализации. При определении столбца типа DATE указывается просто DATE.Литералы типа DATE представляются в виде строки «’yyyy-mm-dd’», где символы y, m и d должны изображать десятичные числа. Например, литерал DATE ’1949-04-08’ представляет дату 8 апреля 1949 г.
Тип даты
Тип DATE. Значения этого типа состоят из компонентов-значений года, месяца и дня некоторой даты. Значение года состоит из четырех десятичных цифр и соответствует летоисчислению от Рождества Христова до 9999 г. Значение месяца состоит из двух десятичных цифр и варьируется от 01 до 12. Значение номера дня месяца состоит из двух десятичных цифр и варьируется от 01 до 31, хотя значение месяца даты может накладывать ограничения на возможность использования значений дня месяца 29, 30 и 31. В стандарте SQL не накладываются какие-либо ограничения на внутренний способ представления дат, используемый в реализации. При определении столбца типа DATE указывается просто DATE.Литералы типа DATE представляются в виде строки «’yyyy-mm-dd’», где символы y, m и d должны изображать десятичные числа. Например, литерал DATE ’1949-04-08’ представляет дату 8 апреля 1949 г.
Типы битовых строк
В SQL определены три параметризуемых типа битовых строк: BIT, BIT VARYING и BINARY LARGE OBJECT (или BLOB).
Тип BIT. Значениями типа являются битовые строки. При определении столбца допускается использование спецификаций BIT (x) и просто BIT. Последний вариант эквивалентен заданию BIT (1). После определения столбца типа BIT (x) СУБД будет резервировать место для хранения x бит этого столбца во всех строках соответствующей таблицы.Тип BIT VARYING. При определении столбца допускается использование только спецификации без умолчания вида BIT VARYING (x), где значение x определяет максимальную длину битовой строки, которую можно хранить в данном столбце. Над битовыми строками определен ряд операций. Некоторые из них мы рассмотрим. Битовая конкатенация (обозначается в виде ||), которая возвращает результирующую битовую строку, полученную путем конкатенации строк-аргументов в том порядке, в котором они заданы. Функция извлечения подстроки из битовой строки. Синтаксис и семантика этой функции идентичны синтаксису и семантике функции SUBSTRING для символьных строк, за исключением того, что первый аргумент и возвращаемое значение являются битовыми строками. Функция определения длины (OCTET_LENGTH, BIT_LENGTH) возвращает длину заданной битовой строки в октетах или битах в зависимости от выбранной функции. Функция определения позиции (POSITION) определяет первую позицию в битовой строке S, с которой в нее входит строка S1. Если строка S1 не входит в строку S, возвращается значение нуль.
Тип BINARY LARGE OBJECT. Этот тип данных предназначен для определения столбцов, хранящих большие и разные по размеру группы байтов. При определении столбца задается спецификация BLOB (z), где z задает максимальный размер соответствующей группы байтов. С технической точки зрения типы CLOB и BLOB очень похожи. Их разделение требуется для того, чтобы подчеркнуть, что значения типа CLOB состоят из символов (в частности, в них может осмысленно производиться текстовый поиск), а значения типа BLOB состоят из произвольных байтов, не обязательно кодирующих символы.Литералы типов битовых строк представляются как заключенные в одинарные кавычки последовательности символов «0» и «1», предваряемые символом «B»; или предваряемые символом «X» последовательности символов, которые изображают шестнадцатеричные цифры (за цифрой «9» следуют «A», «B», «C», «D», «E» и «F»). Примеры литералов типов битовых строк: B’0111001111000111111111’, X’78FBCD0012FFFFA’.1)
Типы битовых строк
В SQL определены три параметризуемых типа битовых строк: BIT, BIT VARYING и BINARY LARGE OBJECT (или BLOB).
Тип BIT. Значениями типа являются битовые строки. При определении столбца допускается использование спецификаций BIT (x) и просто BIT. Последний вариант эквивалентен заданию BIT (1). После определения столбца типа BIT (x) СУБД будет резервировать место для хранения x бит этого столбца во всех строках соответствующей таблицы.Тип BIT VARYING. При определении столбца допускается использование только спецификации без умолчания вида BIT VARYING (x), где значение x определяет максимальную длину битовой строки, которую можно хранить в данном столбце. Над битовыми строками определен ряд операций. Некоторые из них мы рассмотрим. Битовая конкатенация (обозначается в виде ||), которая возвращает результирующую битовую строку, полученную путем конкатенации строк-аргументов в том порядке, в котором они заданы. Функция извлечения подстроки из битовой строки. Синтаксис и семантика этой функции идентичны синтаксису и семантике функции SUBSTRING для символьных строк, за исключением того, что первый аргумент и возвращаемое значение являются битовыми строками. Функция определения длины (OCTET_LENGTH, BIT_LENGTH) возвращает длину заданной битовой строки в октетах или битах в зависимости от выбранной функции. Функция определения позиции (POSITION) определяет первую позицию в битовой строке S, с которой в нее входит строка S1. Если строка S1 не входит в строку S, возвращается значение нуль.
Тип BINARY LARGE OBJECT. Этот тип данных предназначен для определения столбцов, хранящих большие и разные по размеру группы байтов. При определении столбца задается спецификация BLOB (z), где z задает максимальный размер соответствующей группы байтов. С технической точки зрения типы CLOB и BLOB очень похожи. Их разделение требуется для того, чтобы подчеркнуть, что значения типа CLOB состоят из символов (в частности, в них может осмысленно производиться текстовый поиск), а значения типа BLOB состоят из произвольных байтов, не обязательно кодирующих символы.Литералы типов битовых строк представляются как заключенные в одинарные кавычки последовательности символов «0» и «1», предваряемые символом «B»; или предваряемые символом «X» последовательности символов, которые изображают шестнадцатеричные цифры (за цифрой «9» следуют «A», «B», «C», «D», «E» и «F»). Примеры литералов типов битовых строк: B’0111001111000111111111’, X’78FBCD0012FFFFA’.14)
Типы данных SQL
Данные, хранящиеся в столбцах таблиц SQL-ориентированной базы данных, являются типизированными, т. е. представляют собой значения одного из типов данных, предопределенных в языке SQL или определяемых пользователями путем применения соответствующих средств языка. Для этого при определении таблицы каждому ее столбцу назначается некоторый тип данных (или домен), и в дальнейшем СУБД должна следить, чтобы в каждом столбце каждой строки каждой таблицы присутствовали только допустимые значения. В этом разделе мы обсудим систему типов языка SQL.
Все допустимые в SQL типы данных, которые можно использовать при определении столбцов, разбиваются на следующие категории:
точные числовые типы (exact numerics);приближенные числовые типы (approximate numerics);типы символьных строк (character strings);типы битовых строк (bit strings)1);типы даты и времени (datetimes);типы временных интервалов (intervals);булевский тип (Booleans);типы коллекций (collection types);анонимные строчные типы (anonymous row types);типы, определяемые пользователем (user-defined types);ссылочные типы (reference types).
В столбцах таблиц, определенных на любых типах данных, наряду со значениями этих типов, допускается сохранение неопределенного значения, которое обозначается ключевым словом NULL. В языке определено, что результатом выражений вида x a_op NULL, NULL a_op x, NULL a_op NULL является NULL для всех арифметических операций a_op (+, - и т. д.), допустимых для типа данных выражения x (выражение NULL a_op NULL является допустимым для любой арифметической операции a_op). Также по определению полагается, что значением выражений x comp_op NULL, NULL comp_op x, NULL comp_op NULL для всех операций сравнения (=,

Типы данных SQL
Данные, хранящиеся в столбцах таблиц SQL-ориентированной базы данных, являются типизированными, т. е. представляют собой значения одного из типов данных, предопределенных в языке SQL или определяемых пользователями путем применения соответствующих средств языка. Для этого при определении таблицы каждому ее столбцу назначается некоторый тип данных (или домен), и в дальнейшем СУБД должна следить, чтобы в каждом столбце каждой строки каждой таблицы присутствовали только допустимые значения. В этом разделе мы обсудим систему типов языка SQL.
Все допустимые в SQL типы данных, которые можно использовать при определении столбцов, разбиваются на следующие категории:
точные числовые типы (exact numerics);приближенные числовые типы (approximate numerics);типы символьных строк (character strings);типы битовых строк (bit strings)7);типы даты и времени (datetimes);типы временных интервалов (intervals);булевский тип (Booleans);типы коллекций (collection types);анонимные строчные типы (anonymous row types);типы, определяемые пользователем (user-defined types);ссылочные типы (reference types).
В столбцах таблиц, определенных на любых типах данных, наряду со значениями этих типов, допускается сохранение неопределенного значения, которое обозначается ключевым словом NULL. В языке определено, что результатом выражений вида x a_op NULL, NULL a_op x, NULL a_op NULL является NULL для всех арифметических операций a_op (+, - и т. д.), допустимых для типа данных выражения x (выражение NULL a_op NULL является допустимым для любой арифметической операции a_op). Также по определению полагается, что значением выражений x comp_op NULL, NULL comp_op x, NULL comp_op NULL для всех операций сравнения (=,
Типы даты и времени
Возможность сохранения в базе данных информации о дате и времени очень важна с практической точки зрения. Достаточно вспомнить взбудоражившую весь мир «проблему 2000 года», одним из основных источников которой было некорректное хранение дат в базах данных. В стандарте SQL поддержке средств работы с датой и временем уделяется большое внимание. В частности, поддерживаются специальные «темпоральные» типы данных DATE, TIME, TIMESTAMP, TIME WITH TIME ZONE и TIMESTAMP WITH TIME ZONE. Коротко обсудим эти типы.
Типы даты и времени
Возможность сохранения в базе данных информации о дате и времени очень важна с практической точки зрения. Достаточно вспомнить взбудоражившую весь мир «проблему 2000 года», одним из основных источников которой было некорректное хранение дат в базах данных. В стандарте SQL поддержке средств работы с датой и временем уделяется большое внимание. В частности, поддерживаются специальные «темпоральные» типы данных DATE, TIME, TIMESTAMP, TIME WITH TIME ZONE и TIMESTAMP WITH TIME ZONE. Коротко обсудим эти типы.
Типы коллекций
Начиная с SQL:1999 в языке поддерживается возможность использования типов данных, значения которых являются коллекциями значений некоторых других типов. Обычно под термином коллекция понимается одно из следующих образований: массив, список, множество и мультимножество. В варианте SQL:1999, принятом в 1999 г., были специфицированы только типы массивов. В новом стандарте SQL:2003 появилась спецификация типа мультимножества.
Типы коллекций
Начиная с SQL:1999 в языке поддерживается возможность использования типов данных, значения которых являются коллекциями значений некоторых других типов. Обычно под термином коллекция понимается одно из следующих образований: массив, список, множество и мультимножество. В варианте SQL:1999, принятом в 1999 г., были специфицированы только типы массивов. В новом стандарте SQL:2003 появилась спецификация типа мультимножества.
Типы массивов
Любой возможный тип массива получается путем применения конструктора типов ARRAY. При определении столбца, значения которого должны принадлежать некоторому типу массива, используется конструкция dt ARRAY [ mc ], где dt специфицирует некоторый допустимый в SQL тип данных, а mc является литералом некоторого точного числового типа с нулевой длиной шкалы и определяет максимальное число элементов в значении типа массива (в терминологии SQL:1999 это значение называется максимальной кардинальностью массива). В стандарте SQL:1999 многомерные массивы и массивы массивов не поддерживались. Однако в стандарте SQL:2003 это ограничение было снято, и теперь типом элементов любого типа коллекций может быть любой допустимый в SQL тип данных, кроме самого конструируемого типа коллекции.
Элементам каждого значения типа массива соответствуют их порядковые номера, называемые индексами. Значение индекса всегда должно принадлежать отрезку [1, mc]. Значениями типа массива dt ARRAY [mc] являются все массивы, состоящие из элементов типа dt, максимальное значение индекса которых cs не превосходит значения mc. При сохранении в базе данных значения типа массива занимает столько памяти, сколько требуется для сохранения cs элементов. Обеспечивается доступ к элементам массива по их индексам. В частности, можно объявить столбец типа INTEGER ARRAY [10] и при вставке строки в соответствующую таблицу задать значение только пятого элемента массива. Тогда в строку будет занесен массив из пяти элементов, причем первые четыре элемента будут содержать неопределенное значение (NULL).
Основными операциями над массивами являются выборка значения элемента массива по его индексу, изменение некоторого элемента массива или массива целиком и конкатенация (сцепление) двух массивов. Кроме того, для любого значения типа массива можно узнать значение его cs.
Типы массивов
Любой возможный тип массива получается путем применения конструктора типов ARRAY. При определении столбца, значения которого должны принадлежать некоторому типу массива, используется конструкция dt ARRAY [ mc ], где dt специфицирует некоторый допустимый в SQL тип данных, а mc является литералом некоторого точного числового типа с нулевой длиной шкалы и определяет максимальное число элементов в значении типа массива (в терминологии SQL:1999 это значение называется максимальной кардинальностью массива). В стандарте SQL:1999 многомерные массивы и массивы массивов не поддерживались. Однако в стандарте SQL:2003 это ограничение было снято, и теперь типом элементов любого типа коллекций может быть любой допустимый в SQL тип данных, кроме самого конструируемого типа коллекции.
Элементам каждого значения типа массива соответствуют их порядковые номера, называемые индексами. Значение индекса всегда должно принадлежать отрезку [1, mc]. Значениями типа массива dt ARRAY [mc] являются все массивы, состоящие из элементов типа dt, максимальное значение индекса которых cs не превосходит значения mc. При сохранении в базе данных значения типа массива занимает столько памяти, сколько требуется для сохранения cs элементов. Обеспечивается доступ к элементам массива по их индексам. В частности, можно объявить столбец типа INTEGER ARRAY [10] и при вставке строки в соответствующую таблицу задать значение только пятого элемента массива. Тогда в строку будет занесен массив из пяти элементов, причем первые четыре элемента будут содержать неопределенное значение (NULL).
Основными операциями над массивами являются выборка значения элемента массива по его индексу, изменение некоторого элемента массива или массива целиком и конкатенация (сцепление) двух массивов. Кроме того, для любого значения типа массива можно узнать значение его cs.
Типы мультимножеств
При определении столбца таблицы типа мультимножеств используется конструкция dt MULTISET, где dt задает тип данных элементов конструируемого типа мультимножеств. Значениями типа мультимножеств являются мультимножества, т. е. неупорядоченные коллекции элементов одного и того же типа, среди которых допускаются дубликаты. Например, значениями типа INTEGER MULTISET являются мультимножества, элементами которых — целые числа. Примером такого значения может быть мультимножество {12, 34, 12, 45, -64}.
В отличие от массива, мультимножество является неограниченной коллекцией; при конструировании типа мультимножеств не указывается предельная кардинальность значений этого типа. Однако это не означает, что возможность вставки элементов в мультимножество действительно не ограничена; стандарт всего лишь не требует явного объявления границы. Ситуация аналогична той, которая возникает при работе с таблицами, для которых в SQL не объявляется максимально допустимое число строк.1)
Для типов мультимножеств поддерживаются операции преобразования типа значения-мультимножества к типу массивов или другому типу мультимножеств с совместимым типом элементов (операция CAST), для удаления дубликатов из мультимножества (функция SET), для определения числа элементов в заданном мультимножестве (функция CARDINALITY), для выборки элемента мультимножества, содержащего в точности один элемент (функция ELEMENT). Кроме того, для мультимножеств обеспечиваются операции объединения (MULTISET UNION), пересечения (MULTISET INTERSECT) и определения разности (MULTISET EXCEPT). Каждая из операций может выполняться в режиме с сохранением дубликатов (режим ALL) или с устранением дубликатов (режим DISTINCT).
Расширенные в SQL:2003 возможности работы с типами коллекций являются принципиально важными. Даже при наличии определяемых пользователями типов данных (см. ниже) и типов массивов SQL:1999 не предоставлял полных возможностей для преодоления исторически присущего реляционной модели данных вообще и SQL в частности ограничения «плоских таблиц». После появления конструктора типов мультимножеств и устранения ограничений на тип данных элементов коллекции это историческое ограничение полностью ликвидировано. Мультимножество, типом элементов которого является анонимный строчный тип (см. ниже), представляет собой полный аналог таблицы. Тем самым, в базе данных допускается произвольная вложенность таблиц. Возможности выбора структуры базы данных безгранично расширяются.
Типы мультимножеств
При определении столбца таблицы типа мультимножеств используется конструкция dt MULTISET, где dt задает тип данных элементов конструируемого типа мультимножеств. Значениями типа мультимножеств являются мультимножества, т. е. неупорядоченные коллекции элементов одного и того же типа, среди которых допускаются дубликаты. Например, значениями типа INTEGER MULTISET являются мультимножества, элементами которых — целые числа. Примером такого значения может быть мультимножество {12, 34, 12, 45, -64}.
В отличие от массива, мультимножество является неограниченной коллекцией; при конструировании типа мультимножеств не указывается предельная кардинальность значений этого типа. Однако это не означает, что возможность вставки элементов в мультимножество действительно не ограничена; стандарт всего лишь не требует явного объявления границы. Ситуация аналогична той, которая возникает при работе с таблицами, для которых в SQL не объявляется максимально допустимое число строк.15)
Для типов мультимножеств поддерживаются операции преобразования типа значения-мультимножества к типу массивов или другому типу мультимножеств с совместимым типом элементов (операция CAST), для удаления дубликатов из мультимножества (функция SET), для определения числа элементов в заданном мультимножестве (функция CARDINALITY), для выборки элемента мультимножества, содержащего в точности один элемент (функция ELEMENT). Кроме того, для мультимножеств обеспечиваются операции объединения (MULTISET UNION), пересечения (MULTISET INTERSECT) и определения разности (MULTISET EXCEPT). Каждая из операций может выполняться в режиме с сохранением дубликатов (режим ALL) или с устранением дубликатов (режим DISTINCT).
Расширенные в SQL:2003 возможности работы с типами коллекций являются принципиально важными. Даже при наличии определяемых пользователями типов данных (см. ниже) и типов массивов SQL:1999 не предоставлял полных возможностей для преодоления исторически присущего реляционной модели данных вообще и SQL в частности ограничения «плоских таблиц». После появления конструктора типов мультимножеств и устранения ограничений на тип данных элементов коллекции это историческое ограничение полностью ликвидировано. Мультимножество, типом элементов которого является анонимный строчный тип (см. ниже), представляет собой полный аналог таблицы. Тем самым, в базе данных допускается произвольная вложенность таблиц. Возможности выбора структуры базы данных безгранично расширяются.
Типы, определяемые пользователем
Эта категория типов данных связана с объектными расширениями языка SQL. Более подробно мы обсудим эту тему в заключительной лекции курса, а здесь для полноты картины приведем беглый набросок.
Структурные типы (Structured Types). Соответствующие возможности SQL:1999 позволяют определять долговременно хранимые, именованные типы данных3), включающие один или более атрибутов любого из допустимых в SQL типа данных4), в том числе другие структурные типы: типы коллекций, строчные типы и т. д. Стандарт SQL не накладывает ограничений на сложность получаемой в результате структуры данных, однако не запрещает устанавливать такие ограничения в реализации. Дополнительные механизмы определяемых пользователями методов, функций и процедур позволяют определить поведенческие аспекты структурного типа. Индивидуальные типы (Distinct Types). Можно определить долговременно хранимый, именованный тип данных, опираясь на единственный предопределенный тип. Например, можно определить индивидуальный тип данных PRICE, опираясь на тип DECIMAL (5, 2). Тогда значения типа PRICE представляются точно так же, как значения типа DECIMAL (5, 2). Однако в SQL:1999 индивидуальный тип не наследует от своего опорного типа набор операций над значениями. Например, чтобы сложить два значения типа PRICE требуется явно сообщить системе, что с этими значениями нужно обращаться как со значениями типа DECIMAL (5, 2). Другая возможность состоит в явном определении методов, функций и процедур, связанных с данным индивидуальным типом. Похоже, что в будущих версиях стандарта появятся и другие, более удобные возможности.
Типы, определяемые пользователем
Эта категория типов данных связана с объектными расширениями языка SQL. Более подробно мы обсудим эту тему в заключительной лекции курса, а здесь для полноты картины приведем беглый набросок.
Структурные типы (Structured Types). Соответствующие возможности SQL:1999 позволяют определять долговременно хранимые, именованные типы данных17), включающие один или более атрибутов любого из допустимых в SQL типа данных18), в том числе другие структурные типы: типы коллекций, строчные типы и т. д. Стандарт SQL не накладывает ограничений на сложность получаемой в результате структуры данных, однако не запрещает устанавливать такие ограничения в реализации. Дополнительные механизмы определяемых пользователями методов, функций и процедур позволяют определить поведенческие аспекты структурного типа. Индивидуальные типы (Distinct Types). Можно определить долговременно хранимый, именованный тип данных, опираясь на единственный предопределенный тип. Например, можно определить индивидуальный тип данных PRICE, опираясь на тип DECIMAL (5, 2). Тогда значения типа PRICE представляются точно так же, как значения типа DECIMAL (5, 2). Однако в SQL:1999 индивидуальный тип не наследует от своего опорного типа набор операций над значениями. Например, чтобы сложить два значения типа PRICE требуется явно сообщить системе, что с этими значениями нужно обращаться как со значениями типа DECIMAL (5, 2). Другая возможность состоит в явном определении методов, функций и процедур, связанных с данным индивидуальным типом. Похоже, что в будущих версиях стандарта появятся и другие, более удобные возможности.
Типы символьных строк
В SQL определены три параметризуемых типа символьных строк: CHARACTER (или CHAR), CHARACTER VARYING (или CHAR VARYING, или VARCHAR) и CHARACTER LARGE OBJECT (или CLOB).4)
Тип CHARACTER. Значениями типа являются символьные строки. Конкретный набор допустимых символов определяется в реализации, но, как правило, включает набор символов ASCII. При определении столбца допускается использование спецификаций CHARACTER (x) и просто CHARACTER. Последний вариант эквивалентен заданию CHARACTER (1). После определения столбца типа CHARACTER (x) СУБД будет резервировать место для хранения x символов этого столбца во всех строках соответствующей таблицы. Если, например, определен столбец типа CHARACTER (8) и в некоторой строке таблицы в него заносится символьная строка длиной пять символов, то реально будут храниться восемь символов, последние три из которых будут пробелами5).Тип CHARACTER VARYING. При определении столбца допускается использование спецификаций CHARACTER VARYING (x) и просто CHARACTER VARYING. Последний вариант эквивалентен заданию CHARACTER VARYING (1). Если в некоторой таблице определяется столбец типа CHARACTER VARYING (x), то в каждой строке этой таблицы значения данного столбца будут занимать ровно столько места, сколько требуется для сохранения соответствующей символьной строки (но ни одна такая строка не может состоять более чем из x символов).6) Определен ряд операций, которые можно выполнять над символьными строками. Перечислим некоторые из них. Операция конкатенации (обозначается в виде «||») возвращает символьную строку, произведенную путем соединения строк-операндов в том порядке, в каком они заданы. Функция выделения подстроки (SUBSTRING) принимает три аргумента – строку, номер начальной позиции и длину – и возвращает строку, выделенную из строки-аргумента в соответствии со значениями двух последних параметров. Функция UPPER возвращает строку, в которой все строчные буквы строки-аргумента заменяются прописными. Функция LOWER, наоборот, заменяет в заданной строке все прописные буквы строчными. Функция определения длины (CHARACTER_LENGTH, OCTET_LENGTH, BIT_LENGTH) возвращает длину заданной символьной строки в символах, октетах или битах (в зависимости от вида вычисляющей функции) в виде целого числа. Функция определения позиции (POSITION) определяет первую позицию в строке S, с которой в нее входит заданная строка S1 (если не входит, то возвращается значение нуль).
Тип CHARACTER LARGE OBJECT. Этот тип данных предназначен для определения столбцов, хранящих большие и разные по размеру группы символов. При определении столбца задается спецификация CLOB (z), где z задает максимальный размер соответствующей группы символов. Максимально возможное значение параметра z определяется в реализации, но, очевидно, что оно должно быть существенно больше максимально возможного значения параметра x, присутствующего в типах CHAR и CHAR VARYING.7) Литералы типов символьных строк представляются в виде последовательностей символов, заключенных в одинарные или двойные кавычки. В первом случае среди набора символов литерала допускается наличие символов двойной кавычки, а во втором – символов одинарной кавычки. Примеры литералов символьных строк: ’ABCDEF’, ’Ab"Ctd’, "Fbcdef", "ab’cdtF".
Типы символьных строк
В SQL определены три параметризуемых типа символьных строк: CHARACTER (или CHAR), CHARACTER VARYING (или CHAR VARYING, или VARCHAR) и CHARACTER LARGE OBJECT (или CLOB).10)
Тип CHARACTER. Значениями типа являются символьные строки. Конкретный набор допустимых символов определяется в реализации, но, как правило, включает набор символов ASCII. При определении столбца допускается использование спецификаций CHARACTER (x) и просто CHARACTER. Последний вариант эквивалентен заданию CHARACTER (1). После определения столбца типа CHARACTER (x) СУБД будет резервировать место для хранения x символов этого столбца во всех строках соответствующей таблицы. Если, например, определен столбец типа CHARACTER (8) и в некоторой строке таблицы в него заносится символьная строка длиной пять символов, то реально будут храниться восемь символов, последние три из которых будут пробелами11).Тип CHARACTER VARYING. При определении столбца допускается использование спецификаций CHARACTER VARYING (x) и просто CHARACTER VARYING. Последний вариант эквивалентен заданию CHARACTER VARYING (1). Если в некоторой таблице определяется столбец типа CHARACTER VARYING (x), то в каждой строке этой таблицы значения данного столбца будут занимать ровно столько места, сколько требуется для сохранения соответствующей символьной строки (но ни одна такая строка не может состоять более чем из x символов).12) Определен ряд операций, которые можно выполнять над символьными строками. Перечислим некоторые из них. Операция конкатенации (обозначается в виде «||») возвращает символьную строку, произведенную путем соединения строк-операндов в том порядке, в каком они заданы. Функция выделения подстроки (SUBSTRING) принимает три аргумента – строку, номер начальной позиции и длину – и возвращает строку, выделенную из строки-аргумента в соответствии со значениями двух последних параметров. Функция UPPER возвращает строку, в которой все строчные буквы строки-аргумента заменяются прописными. Функция LOWER, наоборот, заменяет в заданной строке все прописные буквы строчными. Функция определения длины (CHARACTER_LENGTH, OCTET_LENGTH, BIT_LENGTH) возвращает длину заданной символьной строки в символах, октетах или битах (в зависимости от вида вычисляющей функции) в виде целого числа. Функция определения позиции (POSITION) определяет первую позицию в строке S, с которой в нее входит заданная строка S1 (если не входит, то возвращается значение нуль).
Тип CHARACTER LARGE OBJECT. Этот тип данных предназначен для определения столбцов, хранящих большие и разные по размеру группы символов. При определении столбца задается спецификация CLOB (z), где z задает максимальный размер соответствующей группы символов. Максимально возможное значение параметра z определяется в реализации, но, очевидно, что оно должно быть существенно больше максимально возможного значения параметра x, присутствующего в типах CHAR и CHAR VARYING.13) Литералы типов символьных строк представляются в виде последовательностей символов, заключенных в одинарные или двойные кавычки. В первом случае среди набора символов литерала допускается наличие символов двойной кавычки, а во втором – символов одинарной кавычки. Примеры литералов символьных строк: ’ABCDEF’, ’Ab"Ctd’, "Fbcdef", "ab’cdtF".
Типы времени
Тип TIME. Значения этого параметризованного типа состоят из компонентов-значений часа, минуты и секунды некоторого времени суток. Значение часа состоит ровно из двух десятичных цифр и варьируется от 00 до 23. Значение минуты состоит из двух десятичных цифр и варьируется от 00 до 59. Основное значение секунды также состоит из двух цифр, но может включать дополнительные цифры, представляющие доли секунды. Так что в целом значение секунды варьируется от 00 до 61.999... В значении времени присутствуют две лишние секунды, поскольку Всемирная служба времени иногда добавляет две секунды к последней минуте года для синхронизации мирового времени с реальным. Решение о поддержке этих «високосных» секунд принимается на уровне реализации. Число цифр в доле секунды также определяется в реализации. В стандарте требуется только то, чтобы это число было не меньше шести. При определении столбца типа TIME может указываться TIME (p) (значение p задает точность долей секунды) или просто TIME (в этом случае доли секунды не учитываются).Литералы типа TIME представляются в виде строки TIME ’hh:mm-ss:f...f’, где символы h, m, s и f должны изображать десятичные числа. Например, литерал TIME ’16:33-20:333’ представляет время суток 16 часов 33 минуты 20 и 333 тысячных секунды.
Типы времени
Тип TIME. Значения этого параметризованного типа состоят из компонентов-значений часа, минуты и секунды некоторого времени суток. Значение часа состоит ровно из двух десятичных цифр и варьируется от 00 до 23. Значение минуты состоит из двух десятичных цифр и варьируется от 00 до 59. Основное значение секунды также состоит из двух цифр, но может включать дополнительные цифры, представляющие доли секунды. Так что в целом значение секунды варьируется от 00 до 61.999... В значении времени присутствуют две лишние секунды, поскольку Всемирная служба времени иногда добавляет две секунды к последней минуте года для синхронизации мирового времени с реальным. Решение о поддержке этих «високосных» секунд принимается на уровне реализации. Число цифр в доле секунды также определяется в реализации. В стандарте требуется только то, чтобы это число было не меньше шести. При определении столбца типа TIME может указываться TIME (p) (значение p задает точность долей секунды) или просто TIME (в этом случае доли секунды не учитываются).Литералы типа TIME представляются в виде строки TIME ’hh:mm-ss:f...f’, где символы h, m, s и f должны изображать десятичные числа. Например, литерал TIME ’16:33-20:333’ представляет время суток 16 часов 33 минуты 20 и 333 тысячных секунды.
Типы времени и временной метки с временной зоной
Тип TIME WITH TIME ZONE. Этот тип данных похож на тип TIME с тем лишь отличием, что значения типа TIME WITH TIME ZONE включают дополнительный компонент — значение, характеризующее смещение соответствующего времени относительно гринвичского времени (теперь его называют UTC – universal time coordinated). Деталей представления этого дополнительного компонента мы касаться не будем.Тип TIMESTAMP WITH TIME ZONE. Этот тип данных отличается от типа TIMESTAMP тем, что значения типа TIMESTAMP WITH TIME ZONE включают дополнительный компонент-значение, характеризующее смещение соответствующего времени относительно гринвичского.
Типы времени и временной метки с временной зоной
Тип TIME WITH TIME ZONE. Этот тип данных похож на тип TIME с тем лишь отличием, что значения типа TIME WITH TIME ZONE включают дополнительный компонент — значение, характеризующее смещение соответствующего времени относительно гринвичского времени (теперь его называют UTC – universal time coordinated). Деталей представления этого дополнительного компонента мы касаться не будем.Тип TIMESTAMP WITH TIME ZONE. Этот тип данных отличается от типа TIMESTAMP тем, что значения типа TIMESTAMP WITH TIME ZONE включают дополнительный компонент-значение, характеризующее смещение соответствующего времени относительно гринвичского.
Типы временной метки
Тип TIMESTAMP. Значения этого параметризованного типа состоят из компонентов — значений года, месяца и дня некоторой даты, а также компонентов — значений часа, минуты и секунды некоторого времени суток (т. е. каждое значение задает некоторую абсолютную временную метку – отсюда название типа TIMESTAMP). Число десятичных цифр в значениях-компонентах и ограничения этих значений такие же, как у значений типов DATE и TIME. При определении столбца типа TIMESTAMP может указываться TIMESTAMP (p) (значение p задает точность долей секунды) или просто TIMESTAMP (в этом случае, в отличие от типа данных TIME, по умолчанию принимается, что в доли секунды используются шесть десятичных цифр). Максимально допустимое значение p определяется в реализации. Литералы типа TIMESTAMP представляются в виде строки TIMESTAMP ’yyyy-mm-dd hh:mm-ss:f...f’, где символы y, m, d, h, m, s и f должны изображать десятичные числа. Например, литерал TIMESTAMP ’1949-04-08 16:33-20:333’ представляет временную метку 16 часов 33 минуты 20 и 333 тысячных секунды 8 апреля 1949 г.
Типы временной метки
Тип TIMESTAMP. Значения этого параметризованного типа состоят из компонентов — значений года, месяца и дня некоторой даты, а также компонентов — значений часа, минуты и секунды некоторого времени суток (т. е. каждое значение задает некоторую абсолютную временную метку – отсюда название типа TIMESTAMP). Число десятичных цифр в значениях-компонентах и ограничения этих значений такие же, как у значений типов DATE и TIME. При определении столбца типа TIMESTAMP может указываться TIMESTAMP (p) (значение p задает точность долей секунды) или просто TIMESTAMP (в этом случае, в отличие от типа данных TIME, по умолчанию принимается, что в доли секунды используются шесть десятичных цифр). Максимально допустимое значение p определяется в реализации. Литералы типа TIMESTAMP представляются в виде строки TIMESTAMP ’yyyy-mm-dd hh:mm-ss:f...f’, где символы y, m, d, h, m, s и f должны изображать десятичные числа. Например, литерал TIMESTAMP ’1949-04-08 16:33-20:333’ представляет временную метку 16 часов 33 минуты 20 и 333 тысячных секунды 8 апреля 1949 г.
Типы временных интервалов
Вообще говоря, временным интервалом называется разность между двумя значениями даты или времени. В SQL определены две категории типов временных интервалов: «год-месяц» и «день-время суток». Временные интервалы языка SQL не привязываются к начальному и/или конечному значению даты/времени, а описывают только протяженность во времени. В общем случае при определении столбца типа временного интервала указывается INTERVAL start (p) [ TO end (q) ], где в качестве «start» и «end» могут задаваться YEAR, MONTH, DAY, HOUR, MINUTE и SECOND. Параметр p задает требуемую точность лидирующего поля интервала (число десятичных цифр). Параметр q может задаваться только в том случае, когда в качестве end используется SECOND, и указывает точность долей секунды. Если говорить более точно, возможны следующие вариации типов временных интервалов.
Типы категории «год-месяц». Можно определить столбцы следующих типов: INTERVAL YEAR, INTERVAL YEAR (p) (значения этих типов – временные интервалы в годах), INTERVAL MONTH, INTERVAL MONTH (p) (значения этих типов – временные интервалы в месяцах), INTERVAL YEAR TO MONTH, INTERVAL YEAR (p) TO MONTH (значения этих типов – временные интервалы в годах и месяцах). Если значение параметра p не указывается явно, по умолчанию принимается его значение «2». Типы категории «день-время суток». При определении столбца можно использовать следующие комбинации (для полноты перечислим все возможности):
INTERVAL DAY (p), INTERVAL DAY, INTERVAL DAY (p) TO HOUR, INTERVAL DAY TO HOUR, INTERVAL DAY (p) TO MINUTE, INTERVAL DAY TO MINUTE, INTERVAL DAY (p) TO SECOND (q), INTERVAL DAY TO SECOND (q), INTERVAL DAY (p) TO SECOND, INTERVAL DAY TO SECOND, INTERVAL HOUR (p), INTERVAL HOUR, INTERVAL HOUR (p) TO MINUTE, INTERVAL HOUR TO MINUTE, INTERVAL HOUR (p) TO SECOND (q), INTERVAL HOUR TO SECOND (q), INTERVAL HOUR TO SECOND, INTERVAL MINUTE (p), INTERVAL MINUTE, INTERVAL MINUTE (p) TO SECOND (q), INTERVAL MINUTE TO SECOND (q), INTERVAL MINUTE (p) TO SECOND, INTERVAL MINUTE TO SECOND, INTERVAL SECOND (p, q), INTERVAL SECOND (p), INTERVAL SECOND.
Типы временных интервалов
Вообще говоря, временным интервалом называется разность между двумя значениями даты или времени. В SQL определены две категории типов временных интервалов: «год-месяц» и «день-время суток». Временные интервалы языка SQL не привязываются к начальному и/или конечному значению даты/времени, а описывают только протяженность во времени. В общем случае при определении столбца типа временного интервала указывается INTERVAL start (p) [ TO end (q) ], где в качестве «start» и «end» могут задаваться YEAR, MONTH, DAY, HOUR, MINUTE и SECOND. Параметр p задает требуемую точность лидирующего поля интервала (число десятичных цифр). Параметр q может задаваться только в том случае, когда в качестве end используется SECOND, и указывает точность долей секунды. Если говорить более точно, возможны следующие вариации типов временных интервалов.
Типы категории «год-месяц». Можно определить столбцы следующих типов: INTERVAL YEAR, INTERVAL YEAR (p) (значения этих типов – временные интервалы в годах), INTERVAL MONTH, INTERVAL MONTH (p) (значения этих типов – временные интервалы в месяцах), INTERVAL YEAR TO MONTH, INTERVAL YEAR (p) TO MONTH (значения этих типов – временные интервалы в годах и месяцах). Если значение параметра p не указывается явно, по умолчанию принимается его значение «2». Типы категории «день-время суток». При определении столбца можно использовать следующие комбинации (для полноты перечислим все возможности):
INTERVAL DAY (p), INTERVAL DAY, INTERVAL DAY (p) TO HOUR, INTERVAL DAY TO HOUR, INTERVAL DAY (p) TO MINUTE, INTERVAL DAY TO MINUTE, INTERVAL DAY (p) TO SECOND (q), INTERVAL DAY TO SECOND (q), INTERVAL DAY (p) TO SECOND, INTERVAL DAY TO SECOND, INTERVAL HOUR (p), INTERVAL HOUR, INTERVAL HOUR (p) TO MINUTE, INTERVAL HOUR TO MINUTE, INTERVAL HOUR (p) TO SECOND (q), INTERVAL HOUR TO SECOND (q), INTERVAL HOUR TO SECOND, INTERVAL MINUTE (p), INTERVAL MINUTE, INTERVAL MINUTE (p) TO SECOND (q), INTERVAL MINUTE TO SECOND (q), INTERVAL MINUTE (p) TO SECOND, INTERVAL MINUTE TO SECOND, INTERVAL SECOND (p, q), INTERVAL SECOND (p), INTERVAL SECOND.
p не указывается явно, по
Если значение параметра p не указывается явно, по умолчанию принимается его значение «2». Значением параметра q по умолчанию является «6». Приведем только один пример литерала одной из разновидностей типа INTERVAL: INTERVAL ’10:20’ MINUTE TO SECOND – временной интервал в 10 минут и 20 секунд.Над значениями темпоральных типов могут выполняться арифметические операции, смысл которых определяется следующей таблицей:
| Datetime | - | Datetime | Interval |
| Datetime | + или - | Interval | Datetime |
| Interval | + | Datetime | Datetime |
| Interval | + или - | Interval | Interval |
| Interval | * или / | Numeric | Interval |
| Numeric | * | Interval | Interval |
Значения типов данных временных интервалов образуются при вычитании одного значения типа даты или времени суток из другого значения соответствующего типа. При добавлении интервального значения к значению типа даты/времени образуется новое значение типа даты/времени. Кроме того, значение интервального типа можно умножать и делить на числовые значения, получая новое значение интервального типа.
p не указывается явно, по
Если значение параметра p не указывается явно, по умолчанию принимается его значение «2». Значением параметра q по умолчанию является «6». Приведем только один пример литерала одной из разновидностей типа INTERVAL: INTERVAL ’10:20’ MINUTE TO SECOND – временной интервал в 10 минут и 20 секунд.Над значениями темпоральных типов могут выполняться арифметические операции, смысл которых определяется следующей таблицей:
| Datetime | - | Datetime | Interval |
| Datetime | + или - | Interval | Datetime |
| Interval | + | Datetime | Datetime |
| Interval | + или - | Interval | Interval |
| Interval | * или / | Numeric | Interval |
| Numeric | * | Interval | Interval |
Значения типов данных временных интервалов образуются при вычитании одного значения типа даты или времени суток из другого значения соответствующего типа. При добавлении интервального значения к значению типа даты/времени образуется новое значение типа даты/времени. Кроме того, значение интервального типа можно умножать и делить на числовые значения, получая новое значение интервального типа.
Tочные числовые типы
К категории точных числовых типов в SQL относятся те типы, значения которых точно представляют числа. Типы данных этой категории распадаются на две части: истинно целые типы (INTEGER и SMALLINT) и типы, допускающие наличие дробной части (NUMERIC и DECIMAL). Охарактеризуем эти типы данных более подробно.
Tочные числовые типы
К категории точных числовых типов в SQL относятся те типы, значения которых точно представляют числа. Типы данных этой категории распадаются на две части: истинно целые типы (INTEGER и SMALLINT) и типы, допускающие наличие дробной части (NUMERIC и DECIMAL). Охарактеризуем эти типы данных более подробно.
Точные типы, допускающие наличие дробной части
Тип NUMERIC. На самом деле, это не просто тип данных, а параметризуемый тип. При определении столбца можно указать спецификацию NUMERIC (p, s), где p и s – литералы истинно целого типа, и p задает точность значений (число сохраняемых бит), а s – шкалу (число десятичных цифр в дробной части). Задаваемая шкала не должна быть отрицательной и не должна превышать значение точности. При определении столбца можно использовать сокращенные формы спецификации типа – NUMERIC и NUMERIC (p). Первая форма предполагает использование точности, определяемое по умолчанию в реализации, и шкалы, равной нулю, а вторая – использование заданной точности и шкалы, равной нулю. Допустимые диапазоны значений p и s определяются в реализации.Тип DECIMAL. Этот тип аналогичен типу NUMERIC. Отличие состоит в том, что если при определении столбца типа DECIMAL задается точность p, то на самом деле используется точность m, определяемая в реализации, такая, что m > p. Шкала всегда устанавливается такой, как явно или неявно (по умолчанию) задается. При указании типа столбца можно использовать спецификации DECIMAL, DECIMAL (p) и DECIMAL (p, s). Литералы типов точных чисел, допускающих наличие дробной части, представляются в виде строк символов, изображающих десятичные числа, в начале которых могут присутствовать символы «+» или «-» (если символ знака отсутствует, подразумевается «+»), а внутри последовательности цифр может присутствовать символ «.». Примеры литералов типов NUMERIC и DECIMAL: 125, 26.36.
Точные типы, допускающие наличие дробной части
Тип NUMERIC. На самом деле, это не просто тип данных, а параметризуемый тип. При определении столбца можно указать спецификацию NUMERIC (p, s), где p и s – литералы истинно целого типа, и p задает точность значений (число сохраняемых бит), а s – шкалу (число десятичных цифр в дробной части). Задаваемая шкала не должна быть отрицательной и не должна превышать значение точности. При определении столбца можно использовать сокращенные формы спецификации типа – NUMERIC и NUMERIC (p). Первая форма предполагает использование точности, определяемое по умолчанию в реализации, и шкалы, равной нулю, а вторая – использование заданной точности и шкалы, равной нулю. Допустимые диапазоны значений p и s определяются в реализации.Тип DECIMAL. Этот тип аналогичен типу NUMERIC. Отличие состоит в том, что если при определении столбца типа DECIMAL задается точность p, то на самом деле используется точность m, определяемая в реализации, такая, что m > p. Шкала всегда устанавливается такой, как явно или неявно (по умолчанию) задается. При указании типа столбца можно использовать спецификации DECIMAL, DECIMAL (p) и DECIMAL (p, s). Литералы типов точных чисел, допускающих наличие дробной части, представляются в виде строк символов, изображающих десятичные числа, в начале которых могут присутствовать символы «+» или «-» (если символ знака отсутствует, подразумевается «+»), а внутри последовательности цифр может присутствовать символ «.». Примеры литералов типов NUMERIC и DECIMAL: 125, 26.36.
В начале лекции мы представим
В начале лекции мы представим небольшой исторический обзор SQL. Язык уже далеко не молод. В 2004 г. сообщество баз данных отмечает его 30-летний юбилей. Поэтому, чтобы правильно понимать и трактовать современные варианты SQL, нужно знать историю языка хотя бы в общих чертах.
В начале лекции мы представим
В начале лекции мы представим небольшой исторический обзор SQL. Язык уже далеко не молод. В 2004 г. сообщество баз данных отмечает его 30-летний юбилей. Поэтому, чтобы правильно понимать и трактовать современные варианты SQL, нужно знать историю языка хотя бы в общих чертах.
В этой лекции мы начали
В этой лекции мы начали рассматривать средства языка SQL, позволяющие определять и динамически изменять схему базы данных. Наиболее важным для общего понимания языка является раздел «Типы данных SQL» – система типов языка SQL (и любой SQL-ориентированной базы данных). В последних стандартах языка SQL поддерживаются:
развитый набор предопределенных типов, включая ряд параметризованных типов;генераторы типов массивов и мультимножеств, элементами которых могут быть значения предопределенных типов, типов коллекций, анонимных строчных типов строк и типов, определенных пользователями;генератор анонимных строчных типов, в которых типом элемента строки может быть любой предопределенный тип, тип коллекции, анонимный строчный тип и тип, определенный пользователями;определяемый пользователем структурный тип, в котором типом элемента структуры может быть любой предопределенный тип, тип коллекции, анонимный строчный тип и тип, определенный пользователями; для определяемых пользователем структурных и индивидуальных типов можно определять пользовательские операции.
Нельзя с уверенностью сказать, что система типов языка SQL настолько полна, что может удовлетворить любые потребности, но можно отметить, что в этой системе типов отсутствует единый логический подход и имеется избыточность. Возможно, это станет понятнее после обсуждения в конце курса средств объектно-реляционных расширений языка SQL.
Как должно быть ясно из этой лекции, механизм доменов в SQL играет вспомогательную роль. Это не совсем те (может быть, и совсем не те) домены, поддержка которых предполагается реляционной моделью. Фактически определение домена обеспечивает спецификацию ограничений и значений по умолчанию, выносимых за пределы определения столбца. В комитете по стандартизации SQL обсуждается идея полного отказа от поддержки механизма доменов и замены его на соответствующим образом адаптированный механизм индивидуальных типов (см. последнюю лекцию курса).
В этой лекции мы начали
В этой лекции мы начали рассматривать средства языка SQL, позволяющие определять и динамически изменять схему базы данных. Наиболее важным для общего понимания языка является раздел «Типы данных SQL» – система типов языка SQL (и любой SQL-ориентированной базы данных). В последних стандартах языка SQL поддерживаются:
развитый набор предопределенных типов, включая ряд параметризованных типов;генераторы типов массивов и мультимножеств, элементами которых могут быть значения предопределенных типов, типов коллекций, анонимных строчных типов строк и типов, определенных пользователями;генератор анонимных строчных типов, в которых типом элемента строки может быть любой предопределенный тип, тип коллекции, анонимный строчный тип и тип, определенный пользователями;определяемый пользователем структурный тип, в котором типом элемента структуры может быть любой предопределенный тип, тип коллекции, анонимный строчный тип и тип, определенный пользователями; для определяемых пользователем структурных и индивидуальных типов можно определять пользовательские операции.
Нельзя с уверенностью сказать, что система типов языка SQL настолько полна, что может удовлетворить любые потребности, но можно отметить, что в этой системе типов отсутствует единый логический подход и имеется избыточность. Возможно, это станет понятнее после обсуждения в конце курса средств объектно-реляционных расширений языка SQL.
Как должно быть ясно из этой лекции, механизм доменов в SQL играет вспомогательную роль. Это не совсем те (может быть, и совсем не те) домены, поддержка которых предполагается реляционной моделью. Фактически определение домена обеспечивает спецификацию ограничений и значений по умолчанию, выносимых за пределы определения столбца. В комитете по стандартизации SQL обсуждается идея полного отказа от поддержки механизма доменов и замены его на соответствующим образом адаптированный механизм индивидуальных типов (см. последнюю лекцию курса).
 |
|
|
1)
В этом абзаце применяется терминология, которая использовалась в публикациях, посвященных System R.
Как это ни странно, компания
2)
Как это ни странно, компания IBM, имевшая уникальный и положительный опыт реализации экспериментальной реляционной СУБД System R, не стала первой компанией, выпустившей на рынок коммерческую реляционную СУБД. Компанию IBM опередила на два года незадолго до того образованная компания Oracle, выпустившая свою первую систему в 1979 г. Современные эксперты по разному объясняют причины этой «заторможенности» IBM, но, по всей видимости, основная причина кроется в традиционном консерватизме руководства компании.
3)
Например, одной из выигрышных черт SQL System R являлось то, что в одной транзакции разрешалось комбинировать все возможные операторы SQL. Поскольку технически это обеспечить достаточно трудно, почти во всех сегодняшних SQL-ориентированных СУБД имеются ограничения на состав операторов, которые можно выполнять в одной транзакции.
4)
Это практически обесценивает стандарт с точки зрения программистов приложений баз данных, поскольку не дает возможности создавать приложения, не привязанные к особенностям конкретных СУБД.
5)
Среди прочих достижений System R нельзя не отметить то, что в базах данных, управляемых этой СУБД, хранились как данные, так и метаданные – описатели отношений, их полей, представлений, ограничения целостности и т.д. Для хранения метаданных использовались специальные служебные отношения, которые стали называть отношениями-каталогами. Из отношений-каталогов можно было выбрать данные с помощью обычных средств языка SQL. Конечно, организация служебных данных – это вопрос реализации SQL, но этот вопрос непосредственно касается потенциальных пользователей SQL-ориентированных СУБД, и поэтому стандартизация представления пользователю отношений-каталогов (в стандарте SQL, информационной схемы базы данных) является исключительно важным делом.
6)
К сожалению, приходится использовать термин строка в двух смыслах: строка таблицы (table row) и символьная или битовая строка (character or bit string). Постараемся обеспечить правильное понимание смысла термина в контексте его использования.
Спецификация предопределенного типа данных битовых
7)
Спецификация предопределенного типа данных битовых строк была удалена в стандарте SQL:2003. Но поскольку эта спецификация повилась только в SQL:1999, мы сочли уместным оставить в курсе обсуждение этого типа данных.
8)
См. ниже Булевский тип.
9)
Следует подчеркнуть, что в стандарте SQL не определяется число байт, занимаемых при хранении в памяти значений целых типов. Не следует думать, что в SQL для хранения значения типа INTEGER требуется четыре байта, а SMALLINT требует двух байтов.
10)
В контексте локализации SQL-ориентированной СУБД (средства локализации входят в стандарт языка) можно определить еще три типа символьных строк – NATIONAL CHARACTER, NATIONAL CHARACTER VARYING и NATIONAL CHARACTER LARGE OBJECT. Аспекты интернационализации и локализации составляют отдельное измерение языка и не обсуждаются в данном курсе.
11)
Именно пробелами, а не «пустыми» символами!
12)
Максимально допустимая длина строк постоянного и переменного размера (значение параметра x) определяется в реализации.
13)
Поскольку значения z могут быть очень большими, допускается сокращенная форма их задания в виде nK, nM и nG, где n – положительное целое число, а K, M и G означают кило, мега и гига соответственно.
14)
В литерале BLOB всегда должно содержаться четное число шестнадцатиричных цифр.
15)
Конечно, на практике такие ограничения устанавливаются в документации конкретной используемой СУБД, либо даже администратором конкретной базы данных.
16)
В тексте стандарта SQL:1999 используется термин anonymous row type. Следуя соглашениям предыдущего пункта, мы должны были бы использовать термин анонимные типы строк. Но тогда уж точно возникла бы путаница с типами символьных строк. Конечно, можно было бы радикально отказаться от использования термина строка таблицы и вернуться к кортежам отношений. Но, к сожалению, этого сделать нельзя, покольку в SQL таблицы – это не совсем (а иногда и совсем не) отношения, а строки таблиц – не совсем (совсем не) кортежи.
Соответствующие определения сохраняются как часть
17)
Соответствующие определения сохраняются как часть метаданных базы данных (другими словами, являются частью схемы базы данных).
18)
Требуется, чтобы в определении структурного типа A использовались только те типы, которые были определены ранее.
19)
Начиная с этого места мы будем приводить более или менее точный синтаксис конструкций языка SQL (не злоупотребляя излишествами). Без этого текст был бы менее точным и более объемным. Прописными буквами показываются «терминалы» – ключевые слова языка SQL.
20)
Здесь мы в первый раз сталкиваемся с именем объекта базы данных. Не будем углублять ся в детали, но в общем случае имена объектов SQL-ориентированных баз данных имеют вид имя_каталога.имя_схемы.имя_объекта. Этот подход к именованию объектов базы данных позволяет независимо создавать объекты в разных схемах, не заботясь о том, чтобы эти объекты имели разные простые имена. При использовании в операторе SQL простого имени объекта система должна автоматически уточнить это имя, исходя из идентификатора пользователя, от имени которого выполняется оператор.
21)
Это значение будет использоваться в качестве значения по умолчанию для любого столбца, определенного на данном домене, для которого не определено собственное значение по умолчанию (см. следующую лекцию).
22)
{ element1, | element2, |…| elementn } означает, что в данной синтаксической конструкции должен присутствовать один и только один elementi.
23)
Значение niladic_function «вычисляется» в тот момент, когда требуется значение по умолчанию (обычно при вставке в таблицу новой строки, значение соответствующего столбца которой явно не указано). Смысл CURRENT_DATE, CURRENT_TIME и CURRENT_TIMESTAMP очевиден. USER (или, что то же, CURRENT USER), SESSION_USER и SYSTEM_USER задают идентификатор пользователя, от имени которого выполняется текущая транзакция, текущая сессия, и идентификатор операционной системы, в которой работает пользователь, соответственно. В стандарте не определяется представление этих идентификаторов, но в реализациях они обычно представляются в виде символьных строк.
24)
Более подробно мы обсудим допустимые в SQL виды условных выражений в следующих лекциях.
| © 2003-2007 INTUIT.ru. Все права защищены. |