Агрегатная функция GROUPING
Обсудим теперь один более тонкий вопрос. Как говорилось в лекции 12, определение столбцов DEPT_NO и EMP_BDATE таблицы EMP допускает появление в этих столбцах неопределенных значений. Поэтому тело таблицы EMP могло бы иметь, например, следующий вид:
| 2440 | 1 | 1950 | 15000.00 |
| 2441 | 1 | 1950 | 16000.00 |
| 2442 | 1 | 1960 | 14000.00 |
| 2443 | 1 | 1960 | 19000.00 |
| 2452 | 1 | NULL | 15000.00 |
| 2453 | 1 | NULL | 17000.00 |
| 2444 | 2 | 1950 | 17000.00 |
| 2445 | 2 | 1950 | 16000.00 |
| 2446 | 2 | 1960 | 14000.00 |
| 2447 | 2 | 1960 | 20000.00 |
| 2448 | 3 | 1950 | 18000.00 |
| 2449 | 3 | 1950 | 13000.00 |
| 2450 | 3 | 1960 | 21000.00 |
| 2451 | 3 | 1960 | 22000.00 |
| 2454 | NULL | 1950 | 13000.00 |
| 2455 | NULL | 1950 | 14000.00 |
| 2456 | NULL | NULL | 19000.00 |
Тогда результат запроса из примера 16.1 имел бы следующий вид1):

Рис. 16.2. Результат запроса с разделом GROUP BY ROLLUP к таблице с неопределенными значениями столбцов группировки
Очевидно, что, просматривая строки таблицы, показанной на рис.16.2, невозможно установить, в какой из первых трех строк неопределенное значение столбцов DEPT_NO и EMP_BDATE означает то, что эта строка является сводной для всего предприятия, а не то, что она является сводной для всех сотрудников с неизвестными номером отдела и годом рождения или просто для всех сотрудников с неизвестным номером отдела. Аналогичным образом невозможно понять, какая строка в следующей далее паре строк является сводной для всех сотрудников отдела номер 1, а не для всех сотрудников отдела номер 1 с неизвестным годом рождения.
Для того чтобы всегда можно было разобраться в результатах запросов, включающих раздел GROUP BY ROLLUP, в язык SQL была введена специальная агрегатная функция GROUPING. Эта функция применяется к столбцу, входящему в список столбцов раздела GROUP BY ROLLUP, и принимает целое значение 1 в тех строках результирующей таблицы, в которых соответствующий столбец имеет значение NULL по той причине, что строка является сводной для более обобщенной группы. В противном случае функция GROUPING принимает значение 0.
Уточним формулировку запроса из примера 16.1 (пример 16.1a):
Агрегатная функция GROUPING
Обсудим теперь один более тонкий вопрос. Как говорилось в лекции 12, определение столбцов DEPT_NO и EMP_BDATE таблицы EMP допускает появление в этих столбцах неопределенных значений. Поэтому тело таблицы EMP могло бы иметь, например, следующий вид:
| 2440 | 1 | 1950 | 15000.00 |
| 2441 | 1 | 1950 | 16000.00 |
| 2442 | 1 | 1960 | 14000.00 |
| 2443 | 1 | 1960 | 19000.00 |
| 2452 | 1 | NULL | 15000.00 |
| 2453 | 1 | NULL | 17000.00 |
| 2444 | 2 | 1950 | 17000.00 |
| 2445 | 2 | 1950 | 16000.00 |
| 2446 | 2 | 1960 | 14000.00 |
| 2447 | 2 | 1960 | 20000.00 |
| 2448 | 3 | 1950 | 18000.00 |
| 2449 | 3 | 1950 | 13000.00 |
| 2450 | 3 | 1960 | 21000.00 |
| 2451 | 3 | 1960 | 22000.00 |
| 2454 | NULL | 1950 | 13000.00 |
| 2455 | NULL | 1950 | 14000.00 |
| 2456 | NULL | NULL | 19000.00 |
Тогда результат запроса из примера 16.1 имел бы следующий вид2):
Рис. 16.2. Результат запроса с разделом GROUP BY ROLLUP к таблице с неопределенными значениями столбцов группировки
Очевидно, что, просматривая строки таблицы, показанной на рис.16.2, невозможно установить, в какой из первых трех строк неопределенное значение столбцов DEPT_NO и EMP_BDATE означает то, что эта строка является сводной для всего предприятия, а не то, что она является сводной для всех сотрудников с неизвестными номером отдела и годом рождения или просто для всех сотрудников с неизвестным номером отдела. Аналогичным образом невозможно понять, какая строка в следующей далее паре строк является сводной для всех сотрудников отдела номер 1, а не для всех сотрудников отдела номер 1 с неизвестным годом рождения.
Для того чтобы всегда можно было разобраться в результатах запросов, включающих раздел GROUP BY ROLLUP, в язык SQL была введена специальная агрегатная функция GROUPING. Эта функция применяется к столбцу, входящему в список столбцов раздела GROUP BY ROLLUP, и принимает целое значение 1 в тех строках результирующей таблицы, в которых соответствующий столбец имеет значение NULL по той причине, что строка является сводной для более обобщенной группы. В противном случае функция GROUPING принимает значение 0.
Уточним формулировку запроса из примера 16.1 (пример 16.1a):
AS GEB FROM EMP GROUP
SELECT DEPT_NO, EMP_BDATE, MAX (EMP_SAL) AS MAX_SAL, GROUPING (DEPT_NO) AS GDN, GROUPING (EMP_BDATE) AS GEB FROM EMP GROUP BY ROLLUP (DEPT_NO, EMP_BDATE);
Пример 16.1a.
(html, txt)
Результирующая таблица для этого запроса будет иметь следующий вид:
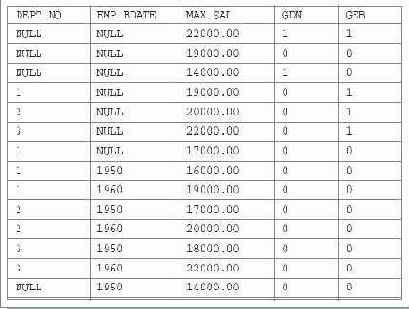
Рис. 16.3. Результат запроса с разделом GROUP BY ROLLUP и вызовами агрегатной функции GROUPING к таблице с неопределенными значениями столбцов группировки
Анализируя значения столбцов GDN и GEB в строках таблицы, показанной на рис.16.4, можно убедиться, что значение столбца MAX_SAL в первой строке является максимальным значением зарплаты всех служащих предприятия, во второй строке - максимальным значением зарплаты служащих с неизвестными номером отдела и годом рождения, а в третьей строке - максимальным значением зарплаты всех служащих с неизвестным номером отдела. В следующих трех строках значения столбца MAX_SAL являются максимальными значениями зарплаты сотрудников с неизвестным годом рождения из отделов с номерами 1, 2 и 3 соответственно. Как видно, значения столбцов GDN и GEB являются своего рода индикаторами, указывающими на природу основных значений строки.
AS GEB FROM EMP GROUP
SELECT DEPT_NO, EMP_BDATE, MAX (EMP_SAL) AS MAX_SAL, GROUPING (DEPT_NO) AS GDN, GROUPING (EMP_BDATE) AS GEB FROM EMP GROUP BY ROLLUP (DEPT_NO, EMP_BDATE);
Пример 16.1a.
Результирующая таблица для этого запроса будет иметь следующий вид:
Рис. 16.3. Результат запроса с разделом GROUP BY ROLLUP и вызовами агрегатной функции GROUPING к таблице с неопределенными значениями столбцов группировки
Анализируя значения столбцов GDN и GEB в строках таблицы, показанной на рис.16.4, можно убедиться, что значение столбца MAX_SAL в первой строке является максимальным значением зарплаты всех служащих предприятия, во второй строке - максимальным значением зарплаты служащих с неизвестными номером отдела и годом рождения, а в третьей строке - максимальным значением зарплаты всех служащих с неизвестным номером отдела. В следующих трех строках значения столбца MAX_SAL являются максимальными значениями зарплаты сотрудников с неизвестным годом рождения из отделов с номерами 1, 2 и 3 соответственно. Как видно, значения столбцов GDN и GEB являются своего рода индикаторами, указывающими на природу основных значений строки.
мы показали строки результирующей таблицы,
| Конечно, мы показали строки результирующей таблицы, расположенные в удобном для нас порядке только для упрощения объяснений. В действительности, строки результирующей таблицы (как обычно) будут расположены в порядке, определяемом системой. Чтобы добиться в точности такого порядка расположения строк, как это показано на рис.16.1, к формулировке запроса из примера 16.1 нужно добавить раздел ORDER BY DEPT_NO, EMP_BDATE. |
| Закрыть окно |
Мы опять искусственным образом упорядочили
| Мы опять искусственным образом упорядочили результат запроса для удобства пояснений. |
| Закрыть окно |
Определения, относящиеся к рекурсии
Обход дерева в ширину. При этом способе обхода непосредственные потомки обходятся слева направо, до того как производится переход к потомкам следующего уровня родства.
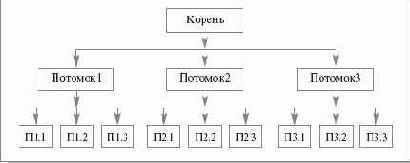
Рис. 16.5. Пример дерева
При обходе в ширину дерева, показанного на рис.16.5, узлы будут обходиться в следующем порядке: Корень-Потомок1-Потомок2-Потомок3-П1.1-П1.2-П1.3-П2.1-П2.3-П3.1-П3.2-П3.3.
Обход дерева в глубину. При этом способе обхода на каждом шаге производится переход к самому левому текущему потомку. При обходе в глубину дерева с рис.16.5 порядок обхода узлов будет следующим: Корень-Потомок1-П1.1-П1.2-П1.3-Потомок2-П2.1-П2.2-П2.3-Потомок3-П3.1-П3.2-П3.3.
Цикл в ориентированном графе. В теории графов ориентированный граф называется циклическим в том и только в том случае, когда хотя бы один узел графа одновременно является и предком, и потомком (т. е. для этого узла имеется и выходящая, и входящая дуги). В SQL:1999 узлами графа рекурсии являются строки, входящие в результат рекурсивного запроса, а дуги соответствуют способам обработки текущих строк, которые ведут к добавлению к результату новых строк. На рис.16.6 показан простейший пример ориентированного графа с циклом.

Рис. 16.6. Пример графа с циклом
Прямая рекурсия. По определению, некоторый элемент использует прямую рекурсию в том и только в том случае, когда он обращается сам к себе без посредников. Пример, приведенный на рис.16.6, демонстрирует (в графовой форме) прямую рекурсию. На рис.16.7 показан графовый пример непрямой рекурсии.
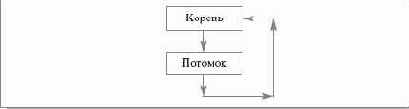
Рис. 16.7. Графовый пример непрямой рекурсии
Линейная рекурсия. При линейно рекурсивном вызове элемент прямо рекурсивно обращается сам к себе не более одного раза. В SQL:1999 в определении любой виртуальной таблицы с рекурсией допускается не более одной ссылки на саму себя (в разделе FROM и/или в подзапросах). На рис.16.8 показан графовый пример рекурсии, не являющейся линейной.
Монотонность. Монотонной прогрессией называется последовательность неубывающих или невозрастающих значений. Например, последовательность натуральных чисел {1, 2, ... , n, ...} является монотонной. В SQL:1999 свойство монотонности поддерживается в том смысле, что число строк результата рекурсивного запроса не уменьшается на каждом шаге рекурсии.
Взаимная рекурсия. Элементы A и B связаны отношением взаимной рекурсии, если A прямо или косвенно вызывает B, и B прямо или косвенно вызывает A. На рис.16.9 показан графовый пример взаимной рекурсии (элемент A вызывает элемент B через элемент C, а элемент B вызывает элемент A через элемент D).

Рис. 16.8. Графовый пример нелинейной рекурсии

Рис. 16.9. Графовый пример взаимной рекурсии
Отрицание. В контексте SQL отрицанием называется любое действие, приводящее к уменьшению числа строк в результате запроса. Свойствами отрицания обладают операции над (мульти)множествами EXCEPT и INTERSECT, спецификация DISTINCT, условие NOT EXISTS и т.д. В стандарте SQL не запрещается использование отрицания в рекурсивных запросах. Возможной проблемы нарушения монотонности удается избежать за счет того, что отрицание разрешается применять только к тем таблицам, которые являются полностью известными (или вычисленными) к моменту применения отрицания. В процессе вычисления таблицы применение к ней отрицания не допускается.
Начальный источник рекурсии. При выполнении рекурсивных вычислений обычно (хотя и не всегда) имеется некоторое начальное значение. В SQL этим начальным источником рекурсии является одна или несколько строк, удовлетворяющих некоторым начальным условиям. На основе этих строк в процессе рекурсивного вычисления производятся дополнительные строки, образующие окончательный результат.
Стратификация. В SQL рекурсивный запрос обычно состоит из "рекурсивной" и "нерекурсивной" частей. В процессе стратификации ("расслоения") запроса выполнение этих двух частей разделяется. В более сложных рекурсивных запросах может содержаться несколько рекурсивных частей и более одной нерекурсивной части. В этом случае в процессе стратификации будет обнаружено большее число слоев.
Семантика фиксированной точки. В контексте SQL:1999 семантика фиксированной точки означает, что решение о завершении рекурсивного запроса принимается тогда, когда становится невозможно добавить к результату какие-либо дополнительные строки.
Определения, относящиеся к рекурсии
Обход дерева в ширину. При этом способе обхода непосредственные потомки обходятся слева направо, до того как производится переход к потомкам следующего уровня родства.
Рис. 16.5. Пример дерева
При обходе в ширину дерева, показанного на рис.16.5, узлы будут обходиться в следующем порядке: Корень-Потомок1-Потомок2-Потомок3-П1.1-П1.2-П1.3-П2.1-П2.3-П3.1-П3.2-П3.3.
Обход дерева в глубину. При этом способе обхода на каждом шаге производится переход к самому левому текущему потомку. При обходе в глубину дерева с рис.16.5 порядок обхода узлов будет следующим: Корень-Потомок1-П1.1-П1.2-П1.3-Потомок2-П2.1-П2.2-П2.3-Потомок3-П3.1-П3.2-П3.3.
Цикл в ориентированном графе. В теории графов ориентированный граф называется циклическим в том и только в том случае, когда хотя бы один узел графа одновременно является и предком, и потомком (т. е. для этого узла имеется и выходящая, и входящая дуги). В SQL:1999 узлами графа рекурсии являются строки, входящие в результат рекурсивного запроса, а дуги соответствуют способам обработки текущих строк, которые ведут к добавлению к результату новых строк. На рис.16.6 показан простейший пример ориентированного графа с циклом.
Рис. 16.6. Пример графа с циклом
Прямая рекурсия. По определению, некоторый элемент использует прямую рекурсию в том и только в том случае, когда он обращается сам к себе без посредников. Пример, приведенный на рис.16.6, демонстрирует (в графовой форме) прямую рекурсию. На рис.16.7 показан графовый пример непрямой рекурсии.
Рис. 16.7. Графовый пример непрямой рекурсии
Линейная рекурсия. При линейно рекурсивном вызове элемент прямо рекурсивно обращается сам к себе не более одного раза. В SQL:1999 в определении любой виртуальной таблицы с рекурсией допускается не более одной ссылки на саму себя (в разделе FROM и/или в подзапросах). На рис.16.8 показан графовый пример рекурсии, не являющейся линейной.
Монотонность. Монотонной прогрессией называется последовательность неубывающих или невозрастающих значений. Например, последовательность натуральных чисел {1, 2, ... , n, ...} является монотонной. В SQL:1999 свойство монотонности поддерживается в том смысле, что число строк результата рекурсивного запроса не уменьшается на каждом шаге рекурсии.
Взаимная рекурсия. Элементы A и B связаны отношением взаимной рекурсии, если A прямо или косвенно вызывает B, и B прямо или косвенно вызывает A. На рис.16.9 показан графовый пример взаимной рекурсии (элемент A вызывает элемент B через элемент C, а элемент B вызывает элемент A через элемент D).
Рис. 16.8. Графовый пример нелинейной рекурсии
Рис. 16.9. Графовый пример взаимной рекурсии
Отрицание. В контексте SQL отрицанием называется любое действие, приводящее к уменьшению числа строк в результате запроса. Свойствами отрицания обладают операции над (мульти)множествами EXCEPT и INTERSECT, спецификация DISTINCT, условие NOT EXISTS и т.д. В стандарте SQL не запрещается использование отрицания в рекурсивных запросах. Возможной проблемы нарушения монотонности удается избежать за счет того, что отрицание разрешается применять только к тем таблицам, которые являются полностью известными (или вычисленными) к моменту применения отрицания. В процессе вычисления таблицы применение к ней отрицания не допускается.
Начальный источник рекурсии. При выполнении рекурсивных вычислений обычно (хотя и не всегда) имеется некоторое начальное значение. В SQL этим начальным источником рекурсии является одна или несколько строк, удовлетворяющих некоторым начальным условиям. На основе этих строк в процессе рекурсивного вычисления производятся дополнительные строки, образующие окончательный результат.
Стратификация. В SQL рекурсивный запрос обычно состоит из "рекурсивной" и "нерекурсивной" частей. В процессе стратификации ("расслоения") запроса выполнение этих двух частей разделяется. В более сложных рекурсивных запросах может содержаться несколько рекурсивных частей и более одной нерекурсивной части. В этом случае в процессе стратификации будет обнаружено большее число слоев.
Семантика фиксированной точки. В контексте SQL:1999 семантика фиксированной точки означает, что решение о завершении рекурсивного запроса принимается тогда, когда становится невозможно добавить к результату какие-либо дополнительные строки.
AS MAX_SAL FROM EMP GROUP
| SELECT DEPT_NO, EMP_BDATE, MAX (EMP_SAL) AS MAX_SAL FROM EMP GROUP BY ROLLUP (DEPT_NO, EMP_BDATE); |
| Пример 16.1. |
| Закрыть окно |
SELECT DEPT_NO, EMP_BDATE, MAX
SELECT DEPT_NO, EMP_BDATE, MAX (EMP_SAL) AS MAX_SAL
FROM EMP
GROUP BY ROLLUP (DEPT_NO, EMP_BDATE);
AS GEB FROM EMP GROUP
| SELECT DEPT_NO, EMP_BDATE, MAX (EMP_SAL) AS MAX_SAL, GROUPING (DEPT_NO) AS GDN, GROUPING (EMP_BDATE) AS GEB FROM EMP GROUP BY ROLLUP (DEPT_NO, EMP_BDATE); |
| Пример 16.1a. |
| Закрыть окно |
SELECT DEPT_NO, EMP_BDATE, MAX
SELECT DEPT_NO, EMP_BDATE, MAX (EMP_SAL) AS MAX_SAL,
GROUPING (DEPT_NO) AS GDN, GROUPING (EMP_BDATE)
AS GEB
FROM EMP
GROUP BY ROLLUP (DEPT_NO, EMP_BDATE);
AS GEB FROM EMP GROUP
| SELECT DEPT_NO, EMP_BDATE, MAX (EMP_SAL)AS MAX_SAL, GROUPING (DEPT_NO) AS GDN, GROUPING (EMP_BDATE) AS GEB FROM EMP GROUP BY CUBE (DEPT_NO, EMP_BDATE); |
| Пример 16.2. Найти максимальный размер зарплаты во всем предприятии, максимальный размер зарплаты в каждом отделе, максимальный размер зарплаты сотрудников в каждой возрастной категории и максимальный размер зарплаты сотрудников каждой возрастной категории каждого отдела. |
| Закрыть окно |
SELECT DEPT_NO, EMP_BDATE, MAX
SELECT DEPT_NO, EMP_BDATE, MAX (EMP_SAL)AS MAX_SAL,
GROUPING (DEPT_NO) AS GDN, GROUPING (EMP_BDATE) AS GEB
FROM EMP
GROUP BY CUBE (DEPT_NO, EMP_BDATE);
PART_COST FROM CAR, PARTS WHERE
| WITH RECURSIVE PARTS (PART_NUMBER, NUMBER_OF_PARTS, COST) AS (SELECT CONTAINED_PART, 1, 0.00 (a) FROM CAR WHERE CONTAINING_PART = '' UNION ALL SELECT CAR.CONTAINED_PART, CAR.NUMBER_OF_PARTS, CAR.NUMBER_OF_PARTS * CAR. PART_COST FROM CAR, PARTS WHERE PARTS.PART_NUMBER = CAR.CONTAINING_PART) SELECT PART_NUMBER, SUM(NUMBER_OF PARTS), SUM(COST) (b) FROM PARTS GROUP BY PART_NUMBER; |
| Пример 16.3. |
| Закрыть окно |
WITH RECURSIVE PARTS
WITH RECURSIVE PARTS (PART_NUMBER,
NUMBER_OF_PARTS, COST) AS
(SELECT CONTAINED_PART, 1, 0.00 (a)
FROM CAR
WHERE CONTAINING_PART = ''
UNION ALL
SELECT CAR.CONTAINED_PART, CAR.NUMBER_OF_PARTS,
CAR.NUMBER_OF_PARTS * CAR.PART_COST
FROM CAR, PARTS
WHERE PARTS.PART_NUMBER = CAR.CONTAINING_PART)
SELECT PART_NUMBER, SUM(NUMBER_OF PARTS),
SUM(COST) (b)
FROM PARTS
GROUP BY PART_NUMBER;
FROM CAR WHERE CONTAINING_PART
| WITH RECURSIVE PARTS (ASSEMBLY, PART_NUMBER, NUMBER_OF_PARTS, COST) AS (SELECT CONTAINING_PART, CONTAINED_PART, 1, 0. 00 FROM CAR WHERE CONTAINING_PART = '' UNION ALL SELECT CAR.CONTAINING_PART, CAR.CONTAINED_PART, CAR.NUMBER_OF_PARTS, CAR.NUMBER_OF_PARTS * CAR.PART_COST FROM CAR, PARTS WHERE PARTS.PART_NUMBER = CAR.CONTAINING_PART) SEARCH BREADTH FIRST BY CONTAINING_PART, CONTAINED_PART SET ORDER_COLUMN SELECT PART_NUMBER, NUMBER_OF PARTS, COST FROM PARTS ORDER BY ORDER_COLUMN; |
| Пример 16.4. |
| Закрыть окно |
SELECT CONTAINING_PART, CONTAINED_PART, 1,
WITH RECURSIVE PARTS (ASSEMBLY, PART_NUMBER,
NUMBER_OF_PARTS, COST) AS
( SELECT CONTAINING_PART, CONTAINED_PART, 1, 0.00
FROM CAR
WHERE CONTAINING_PART = ''
UNION ALL
SELECT CAR.CONTAINING_PART, CAR.CONTAINED_PART,
CAR.NUMBER_OF_PARTS, CAR.NUMBER_OF_PARTS *
CAR.PART_COST
FROM CAR, PARTS
WHERE PARTS.PART_NUMBER = CAR.CONTAINING_PART)
SEARCH BREADTH FIRST
BY CONTAINING_PART, CONTAINED_PART
SET ORDER_COLUMN
SELECT PART_NUMBER, NUMBER_OF PARTS, COST
FROM PARTS
ORDER BY ORDER_COLUMN;
FROM CAR WHERE CONTAINING_PART
| WITH RECURSIVE PARTS (PART_NUMBER, NUMBER_OF_PARTS, COST) AS (SELECT CONTAINED_PART, 1, 0. 00 FROM CAR WHERE CONTAINING_PART = '' UNION ALL SELECT CAR.CONTAINED_PART, CAR.NUMBER_OF_PARTS, CAR.NUMBER_OF_PARTS * CAR.PART_COST FROM CAR, PARTS WHERE PARTS.PART_NUMBER = CAR.CONTAINING_PART) CYRCLE CONTAINED_PART SET CYCLEMARK TO 'Y' DEFAULT 'N' USING CYRCLEPATH SELECT PART_NUMBER, SUM(NUMBER_OF PARTS), SUM(COST) FROM PARTS ORDER BY PART_NUMBER; |
| Пример 16.5. |
| Закрыть окно |
WITH RECURSIVE PARTS
WITH RECURSIVE PARTS (PART_NUMBER,
NUMBER_OF_PARTS, COST) AS
(SELECT CONTAINED_PART, 1, 0.00
FROM CAR
WHERE CONTAINING_PART = ''
UNION ALL
SELECT CAR.CONTAINED_PART, CAR.NUMBER_OF_PARTS,
CAR.NUMBER_OF_PARTS * CAR.PART_COST
FROM CAR, PARTS
WHERE PARTS.PART_NUMBER = CAR.CONTAINING_PART)
CYRCLE CONTAINED_PART
SET CYCLEMARK TO 'Y' DEFAULT 'N'
USING CYRCLEPATH
SELECT PART_NUMBER, SUM(NUMBER_OF PARTS), SUM(COST)
FROM PARTS
ORDER BY PART_NUMBER;
Раздел CYRCLE
Наконец, обсудим, для чего нужен раздел CYRCLE. Дело в том, что иногда сами данные, хранимые в таблицах базы данных, могут иметь циклическую природу. Представим себе, например, компанию, в которой существует совет директоров, являющийся высшим органом управления компанией. Обычным случаем является тот, когда по крайней мере один из членов совета директоров является простым служащим этой же компании (например, он может входить в совет директоров как представитель профсоюза). Назовем данного члена совета директоров EMP_DIR. Как член совета директоров, EMP_DIR "управляет" деятельностью президента компании. С другой стороны, как служащий компании, EMP_DIR находится в прямом или косвенном подчинении у президента компании. Такое положение может привести к зацикливанию выполнения рекурсивных запросов. Раздел CYRCLE обеспечивает некоторую возможность распознавать подобные ситуации. Если у пользователя имеется полная уверенность в отсутствии циклов в данных, к которым адресуется рекурсивный запрос, то использование раздела CYRCLE не требуется.
Подход к распознаванию зацикленных запросов, принятый в SQL, состоит в том, что распознаются данные, которые уже участвовали ранее в формировании результата рекурсивного запроса. При наличии раздела CYRCLE при добавлении к результату строк, удовлетворяющих условию запроса, такие строки помечаются указанным значением, которое означает, что эти строки уже вошли в результат. При попытке добавления к результату каждой новой строки проверяется, не находится ли она уже в результате, т. е. не помечена ли она этим указанным в разделе CYRCLE значением. Если это действительно так, то считается, что имеет место цикл, и дальнейшее выполнение рекурсивного запроса прекращается.
Обсудим все это более формально. Для удобства воспроизведем еще раз синтаксис раздела CYRCLE.
cycle_clause ::= CYCLE cycle_column_name_comma_list SET cycle_mark_column_name TO value_expression_1 DEFAULT value_expression_2 USING path_column_name
В списке cycle_column_name_comma_list указываются имена одного или нескольких столбцов, которые используются для идентификации новых строк результата на основе строк, уже входящих в результат. Например, в примерах 16.3 и 16.4 столбец CONTAINED_PART связывает конструктивный элемент автомобиля с входящими в его состав подэлементами (через значения их столбцов CONTAINING_PART). Раздел SET приводит к образованию нового столбца результирующей таблицы. Для строк, которые попадают в результат первый раз, в столбец cycle_mark_column_name заносится значение выражения value_expression_2. В повторно заносимых строках значение столбца - value_expression_1. Типом данных этого столбца является тип символьных строк длины один, так что в качестве value_expression_1 и value_expression_2 разумно использовать константы '0' и '1' или 'Y' и 'N'.
Раздел USING приводит к образованию еще одного дополнительного столбца результата с именем path_column_name. Типом данных столбца является ARRAY, причем кардинальность этого типа предполагается достаточно большой, чтобы сохранить информацию обо всех строках, попавших в результат. Элементы массива имеют "строчный тип" (row type), содержащий столько столбцов, сколько их указано в списке раздела CYRCLE. Каждый элемент массива соответствует строке результата, и в его столбцах содержится копия значений соответствующих столбцов этой строки. Вот пример запроса, содержащего раздел CYRCLE (пример 16.5):
Раздел CYRCLE
Наконец, обсудим, для чего нужен раздел CYRCLE. Дело в том, что иногда сами данные, хранимые в таблицах базы данных, могут иметь циклическую природу. Представим себе, например, компанию, в которой существует совет директоров, являющийся высшим органом управления компанией. Обычным случаем является тот, когда по крайней мере один из членов совета директоров является простым служащим этой же компании (например, он может входить в совет директоров как представитель профсоюза). Назовем данного члена совета директоров EMP_DIR. Как член совета директоров, EMP_DIR "управляет" деятельностью президента компании. С другой стороны, как служащий компании, EMP_DIR находится в прямом или косвенном подчинении у президента компании. Такое положение может привести к зацикливанию выполнения рекурсивных запросов. Раздел CYRCLE обеспечивает некоторую возможность распознавать подобные ситуации. Если у пользователя имеется полная уверенность в отсутствии циклов в данных, к которым адресуется рекурсивный запрос, то использование раздела CYRCLE не требуется.
Подход к распознаванию зацикленных запросов, принятый в SQL, состоит в том, что распознаются данные, которые уже участвовали ранее в формировании результата рекурсивного запроса. При наличии раздела CYRCLE при добавлении к результату строк, удовлетворяющих условию запроса, такие строки помечаются указанным значением, которое означает, что эти строки уже вошли в результат. При попытке добавления к результату каждой новой строки проверяется, не находится ли она уже в результате, т. е. не помечена ли она этим указанным в разделе CYRCLE значением. Если это действительно так, то считается, что имеет место цикл, и дальнейшее выполнение рекурсивного запроса прекращается.
Обсудим все это более формально. Для удобства воспроизведем еще раз синтаксис раздела CYRCLE.
cycle_clause ::= CYCLE cycle_column_name_comma_list SET cycle_mark_column_name TO value_expression_1 DEFAULT value_expression_2 USING path_column_name
В списке cycle_column_name_comma_list указываются имена одного или нескольких столбцов, которые используются для идентификации новых строк результата на основе строк, уже входящих в результат. Например, в примерах 16.3 и 16.4 столбец CONTAINED_PART связывает конструктивный элемент автомобиля с входящими в его состав подэлементами (через значения их столбцов CONTAINING_PART). Раздел SET приводит к образованию нового столбца результирующей таблицы. Для строк, которые попадают в результат первый раз, в столбец cycle_mark_column_name заносится значение выражения value_expression_2. В повторно заносимых строках значение столбца - value_expression_1. Типом данных этого столбца является тип символьных строк длины один, так что в качестве value_expression_1 и value_expression_2 разумно использовать константы '0' и '1' или 'Y' и 'N'.
Раздел USING приводит к образованию еще одного дополнительного столбца результата с именем path_column_name. Типом данных столбца является ARRAY, причем кардинальность этого типа предполагается достаточно большой, чтобы сохранить информацию обо всех строках, попавших в результат. Элементы массива имеют "строчный тип" (row type), содержащий столько столбцов, сколько их указано в списке раздела CYRCLE. Каждый элемент массива соответствует строке результата, и в его столбцах содержится копия значений соответствующих столбцов этой строки. Вот пример запроса, содержащего раздел CYRCLE (пример 16.5):
FROM CAR WHERE CONTAINING_PART
WITH RECURSIVE PARTS (PART_NUMBER, NUMBER_OF_PARTS, COST) AS (SELECT CONTAINED_PART, 1, 0. 00 FROM CAR WHERE CONTAINING_PART = '' UNION ALL SELECT CAR.CONTAINED_PART, CAR.NUMBER_OF_PARTS, CAR.NUMBER_OF_PARTS * CAR.PART_COST FROM CAR, PARTS WHERE PARTS.PART_NUMBER = CAR.CONTAINING_PART) CYRCLE CONTAINED_PART SET CYCLEMARK TO 'Y' DEFAULT 'N' USING CYRCLEPATH SELECT PART_NUMBER, SUM(NUMBER_OF PARTS), SUM(COST) FROM PARTS ORDER BY PART_NUMBER;
Пример 16.5.
(html, txt)
Имена столбцов CYCLEMARK и CYRCLEPATH выбраны произвольным образом - требуется только, чтобы имена этих столбцов отличались от имен столбцов рекурсивного запроса. При выполнении запроса строки, удовлетворяющие его условию, накапливаются в результирующей таблице. Но, кроме того, эти строки "кэшируются" в столбце CYRCLEPATH. При попытке добавления к результату новой строки на основе текущего содержимого столбца CYRCLEPATH проверяется, не содержится ли она уже в результате. Если не содержится, то данные об этой строке добавляются к столбцу CYRCLEPATH (к массиву добавляется новый элемент), в столбец CYCLEMARK этой строки заносится значение 'N', и строка добавляется к результату. Иначе в столбец CYCLEMARK соответствующей строки результата заносится значение 'Y', означающее, что от этой строки начинается цикл.
Имена столбцов CYCLEMARK
WITH RECURSIVE PARTS (PART_NUMBER, NUMBER_OF_PARTS, COST) AS (SELECT CONTAINED_PART, 1, 0. 00 FROM CAR WHERE CONTAINING_PART = '' UNION ALL SELECT CAR.CONTAINED_PART, CAR.NUMBER_OF_PARTS, CAR.NUMBER_OF_PARTS * CAR.PART_COST FROM CAR, PARTS WHERE PARTS.PART_NUMBER = CAR.CONTAINING_PART) CYRCLE CONTAINED_PART SET CYCLEMARK TO 'Y' DEFAULT 'N' USING CYRCLEPATH SELECT PART_NUMBER, SUM(NUMBER_OF PARTS), SUM(COST) FROM PARTS ORDER BY PART_NUMBER;
Пример 16.5.
Имена столбцов CYCLEMARK и CYRCLEPATH выбраны произвольным образом - требуется только, чтобы имена этих столбцов отличались от имен столбцов рекурсивного запроса. При выполнении запроса строки, удовлетворяющие его условию, накапливаются в результирующей таблице. Но, кроме того, эти строки "кэшируются" в столбце CYRCLEPATH. При попытке добавления к результату новой строки на основе текущего содержимого столбца CYRCLEPATH проверяется, не содержится ли она уже в результате. Если не содержится, то данные об этой строке добавляются к столбцу CYRCLEPATH (к массиву добавляется новый элемент), в столбец CYCLEMARK этой строки заносится значение 'N', и строка добавляется к результату. Иначе в столбец CYCLEMARK соответствующей строки результата заносится значение 'Y', означающее, что от этой строки начинается цикл.
Раздел GROUP BY CUBE
Наконец, заметим, что, в отличие от запросов с традиционной группировкой, результат запроса, содержащего раздел GROUP BY ROLLUP, зависит от порядка столбцов в списке группировки. При выполнении запроса происходит движение по этому списку слева направо с повышением уровня детальности результирующих данных. Существует еще одна разновидность запроса с группировкой, основанная на использовании раздела GROUP BY CUBE.
Пусть раздел группировки запроса имеет вид GROUP BY CUBE (cname1, cname2, ... , cnamen), где cnamei (i = 1, 2, ... , n) - имя столбца таблицы-результата раздела FROM запроса. Обозначим через SGBC множество {cname1, cname2, ... , cnamen}. Пусть Si является произвольным подмножеством SGBC, т.е. Si представляет собой пустое множество или имеет вид {cnamei1, cnamei2, ... , cnameim}, где m



SELECT DEPT_NO, EMP_BDATE, MAX (EMP_SAL)AS MAX_SAL, GROUPING (DEPT_NO) AS GDN, GROUPING (EMP_BDATE) AS GEB FROM EMP GROUP BY CUBE (DEPT_NO, EMP_BDATE);
Пример 16.2. Найти максимальный размер зарплаты во всем предприятии, максимальный размер зарплаты в каждом отделе, максимальный размер зарплаты сотрудников в каждой возрастной категории и максимальный размер зарплаты сотрудников каждой возрастной категории каждого отдела. (html, txt)
Результирующая таблица для этого запроса будет иметь следующий вид:

Рис. 16.4. Результат запроса с разделом GROUP BY CUBE и вызовами агрегатной функции GROUPING к таблице с неопределенными значениями столбцов группировки
Как видно, результат запроса из примера 16.2 совсем немного отличается от результата запроса из примера 16.1a. Добавились две последние строки, показывающие максимальные значения зарплаты всех сотрудников предприятия, родившихся в 1950-м и 1960-м гг. соответственно.
Наш пример может навести на мысль, что и в общем случае запросы, содержащие раздел GROUP BY CUBE, не слишком отличаются от запросов с GROUP BY ROLLUP, и выполнение этих запросов тоже не слишком различается. Однако это совсем не так. Запрос, содержащий раздел GROUP BY CUBE, действительно вырождается в объединение результатов 2n запросов с обычным разделом GROUP BY. Соответственно, сложность выполнения такого запроса несравненно выше сложности выполнения похожего запроса с GROUP BY ROLLUP. В нашем примере все получилось так просто только по той причине, что в запросе имеются всего два столбца группировки.
Раздел GROUP BY CUBE
Наконец, заметим, что, в отличие от запросов с традиционной группировкой, результат запроса, содержащего раздел GROUP BY ROLLUP, зависит от порядка столбцов в списке группировки. При выполнении запроса происходит движение по этому списку слева направо с повышением уровня детальности результирующих данных. Существует еще одна разновидность запроса с группировкой, основанная на использовании раздела GROUP BY CUBE.
Пусть раздел группировки запроса имеет вид GROUP BY CUBE (cname1, cname2, ... , cnamen), где cnamei (i = 1, 2, ... , n) - имя столбца таблицы-результата раздела FROM запроса. Обозначим через SGBC множество {cname1, cname2, ... , cnamen}. Пусть Si является произвольным подмножеством SGBC, т.е. Si представляет собой пустое множество или имеет вид {cnamei1, cnamei2, ... , cnameim}, где m
SELECT DEPT_NO, EMP_BDATE, MAX (EMP_SAL)AS MAX_SAL, GROUPING (DEPT_NO) AS GDN, GROUPING (EMP_BDATE) AS GEB FROM EMP GROUP BY CUBE (DEPT_NO, EMP_BDATE);
Пример 16.2. Найти максимальный размер зарплаты во всем предприятии, максимальный размер зарплаты в каждом отделе, максимальный размер зарплаты сотрудников в каждой возрастной категории и максимальный размер зарплаты сотрудников каждой возрастной категории каждого отдела.
Результирующая таблица для этого запроса будет иметь следующий вид:
Рис. 16.4. Результат запроса с разделом GROUP BY CUBE и вызовами агрегатной функции GROUPING к таблице с неопределенными значениями столбцов группировки
Как видно, результат запроса из примера 16.2 совсем немного отличается от результата запроса из примера 16.1a. Добавились две последние строки, показывающие максимальные значения зарплаты всех сотрудников предприятия, родившихся в 1950-м и 1960-м гг. соответственно.
Наш пример может навести на мысль, что и в общем случае запросы, содержащие раздел GROUP BY CUBE, не слишком отличаются от запросов с GROUP BY ROLLUP, и выполнение этих запросов тоже не слишком различается. Однако это совсем не так. Запрос, содержащий раздел GROUP BY CUBE, действительно вырождается в объединение результатов 2n запросов с обычным разделом GROUP BY. Соответственно, сложность выполнения такого запроса несравненно выше сложности выполнения похожего запроса с GROUP BY ROLLUP. В нашем примере все получилось так просто только по той причине, что в запросе имеются всего два столбца группировки.
Раздел GROUP BY ROLLUP
Эти же результаты можно получить при выполнении единственного запроса, если в его формулировке использовать специальный вид группировки ROLLUP (пример 16.1):
SELECT DEPT_NO, EMP_BDATE, MAX (EMP_SAL) AS MAX_SAL FROM EMP GROUP BY ROLLUP (DEPT_NO, EMP_BDATE);
Пример 16.1.
(html, txt)
Сначала покажем, как будет выглядеть результирующая таблица этого запроса, а потом приведем развернутое пояснение действия новой конструкции. В результате выполнения запроса будет получена таблица, показанная на рис.16.1.
Как видно, в столбце MAX_SAL первой строки1) результирующей таблицы находится максимальное значение зарплаты служащих на всем предприятии. Столбцы DEPT_NO и EMP_BDATE в этой строке содержат неопределенное значение, поскольку значение MAX_SAL не привязано к каким-либо отделу и возрастной категории. В столбце MAX_SAL следующих трех строк находятся максимальные значения зарплаты сотрудников отделов с номерами 1, 2 и 3 соответственно, что показывают значения столбца DEPT_NO. Столбец EMP_BDATE в этих строках содержит неопределенное значение, поскольку значение MAX_SAL не привязано к какой-либо возрастной категории. Наконец, в столбце MAX_SAL в последних шести строках содержатся максимальные значения зарплаты сотрудников каждой возрастной категории каждого отдела, что показывают значения столбцов DEPT_NO и EMP_BDATE, которые теперь содержат соответствующий номер отдела и год рождения служащих.

Рис. 16.1. Результат запроса с разделом GROUP BY ROLLUP
В общем случае пусть раздел группировки запроса имеет вид GROUP BY ROLLUP (cname1, cname2, ... , cnamen), где cnamei (i = 1, 2, ... , n) - имя столбца таблицы-результата раздела FROM запроса. Пусть в списке выборки используются вызовы агрегатных функций AGG1, AGG2, ... , AGGm над значениями столбцов, не входящих в список группировки, а также имена столбцов cname1, cname2, ... , cnamen. Тогда запрос выполняется следующим образом. Первая строка результата (первый набор строк результирующей таблицы) производится таким образом, как если бы в запросе вообще отсутствовал раздел GROUP BY, т.е. агрегатные функции AGG1, AGG2, ... , AGGm вычисляются над значениями всех строк таблицы. Значением столбцов cname1, cname2, ... , cnamen в этой строке является NULL. (i+1)-й набор строк результата формируется так, как если бы раздел группировки запроса имел вид GROUP BY (cname1, cname2, ... , cnamei) (1
Может показаться, что запросы, содержащие раздел GROUP BY ROLLUP, настолько сложны, что их выполнение будет занимать чрезмерно большое время. Это ощущение является ложным. В действительности, при выполнении запросов с обычной группировкой вида GROUP BY cname1, cname2, ... , cnamen, как правило, последовательно выполняется сортировка строк таблицы-результата раздела FROM в соответствии со значениями столбца cname1, затем - в соответствии со значениями столбца cname2 и т. д., и в заключение - сортировка в соответствии со значениями столбца cnamen. Во время выполнения каждой сортировки можно заодно вычислять значения агрегатных функций. Так что стоимость выполнения запроса, содержащего раздел GROUP BY ROLLUP, лишь незначительно отличается от стоимости выполнения запроса с обычной группировкой.
Раздел GROUP BY ROLLUP
Эти же результаты можно получить при выполнении единственного запроса, если в его формулировке использовать специальный вид группировки ROLLUP (пример 16.1):
SELECT DEPT_NO, EMP_BDATE, MAX (EMP_SAL) AS MAX_SAL FROM EMP GROUP BY ROLLUP (DEPT_NO, EMP_BDATE);
Пример 16.1.
Сначала покажем, как будет выглядеть результирующая таблица этого запроса, а потом приведем развернутое пояснение действия новой конструкции. В результате выполнения запроса будет получена таблица, показанная на рис.16.1.
Как видно, в столбце MAX_SAL первой строки1) результирующей таблицы находится максимальное значение зарплаты служащих на всем предприятии. Столбцы DEPT_NO и EMP_BDATE в этой строке содержат неопределенное значение, поскольку значение MAX_SAL не привязано к каким-либо отделу и возрастной категории. В столбце MAX_SAL следующих трех строк находятся максимальные значения зарплаты сотрудников отделов с номерами 1, 2 и 3 соответственно, что показывают значения столбца DEPT_NO. Столбец EMP_BDATE в этих строках содержит неопределенное значение, поскольку значение MAX_SAL не привязано к какой-либо возрастной категории. Наконец, в столбце MAX_SAL в последних шести строках содержатся максимальные значения зарплаты сотрудников каждой возрастной категории каждого отдела, что показывают значения столбцов DEPT_NO и EMP_BDATE, которые теперь содержат соответствующий номер отдела и год рождения служащих.
Рис. 16.1. Результат запроса с разделом GROUP BY ROLLUP
В общем случае пусть раздел группировки запроса имеет вид GROUP BY ROLLUP (cname1, cname2, ... , cnamen), где cnamei (i = 1, 2, ... , n) - имя столбца таблицы-результата раздела FROM запроса. Пусть в списке выборки используются вызовы агрегатных функций AGG1, AGG2, ... , AGGm над значениями столбцов, не входящих в список группировки, а также имена столбцов cname1, cname2, ... , cnamen. Тогда запрос выполняется следующим образом. Первая строка результата (первый набор строк результирующей таблицы) производится таким образом, как если бы в запросе вообще отсутствовал раздел GROUP BY, т.е. агрегатные функции AGG1, AGG2, ... , AGGm вычисляются над значениями всех строк таблицы. Значением столбцов cname1, cname2, ... , cnamen в этой строке является NULL. (i+1)-й набор строк результата формируется так, как если бы раздел группировки запроса имел вид GROUP BY (cname1, cname2, ... , cnamei) (1
Может показаться, что запросы, содержащие раздел GROUP BY ROLLUP, настолько сложны, что их выполнение будет занимать чрезмерно большое время. Это ощущение является ложным. В действительности, при выполнении запросов с обычной группировкой вида GROUP BY cname1, cname2, ... , cnamen, как правило, последовательно выполняется сортировка строк таблицы-результата раздела FROM в соответствии со значениями столбца cname1, затем - в соответствии со значениями столбца cname2 и т. д., и в заключение - сортировка в соответствии со значениями столбца cnamen. Во время выполнения каждой сортировки можно заодно вычислять значения агрегатных функций. Так что стоимость выполнения запроса, содержащего раздел GROUP BY ROLLUP, лишь незначительно отличается от стоимости выполнения запроса с обычной группировкой.
Раздел SEARCH
В приведенном выше примере не определялся порядок, в котором строки добавляются к частичному результату рекурсивного запроса. Однако иногда требуется, чтобы иерархия обходилась в глубину или в ширину. Соответствующая возможность обеспечивается конструкцией SEARCH. При указании требования обхода в глубину гарантируется, что каждый элемент-предок появится в результате раньше своих потомков и своих братьев справа. Если указывается требование обхода иерархии в ширину, в результате все братья одного уровня появляются раньше, чем какой-либо их потомок. Ниже показан вариант запроса, в котором содержится раздел SEARCH с требованием обхода иерархии элементов автомобиля в ширину (пример 16.4).
WITH RECURSIVE PARTS (ASSEMBLY, PART_NUMBER, NUMBER_OF_PARTS, COST) AS (SELECT CONTAINING_PART, CONTAINED_PART, 1, 0.00 FROM CAR WHERE CONTAINING_PART = '' UNION ALL SELECT CAR.CONTAINING_PART, CAR.CONTAINED_PART, CAR.NUMBER_OF_PARTS, CAR.NUMBER_OF_PARTS * CAR.PART_COST FROM CAR, PARTS WHERE PARTS.PART_NUMBER = CAR.CONTAINING_PART) SEARCH BREADTH FIRST BY CONTAINING_PART, CONTAINED_PART SET ORDER_COLUMN SELECT PART_NUMBER, NUMBER_OF PARTS, COST FROM PARTS ORDER BY ORDER_COLUMN;
Пример 16.4.
(html, txt)
В списке столбцов сортировки раздела SEARCH должны указываться имена столбцов виртуальной таблицы, определенной в разделе WITH. Поскольку в данном случае мы хотим, чтобы в результате сначала появлялись все конструктивные элементы одного уровня (CONTAINING_PART), а затем все их подэлементы (CONTAINED_PART), в список выборки рекурсивного запроса PARTS добавлен столбец CONTAINING_PART, который не используется нигде, кроме раздела SEARCH. В разделе SET к результирующей таблице рекурсивного запроса добавлен столбец, который мы назвали ORDER_COLUMN. Название соответствует природе столбца, потому что при выполнении рекурсивного запроса в этот столбец автоматически заносятся значения, характеризующие порядок генерируемых строк в соответствии с выбранным способом обхода иерархии. Чтобы строки результата основного запроса появлялись в должном порядке, в этом запросе требуется наличие раздела ORDER BY с указанием столбца, определенного в разделе SET.
Раздел SEARCH
В приведенном выше примере не определялся порядок, в котором строки добавляются к частичному результату рекурсивного запроса. Однако иногда требуется, чтобы иерархия обходилась в глубину или в ширину. Соответствующая возможность обеспечивается конструкцией SEARCH. При указании требования обхода в глубину гарантируется, что каждый элемент-предок появится в результате раньше своих потомков и своих братьев справа. Если указывается требование обхода иерархии в ширину, в результате все братья одного уровня появляются раньше, чем какой-либо их потомок. Ниже показан вариант запроса, в котором содержится раздел SEARCH с требованием обхода иерархии элементов автомобиля в ширину (пример 16.4).
WITH RECURSIVE PARTS (ASSEMBLY, PART_NUMBER, NUMBER_OF_PARTS, COST) AS (SELECT CONTAINING_PART, CONTAINED_PART, 1, 0.00 FROM CAR WHERE CONTAINING_PART = '' UNION ALL SELECT CAR.CONTAINING_PART, CAR.CONTAINED_PART, CAR.NUMBER_OF_PARTS, CAR.NUMBER_OF_PARTS * CAR.PART_COST FROM CAR, PARTS WHERE PARTS.PART_NUMBER = CAR.CONTAINING_PART) SEARCH BREADTH FIRST BY CONTAINING_PART, CONTAINED_PART SET ORDER_COLUMN SELECT PART_NUMBER, NUMBER_OF PARTS, COST FROM PARTS ORDER BY ORDER_COLUMN;
Пример 16.4.
В списке столбцов сортировки раздела SEARCH должны указываться имена столбцов виртуальной таблицы, определенной в разделе WITH. Поскольку в данном случае мы хотим, чтобы в результате сначала появлялись все конструктивные элементы одного уровня (CONTAINING_PART), а затем все их подэлементы (CONTAINED_PART), в список выборки рекурсивного запроса PARTS добавлен столбец CONTAINING_PART, который не используется нигде, кроме раздела SEARCH. В разделе SET к результирующей таблице рекурсивного запроса добавлен столбец, который мы назвали ORDER_COLUMN. Название соответствует природе столбца, потому что при выполнении рекурсивного запроса в этот столбец автоматически заносятся значения, характеризующие порядок генерируемых строк в соответствии с выбранным способом обхода иерархии. Чтобы строки результата основного запроса появлялись в должном порядке, в этом запросе требуется наличие раздела ORDER BY с указанием столбца, определенного в разделе SET.
Рекурсивные представления
Рекурсивным называется представление, в определяющем выражении запроса которого используется имя этого же представления. В представлениях может использоваться и прямая, и взаимная рекурсия. Синтаксис оператора определения рекурсивного запроса выглядит следующим образом:
CREATE RECURSIVE VIEW table_name [ column_name_comma_list ] AS query_expression
Хотя для того, чтобы представление было рекурсивным, требуется рекурсивность определяющего выражения запроса (т.е. в нем должна присутствовать спецификация RECURSIVE); наличие избыточного ключевого RECURSIVE в определении рекурсивного представления является обязательным. Как говорят авторы стандарта, это сделано для того, чтобы избежать случайного появления непредусмотренных рекурсивных представлений. Наконец, обратите внимание на то, что еще не обсуждавшийся нами необязательный раздел WITH CHECK OPTION не может присутствовать в определении рекурсивного представления (по той причине, что разработчики стандарта не смогли найти разумной интерпретации для комбинации RECURSIVE и WITH CHECK OPTION).
В заключение этого раздела могу сказать, что лично мне механизм рекурсии, предлагаемый в стандарте SQL, представляется громоздким и ограниченным. Кроме того, насколько мне известно, компании, поставляющие SQL-ориентированные СУБД, не спешат внедрять в свои продукты средства рекурсии в соответствии со стандартом SQL:1999.
Рекурсивные представления
Рекурсивным называется представление, в определяющем выражении запроса которого используется имя этого же представления. В представлениях может использоваться и прямая, и взаимная рекурсия. Синтаксис оператора определения рекурсивного запроса выглядит следующим образом:
CREATE RECURSIVE VIEW table_name [ column_name_comma_list ] AS query_expression
Хотя для того, чтобы представление было рекурсивным, требуется рекурсивность определяющего выражения запроса (т.е. в нем должна присутствовать спецификация RECURSIVE); наличие избыточного ключевого RECURSIVE в определении рекурсивного представления является обязательным. Как говорят авторы стандарта, это сделано для того, чтобы избежать случайного появления непредусмотренных рекурсивных представлений. Наконец, обратите внимание на то, что еще не обсуждавшийся нами необязательный раздел WITH CHECK OPTION не может присутствовать в определении рекурсивного представления (по той причине, что разработчики стандарта не смогли найти разумной интерпретации для комбинации RECURSIVE и WITH CHECK OPTION).
В заключение этого раздела могу сказать, что лично мне механизм рекурсии, предлагаемый в стандарте SQL, представляется громоздким и ограниченным. Кроме того, насколько мне известно, компании, поставляющие SQL-ориентированные СУБД, не спешат внедрять в свои продукты средства рекурсии в соответствии со стандартом SQL:1999.
Рекурсивные запросы
Начнем этот раздел с нескольких определений, касающихся понятий, которые связаны с рекурсией. Эти понятия имеют общий характер, но в приведенных ниже определениях и комментариях к ним (там, где это уместно) подчеркивается контекст SQL.
Рекурсивные запросы
Начнем этот раздел с нескольких определений, касающихся понятий, которые связаны с рекурсией. Эти понятия имеют общий характер, но в приведенных ниже определениях и комментариях к ним (там, где это уместно) подчеркивается контекст SQL.
Рекурсивные запросы с разделом WITH
В предыдущих лекциях мы уже говорили о разновидности спецификации ссылки на таблицу с использованием раздела WITH. Однако мы умышленно отложили обсуждение рекурсивных возможностей. Полный синтаксис раздела WITH выглядит следующим образом:
with_clause ::= WITH [ RECURSIVE ] with_element_comma_list with_element ::= query_name [ (column_name_list) ] AS ( query_expression ) [ search_or_cycle_clause ] search_or_cycle_clause ::= search_clause | cycle_clause | search_clause cycle_clause search_clause ::= SEARCH recursive_search_order SET sequence_column_name recursive_search_order ::= DEPTH FIRST BY order_item_commalist | BREADTH FIRST BY order_item_commalist cycle_clause ::= CYCLE cycle_column_name_comma_list SET cycle_mark_column_name TO value_expression DEFAULT value_expression USING path_column_name
Для иллюстрации возможностей рекурсивных запросов с разделом WITH и пояснения смысла конструкций SEARCH и CYCLE воспользуемся классическим примером "разборки деталей" (в данном случае мы будем разбирать автомобиль). Предположим, что данные о конструктивных элементах автомобиля хранятся в таблице CAR, определенной следующим образом:
CREATE TABLE CAR (CONTAINING_PART VARCHAR (10), CONTAINED_PART VARCHAR (10), NUMBER_OF_PARTS INTEGER, PART_COST DECIMAL (6,2));
У автомобиля имеется один конструктивный элемент верхнего уровня - полностью собранный автомобиль. Этот элемент не является составной частью какого-либо другого элемента, и для его строки значением столбца CONTAINING_PART является текстовая строка длины 0. В любой другой строке таблицы CAR, соответствующей некоторому неатомарному конструктивному элементу e, столбец CONTAINING_PART содержит идентификационный номер элемента e1, в который входит элемент e, столбец NUMBER_OF_PARTS - число экземпляров элемента e, входящих в e1, а столбец CONTAINED_PART - идентификационный номер самого элемента e. В любой строке таблицы CAR, соответствующей некоторому атомарному конструктивному элементу, значением столбца CONTAINED_PART является строка длины 0, а в столбце PART_COST сохраняется цена атомарного конструктивного элемента (для неатомарных элементов значение этого столбца равно нулю).
Предположим, что нам требуется разобрать автомобиль, начиная с элемента самого верхнего уровня, и для каждого конструктивного элемента получить его номер, общее число используемых экземпляров этого элемента, а также, если элемент является атомарным, общую стоимость используемых экземпляров. Вот возможная формулировка запроса (пример 16.3):
Рекурсивные запросы с разделом WITH
В предыдущих лекциях мы уже говорили о разновидности спецификации ссылки на таблицу с использованием раздела WITH. Однако мы умышленно отложили обсуждение рекурсивных возможностей. Полный синтаксис раздела WITH выглядит следующим образом:
with_clause ::= WITH [ RECURSIVE ] with_element_comma_list with_element ::= query_name [ (column_name_list) ] AS ( query_expression ) [ search_or_cycle_clause ] search_or_cycle_clause ::= search_clause | cycle_clause | search_clause cycle_clause search_clause ::= SEARCH recursive_search_order SET sequence_column_name recursive_search_order ::= DEPTH FIRST BY order_item_commalist | BREADTH FIRST BY order_item_commalist cycle_clause ::= CYCLE cycle_column_name_comma_list SET cycle_mark_column_name TO value_expression DEFAULT value_expression USING path_column_name
Для иллюстрации возможностей рекурсивных запросов с разделом WITH и пояснения смысла конструкций SEARCH и CYCLE воспользуемся классическим примером "разборки деталей" (в данном случае мы будем разбирать автомобиль). Предположим, что данные о конструктивных элементах автомобиля хранятся в таблице CAR, определенной следующим образом:
CREATE TABLE CAR (CONTAINING_PART VARCHAR (10), CONTAINED_PART VARCHAR (10), NUMBER_OF_PARTS INTEGER, PART_COST DECIMAL (6,2));
У автомобиля имеется один конструктивный элемент верхнего уровня - полностью собранный автомобиль. Этот элемент не является составной частью какого-либо другого элемента, и для его строки значением столбца CONTAINING_PART является текстовая строка длины 0. В любой другой строке таблицы CAR, соответствующей некоторому неатомарному конструктивному элементу e, столбец CONTAINING_PART содержит идентификационный номер элемента e1, в который входит элемент e, столбец NUMBER_OF_PARTS - число экземпляров элемента e, входящих в e1, а столбец CONTAINED_PART - идентификационный номер самого элемента e. В любой строке таблицы CAR, соответствующей некоторому атомарному конструктивному элементу, значением столбца CONTAINED_PART является строка длины 0, а в столбце PART_COST сохраняется цена атомарного конструктивного элемента (для неатомарных элементов значение этого столбца равно нулю).
Предположим, что нам требуется разобрать автомобиль, начиная с элемента самого верхнего уровня, и для каждого конструктивного элемента получить его номер, общее число используемых экземпляров этого элемента, а также, если элемент является атомарным, общую стоимость используемых экземпляров. Вот возможная формулировка запроса (пример 16.3):
PART_COST FROM CAR, PARTS WHERE
WITH RECURSIVE PARTS (PART_NUMBER, NUMBER_OF_PARTS, COST) AS (SELECT CONTAINED_PART, 1, 0.00 (a) FROM CAR WHERE CONTAINING_PART = '' UNION ALL SELECT CAR.CONTAINED_PART, CAR.NUMBER_OF_PARTS, CAR.NUMBER_OF_PARTS * CAR. PART_COST FROM CAR, PARTS WHERE PARTS.PART_NUMBER = CAR.CONTAINING_PART) SELECT PART_NUMBER, SUM(NUMBER_OF PARTS), SUM(COST) (b) FROM PARTS GROUP BY PART_NUMBER;
Пример 16.3.
(html, txt)
Этот запрос будет выполняться следующим образом. При вычислении раздела FROM основного запроса (b) начнется выполнение рекурсивного выражения запросов (a), определенного в разделе WITH. На первом шаге рекурсии будет выполнена часть данного выражения, предшествующая операции UNION ALL и образующая начальный источник рекурсии. В результате будет произведено исходное состояние виртуальной таблицы PARTS, в котором, в нашем случае, появится единственная строка, соответствующая автомобилю целиком. На следующем шаге к таблице PARTS будут добавлены строки, соответствующие конструктивным элементам второго уровня (для автомобиля это, по-видимому, двигатель, колеса, шасси и т.д.). Этот процесс будет продолжаться до тех пор, пока мы не дойдем до атомарных конструктивных элементов и не достигнем, тем самым, фиксированной точки. Поскольку в рекурсивном запросе содержится операция UNION ALL, в результирующей таблице могут появляться строки-дубликаты. Наличие строки-дубликата вида <part_no, number, cost> означает, что элемент с номером part_no входит в одном и том же числе экземпляров в несколько конструктивных элементов более высокого уровня.
PART_COST FROM CAR, PARTS WHERE
WITH RECURSIVE PARTS (PART_NUMBER, NUMBER_OF_PARTS, COST) AS (SELECT CONTAINED_PART, 1, 0.00 (a) FROM CAR WHERE CONTAINING_PART = '' UNION ALL SELECT CAR.CONTAINED_PART, CAR.NUMBER_OF_PARTS, CAR.NUMBER_OF_PARTS * CAR. PART_COST FROM CAR, PARTS WHERE PARTS.PART_NUMBER = CAR.CONTAINING_PART) SELECT PART_NUMBER, SUM(NUMBER_OF PARTS), SUM(COST) (b) FROM PARTS GROUP BY PART_NUMBER;
Пример 16.3.
Этот запрос будет выполняться следующим образом. При вычислении раздела FROM основного запроса (b) начнется выполнение рекурсивного выражения запросов (a), определенного в разделе WITH. На первом шаге рекурсии будет выполнена часть данного выражения, предшествующая операции UNION ALL и образующая начальный источник рекурсии. В результате будет произведено исходное состояние виртуальной таблицы PARTS, в котором, в нашем случае, появится единственная строка, соответствующая автомобилю целиком. На следующем шаге к таблице PARTS будут добавлены строки, соответствующие конструктивным элементам второго уровня (для автомобиля это, по-видимому, двигатель, колеса, шасси и т.д.). Этот процесс будет продолжаться до тех пор, пока мы не дойдем до атомарных конструктивных элементов и не достигнем, тем самым, фиксированной точки. Поскольку в рекурсивном запросе содержится операция UNION ALL, в результирующей таблице могут появляться строки-дубликаты. Наличие строки-дубликата вида <part_no, number, cost> означает, что элемент с номером part_no входит в одном и том же числе экземпляров в несколько конструктивных элементов более высокого уровня.
Возможности формулирования аналитических запросов
Аналитическими запросами к базе данных принято называть запросы, сводные (агрегатные) результаты которых вычисляются над детальными данными, хранящимися в таблицах базы данных. В этом смысле любой запрос на языке SQL, результат которого основан на вычислении агрегатных функций, можно назвать аналитическим. Характерная особенность аналитических запросов состоит в том, что, как правило, они применяются к большим по объему базам данных, и выполнение таких запросов вызывает существенные накладные расходы СУБД.
В этом курсе мы не будем подробно обсуждать возможности языка SQL, предназначенные для поддержки оперативной аналитической обработки баз данных (OLAP - on-line analytical processing). Рассмотрим только самые основные средства, опираясь на простые примеры. Для этих примеров предположим, что таблица EMP содержит следующий набор строк (покажем содержимое только тех столбцов, которые потребуются в примерах, причем для простоты будем считать, что в столбце EMP_DATE содержится не полная дата, а только год рождения служащего):
| 2440 | 1 | 1950 | 15000.00 |
| 2441 | 1 | 1950 | 16000.00 |
| 2442 | 1 | 1960 | 14000.00 |
| 2443 | 1 | 1960 | 19000.00 |
| 2444 | 2 | 1950 | 17000.00 |
| 2445 | 2 | 1950 | 16000.00 |
| 2446 | 2 | 1960 | 14000.00 |
| 2447 | 2 | 1960 | 20000.00 |
| 2448 | 3 | 1950 | 18000.00 |
| 2449 | 3 | 1950 | 13000.00 |
| 2450 | 3 | 1960 | 21000.00 |
| 2451 | 3 | 1960 | 22000.00 |
Представим себе, что для проведения анализа требуется узнать максимальный размер зарплаты на всем предприятии, максимальный размер зарплаты в каждом отделе и максимальный размер зарплаты сотрудников каждой возрастной категории каждого отдела. Если пользоваться стандартными средствами языка SQL, обсуждавшимися ранее в предложенном курсе, то для получения этих данных потребуется три запроса:
SELECT MAX (EMP_SAL) AS MAX_ENT_SAL FROM EMP; SELECT DEPT_NO, MAX (EMP_SAL) AS MAX_DEP_SAL FROM EMP GROUP BY DEPT_NO; SELECT DEPT_NO, EMP_BDATE, MAX (EMP_SAL) AS MAX_DEP_BDATE_SAL FROM EMP GROUP BY DEPT_NO, EMP_BDATE;
При выполнении запросов будут получены следующие результирующие таблицы:
| 22000.00 |
| 1 | 19000.00 |
| 2 | 20000.00 |
| 3 | 22000.00 |
| 1 | 1950 | 16000.00 |
| 1 | 1960 | 19000.00 |
| 2 | 1950 | 17000.00 |
| 2 | 1960 | 20000.00 |
| 3 | 1950 | 18000.00 |
| 3 | 1960 | 22000.00 |
Возможности формулирования аналитических запросов
Аналитическими запросами к базе данных принято называть запросы, сводные (агрегатные) результаты которых вычисляются над детальными данными, хранящимися в таблицах базы данных. В этом смысле любой запрос на языке SQL, результат которого основан на вычислении агрегатных функций, можно назвать аналитическим. Характерная особенность аналитических запросов состоит в том, что, как правило, они применяются к большим по объему базам данных, и выполнение таких запросов вызывает существенные накладные расходы СУБД.
В этом курсе мы не будем подробно обсуждать возможности языка SQL, предназначенные для поддержки оперативной аналитической обработки баз данных (OLAP - on-line analytical processing). Рассмотрим только самые основные средства, опираясь на простые примеры. Для этих примеров предположим, что таблица EMP содержит следующий набор строк (покажем содержимое только тех столбцов, которые потребуются в примерах, причем для простоты будем считать, что в столбце EMP_DATE содержится не полная дата, а только год рождения служащего):
| 2440 | 1 | 1950 | 15000.00 |
| 2441 | 1 | 1950 | 16000.00 |
| 2442 | 1 | 1960 | 14000.00 |
| 2443 | 1 | 1960 | 19000.00 |
| 2444 | 2 | 1950 | 17000.00 |
| 2445 | 2 | 1950 | 16000.00 |
| 2446 | 2 | 1960 | 14000.00 |
| 2447 | 2 | 1960 | 20000.00 |
| 2448 | 3 | 1950 | 18000.00 |
| 2449 | 3 | 1950 | 13000.00 |
| 2450 | 3 | 1960 | 21000.00 |
| 2451 | 3 | 1960 | 22000.00 |
Представим себе, что для проведения анализа требуется узнать максимальный размер зарплаты на всем предприятии, максимальный размер зарплаты в каждом отделе и максимальный размер зарплаты сотрудников каждой возрастной категории каждого отдела. Если пользоваться стандартными средствами языка SQL, обсуждавшимися ранее в предложенном курсе, то для получения этих данных потребуется три запроса:
SELECT MAX (EMP_SAL) AS MAX_ENT_SAL FROM EMP; SELECT DEPT_NO, MAX (EMP_SAL) AS MAX_DEP_SAL FROM EMP GROUP BY DEPT_NO; SELECT DEPT_NO, EMP_BDATE, MAX (EMP_SAL) AS MAX_DEP_BDATE_SAL FROM EMP GROUP BY DEPT_NO, EMP_BDATE;
При выполнении запросов будут получены следующие результирующие таблицы:
| 22000.00 |
| 1 | 19000.00 |
| 2 | 20000.00 |
| 3 | 22000.00 |
| 1 | 1950 | 16000.00 |
| 1 | 1960 | 19000.00 |
| 2 | 1950 | 17000.00 |
| 2 | 1960 | 20000.00 |
| 3 | 1950 | 18000.00 |
| 3 | 1960 | 22000.00 |
Две темы, которым посвящается эта
Две темы, которым посвящается эта лекция, касаются сравнительно новых возможностей оператора SELECT языка SQL, впервые появившихся в стандарте SQL:1999 и открывающих возможность использования языка в приложениях, для которых ранее он не был приспособлен. Речь идет о возможностях аналитических и рекурсивных запросов. Эти темы логически не связаны, их объединяет лишь то, что соответствующие средства очень громоздки и не всегда легко понимаются. В данной краткой лекции мы не стремимся привести полное описание возможностей, специфицированных в стандарте SQL. Наша цель состоит лишь в том, чтобы в общих чертах описать подход SQL в указанных направлениях.
В аналитических приложениях обычно требуются не детальные данные, непосредственно хранящиеся в базе данных, а некоторые их обобщения, агрегаты. Например, аналитика интересует не заработная плата конкретного человека в конкретное время, а изменение заработной платы некоторой категории людей в течение определенного промежутка времени. Если пользоваться терминологией SQL, то типичный запрос к базе данных со стороны аналитического приложения содержит раздел GROUP BY и вызовы агрегатных функций. Хотя в этом курсе мы почти не касаемся вопросов реализации SQL-ориентированных СУБД, из общих соображений должно быть понятно, что запросы с разделом GROUP BY в общем случае являются "трудными" для СУБД, поскольку для группирования таблицы, вообще говоря, требуется внешняя сортировка.
В системах баз данных, специально спроектированных в расчете на аналитические приложения, проблему обычно решают за счет явного избыточного хранения агрегированных данных (т.е. результатов вызовов агрегатных функций). Конечно, для этого требуется динамическая корректировка хранимых агрегатных значений при изменении детальных данных, но для таких специализированных баз данных это не слишком обременительно, поскольку аналитические базы данных обновляются сравнительно редко.
Однако далеко не каждое предприятие может позволить себе одновременно поддерживать оперативную базу данных для работы обычных приложений оперативной обработки транзакций (OLTP), таких, как бухгалтерские, кадровые и другие приложения, и аналитическую базу данных для приложений оперативной аналитической обработки (OLAP). Приходится выполнять аналитические приложения над детальными оперативными базами данных, и эти приложения обращаются к СУБД с многочисленными трудоемкими запросами с разделами GROUP BY и вызовами агрегатных функций.
Разработчики стандарта языка SQL старались одновременно решить две задачи: сократить число запросов, требуемых в аналитических приложениях, и добиться снижения стоимости запросов с разделом GROUP BY, обеспечивающих требуемые суммарные данные. В этой лекции мы обсудим наиболее важные, с нашей точки зрения, конструкции языка SQL, облегчающие формулировку, выполнение и использование результатов аналитических запросов: разделы GROUP BY ROLLUP и GROUP BY CUBE и новую агрегатную функцию GROUPING, позволяющую правильно трактовать результаты аналитических запросов при наличии неопределенных значений.
Традиционно язык SQL никогда не обладал возможностью формулировки рекурсивных запросов, где под рекурсивным запросом (упрощенно говоря) мы понимаем запрос к таблице, которая сама каким-либо образом изменяется при выполнении этого запроса. Напомню, что это заложено в базовую семантику оператора SQL: до выполнения раздела WHERE результат раздела FROM должен быть полностью вычислен.
Однако разработчикам приложений часто приходится решать задачи, для которых недостаточно традиционных средств формулировки запросов языка SQL: например, нахождение маршрута движения между двумя заданными географическими точками, определения общего набора комплектующих для сбора некоторого агрегата и т.д. Компании-производители SQL-ориентированных СУБД пытались удовлетворять такие потребности за счет частных решений, обладающих ограниченными рекурсивными свойствами, но до появления стандарта SQL:1999 общие стандартизованные средства отсутствовали.
Следует отметить и некоторое давление на SQL-сообщество со стороны сообщества логических систем баз данных. На основе языка логического программирования Prolog был разработан язык реляционных баз данных Datalog, обеспечивающий все необходимые средства для обычной работы с базами данных наряду с развитыми возможностями рекурсивных запросов. Требовался адекватный ответ со стороны разработчиков стандарта SQL.
Компромиссное (не слишком красивое) решение для введения рекурсии в SQL было найдено на основе введения раздела WITH в выражение запроса. Только в этом разделе допускается как линейная, так и взаимная рекурсия между вводимыми порождаемыми таблицами. При этом только для линейной рекурсии обеспечиваются дополнительные возможности управления порядком вычисления рекурсивно определенной порождаемой таблицы и контроля отсутствия циклов. Следует заметить, что при чтении стандарта временами возникает впечатление, что его авторы сами не до конца еще осознали всех возможных последствий, к которым может привести использование введенных конструкций. Я думаю, что в следующих версиях стандарта следует ожидать уточнений и/или ограничений использования названных конструкций. В связи с этим в данной лекции мы ограничиваемся общими определениями рекурсивных конструкций языка SQL и обсуждением простого случая рекурсивного запроса.
Две темы, которым посвящается эта
Две темы, которым посвящается эта лекция, касаются сравнительно новых возможностей оператора SELECT языка SQL, впервые появившихся в стандарте SQL:1999 и открывающих возможность использования языка в приложениях, для которых ранее он не был приспособлен. Речь идет о возможностях аналитических и рекурсивных запросов. Эти темы логически не связаны, их объединяет лишь то, что соответствующие средства очень громоздки и не всегда легко понимаются. В данной краткой лекции мы не стремимся привести полное описание возможностей, специфицированных в стандарте SQL. Наша цель состоит лишь в том, чтобы в общих чертах описать подход SQL в указанных направлениях.
В аналитических приложениях обычно требуются не детальные данные, непосредственно хранящиеся в базе данных, а некоторые их обобщения, агрегаты. Например, аналитика интересует не заработная плата конкретного человека в конкретное время, а изменение заработной платы некоторой категории людей в течение определенного промежутка времени. Если пользоваться терминологией SQL, то типичный запрос к базе данных со стороны аналитического приложения содержит раздел GROUP BY и вызовы агрегатных функций. Хотя в этом курсе мы почти не касаемся вопросов реализации SQL-ориентированных СУБД, из общих соображений должно быть понятно, что запросы с разделом GROUP BY в общем случае являются "трудными" для СУБД, поскольку для группирования таблицы, вообще говоря, требуется внешняя сортировка.
В системах баз данных, специально спроектированных в расчете на аналитические приложения, проблему обычно решают за счет явного избыточного хранения агрегированных данных (т.е. результатов вызовов агрегатных функций). Конечно, для этого требуется динамическая корректировка хранимых агрегатных значений при изменении детальных данных, но для таких специализированных баз данных это не слишком обременительно, поскольку аналитические базы данных обновляются сравнительно редко.
Однако далеко не каждое предприятие может позволить себе одновременно поддерживать оперативную базу данных для работы обычных приложений оперативной обработки транзакций (OLTP), таких, как бухгалтерские, кадровые и другие приложения, и аналитическую базу данных для приложений оперативной аналитической обработки (OLAP). Приходится выполнять аналитические приложения над детальными оперативными базами данных, и эти приложения обращаются к СУБД с многочисленными трудоемкими запросами с разделами GROUP BY и вызовами агрегатных функций.
Разработчики стандарта языка SQL старались одновременно решить две задачи: сократить число запросов, требуемых в аналитических приложениях, и добиться снижения стоимости запросов с разделом GROUP BY, обеспечивающих требуемые суммарные данные. В этой лекции мы обсудим наиболее важные, с нашей точки зрения, конструкции языка SQL, облегчающие формулировку, выполнение и использование результатов аналитических запросов: разделы GROUP BY ROLLUP и GROUP BY CUBE и новую агрегатную функцию GROUPING, позволяющую правильно трактовать результаты аналитических запросов при наличии неопределенных значений.
Традиционно язык SQL никогда не обладал возможностью формулировки рекурсивных запросов, где под рекурсивным запросом (упрощенно говоря) мы понимаем запрос к таблице, которая сама каким-либо образом изменяется при выполнении этого запроса. Напомню, что это заложено в базовую семантику оператора SQL: до выполнения раздела WHERE результат раздела FROM должен быть полностью вычислен.
Однако разработчикам приложений часто приходится решать задачи, для которых недостаточно традиционных средств формулировки запросов языка SQL: например, нахождение маршрута движения между двумя заданными географическими точками, определения общего набора комплектующих для сбора некоторого агрегата и т.д. Компании-производители SQL-ориентированных СУБД пытались удовлетворять такие потребности за счет частных решений, обладающих ограниченными рекурсивными свойствами, но до появления стандарта SQL:1999 общие стандартизованные средства отсутствовали.
Следует отметить и некоторое давление на SQL-сообщество со стороны сообщества логических систем баз данных. На основе языка логического программирования Prolog был разработан язык реляционных баз данных Datalog, обеспечивающий все необходимые средства для обычной работы с базами данных наряду с развитыми возможностями рекурсивных запросов. Требовался адекватный ответ со стороны разработчиков стандарта SQL.
Компромиссное (не слишком красивое) решение для введения рекурсии в SQL было найдено на основе введения раздела WITH в выражение запроса. Только в этом разделе допускается как линейная, так и взаимная рекурсия между вводимыми порождаемыми таблицами. При этом только для линейной рекурсии обеспечиваются дополнительные возможности управления порядком вычисления рекурсивно определенной порождаемой таблицы и контроля отсутствия циклов. Следует заметить, что при чтении стандарта временами возникает впечатление, что его авторы сами не до конца еще осознали всех возможных последствий, к которым может привести использование введенных конструкций. Я думаю, что в следующих версиях стандарта следует ожидать уточнений и/или ограничений использования названных конструкций. В связи с этим в данной лекции мы ограничиваемся общими определениями рекурсивных конструкций языка SQL и обсуждением простого случая рекурсивного запроса.
Общие синтакические правила построения скалярных
Если вернуться к синтаксическим определениям разд. " Общие синтакические правила построения скалярных выражений" лекции 13, то можно убедиться, что в последних четырех лекциях мы рассмотрели все варианты организации оператора SELECT языка SQL (за исключением конструкций collection_derived_table и ONLY (table_or_query_name), относящихся к объектным расширениям языка SQL).
Для общего понимания языка на модельном уровне более важными являются предыдущие три лекции. Данная лекция включена в курс, скорее, с целью общего ознакомления читателей с новыми возможностями оператора выборки, чем с целью их подробного описания. С большой вероятностью средства формулировки аналитических и рекурсивных запросов языка SQL будут пересматриваться при подготовке следующих вариантов стандарта языка.
Общие синтакические правила построения скалярных
Если вернуться к синтаксическим определениям разд. " Общие синтакические правила построения скалярных выражений" лекции 13, то можно убедиться, что в последних четырех лекциях мы рассмотрели все варианты организации оператора SELECT языка SQL (за исключением конструкций collection_derived_table и ONLY (table_or_query_name), относящихся к объектным расширениям языка SQL).
Для общего понимания языка на модельном уровне более важными являются предыдущие три лекции. Данная лекция включена в курс, скорее, с целью общего ознакомления читателей с новыми возможностями оператора выборки, чем с целью их подробного описания. С большой вероятностью средства формулировки аналитических и рекурсивных запросов языка SQL будут пересматриваться при подготовке следующих вариантов стандарта языка.
 |
|
|
1)
Конечно, мы показали строки результирующей таблицы, расположенные в удобном для нас порядке только для упрощения объяснений. В действительности, строки результирующей таблицы (как обычно) будут расположены в порядке, определяемом системой. Чтобы добиться в точности такого порядка расположения строк, как это показано на рис.16.1, к формулировке запроса из примера 16.1 нужно добавить раздел ORDER BY DEPT_NO, EMP_BDATE.
2)
Мы опять искусственным образом упорядочили результат запроса для удобства пояснений.
| © 2003-2007 INTUIT.ru. Все права защищены. |