Что такое индекс
Что такое индекс
Данные в таблице обычно отображаются в том порядке, в каком их в нее первоначально ввели. Однако такой порядок может не иметь ничего общего с тем порядком, в котором затем требуется эти данные обрабатывать. Скажем, что вы, например, хотите обрабатывать таблицу CLIENT в такой последовательности, чтобы значения в столбце ClientName располагались в алфавитном порядке. Но на такую сортировку записей таблицы требуется определенное время. И чем таблица больше, тем сортировка проходит дольше. Что если в вашей таблице сто тысяч записей? Или миллион? А ведь в некоторых приложениях таблицы такого размера не являются редкостью. Даже при выполнении лучших алгоритмов сортировки, чтобы выстроить записи таблицы в нужном порядке, все равно придется в таком случае проделать примерно двадцать миллионов сравнений и миллионы перестановок. И пусть у вас очень быстрый компьютер, но подождать все-таки придется.
Индексы могут оказаться прекрасным средством экономии времени. Индекс — это подчиненная таблица, или таблица поддержки, которая сопровождает свою таблицу данных.
Каждой строке таблицы данных соответствует определенная строка таблицы индекса. Однако порядок расположения строк в таблице индекса другой.
Небольшой пример таблицы данных показан в табл. 5.2.
Действие 1 определение объектов
Действие 1: определение объектов
Первое действие, которое предстоит выполнить при проектировании базы данных, — это решить, какие аспекты системы являются достаточно важными, чтобы быть включенными в модель. Каждый такой аспект рассматривайте как объект и составьте список этих объектов — всех, которые только придут вам в голову. И не пытайтесь гадать, каким образом эти объекты связаны друг с другом. Всего лишь попробуйте внести их в список.
Совет 1
Совет 1
Было бы полезно иметь команду из нескольких человек, знакомых с системой, которую вы моделируете. Они могли бы проводить "мозговой штурм" и реагировать на высказанные друг другом идеи. Вместе вы, вероятно, разработаете более полный и точный набор объектов.
Когда вы решите, что получился достаточно полный набор объектов, можете приступать к следующему действию: определить, каким образом эти объекты связаны друг с другом. Некоторые из них являются главными и играют важную роль в получении нужных вам результатов. Другие же являются подчиненными объектами по отношению к главным. Кроме того, следует окончательно решить, какие объекты вообще не являются частью модели.
Действие 2 определение таблиц и столбцов
Действие 2: определение таблиц и столбцов
Главные объекты переводятся в таблицы базы данных. И у каждого из главных объектов имеется набор связанных между собой атрибутов, которые переводятся в столбцы соответствующей таблицы. Например, во многих базах данных, применяемых в бизнесе, имеется таблица CUSTOMER (клиент), в которой хранятся имена клиентов, адреса и другая информация о них. Каждый из атрибутов клиента, такой, например, как имя, улица, город, штат, почтовый код, номер телефона и адрес в Internet, становится столбцом в таблице CUSTOMER.
Имеются достаточно легкие правила, позволяющие быстро определить, что должно стать таблицами и какие из атрибутов системы должны принадлежать каждой такой таблице. Возможно, у вас есть причины, чтобы присвоить какой-либо атрибут одной таблице, но также есть причины, чтобы присвоить его другой таблице. Вам следует принять решение на основе той информации, которую нужно получать из базы данных, и того, каким образом должна использоваться эта информация.
Действие 3 точное определение таблиц
Действие 3: точное определение таблиц
Теперь для каждого объекта вам необходимо точно определить таблицу, а для каждого атрибута — столбец. В табл. 5.1 показаны таблицы базы данных VetLab.
Доменная целостность
Доменная целостность
Обычно вы не можете гарантировать, что конкретный элемент данных из базы правильно введен, но можете хотя бы определить, разрешено ли его использование. У многих элементов данных набор возможных значений является ограниченным. Если вводится значение, которое не входит в этот набор, то такой ввод должен считаться ошибочным. Например, Соединенные Штаты состоят из 50 штатов, округа Колумбия, Пуэрто-Рико и еще нескольких владений. У каждой из этих территорий имеется код, состоящий из двух символов и признанный почтовой службой США. И если в базе данных имеется столбец State (штат), то доменную целостность можно обеспечить, требуя, чтобы любой ввод в этот столбец был одним из разрешенных двух-символьных кодов. Если оператор вводит код, не входящий в список принятых кодов, он тем самым нарушает доменную целостность. Проверяя соблюдение доменной целостности, вы можете отказываться принимать любую нарушающую эту целостность операцию.
Опасения за доменную целостность возникают при вводе в таблицу новых данных, выполняемом с помощью оператора INSERT или UPDATE. Домен для столбца можно установить с помощью оператора CREATE DOMAIN (создать домен), причем до того, как использовать этот столбец в операторе CREATE TABLE. Это показано в следующем примере, где перед созданием таблицы TEAM (команда) со столбцами TeamName (имя команды) и League (лига) создается домен LeagueDom (домен значений лиги):
| CREATE DOMAIN LeagueDom | CHAR (8) | |
| CHECK (LEAGUE IN ('American', 'National')); | ||
| CREATE TABLE TEAM ( | ||
| TeamName | CHARACTER (20) | NOT NULL, |
| League | CHARACTER (8) | NOT NULL |
| ); |
Домен для столбца League состоит из двух разрешенных значений: American (американская) и National (национальная). СУБД не позволит успешно выполнить ввод или обновление в таблице TEAM, если в столбце League вводимой или обновляемой строки появляется значение, которое отличается от American или National.
Доменноключевая нормальная форма (ДКНФ)
Доменно-ключевая нормальная форма (ДКНФ)
После того как база данных оказалась в третьей нормальной форме, большинство шансов на возникновение аномалий изменения было сведено на нет. Впрочем, большинство, но не все. Для исправления этих оставшихся неполадок как раз предназначены нормальные формы, находящиеся внутри третьей. Примерами таких форм являются нормальная форма Бойса-Кодда (НФБК), четвертая нормальная форма (4НФ) и пятая нормальная форма (5НФ). Каждая форма сводит на нет угрозу какой-либо аномалии изменения, но не дает гарантии защиты от всех таких аномалий. Такую гарантию дает только доменно-ключевая нормальная форма (ДКНФ).
Помни: Отношение находится в доменно-ключевой нормальной форме (ДКНФ), если каждое ограничение в этом отношении является логическим следствием определения ключей и доменов. Ограничением в этом определении называется любое правило, которое можно проверить. Ключ — это уникальный идентификатор табличной строки, а домен — набор разрешенных значений атрибута.
Снова посмотрим на базу данных (см. Рисунок 5.2), которая находится в 1НФ. Это необходимо, чтобы увидеть, каким образом привести эту базу в ДКНФ.
Таблица: SALES(CustomerlD,Product,Price)
Ключ: CustomerID
Ограничения: CustomerlD определяет Product
PRODUCT определяет Price
CustomerlD должен быть целым числом больше 1000
Как заставить работать ограничение 3 (атрибут CustomerlD должен быть целым числом больше 1000)? Можно всего лишь так определить домен CustomerlD, чтобы в него входило это ограничение. Таким образом, ограничение становится логическим следствием домена столбца CustomerlD. Product и зависит от CustomerlD, a CustomerlD — это ключ, так что трудностей с ограничением 1 не будет, поскольку оно является логическим следствием определения ключа. Однако трудность есть с ограничением 2: Price зависит от (является логическим следствием) Product, a Product не является ключом. Справиться с трудностью можно, разделив таблицу SALES на две. В одной из них в качестве ключа используется CustomerlD, а в другой — Product. Такая схема приведена на Рисунок 5.3. База данных на этом рисунке находится не только в ЗНФ, но и в ДКНФ.
Помни: Проектируйте базы данных так, чтобы они по возможности были в ДКНФ. В таком случае ключевые и доменные ограничения определяют все требуемые ограничения, и аномалии изменений исключены. А если структура базы данных спроектирована так, чтобы ее нельзя было привести в ДКНФ, то ограничения необходимо встроить в прикладную программу, которая использует базу данных. Сама база данных не дает гарантии, что ограничения будут соблюдаться.
Создание многотабличной реляционной базы данных
Глава 5. Создание многотабличной реляционной базы данных
Избыточность данных
Избыточность данных
В тех базах, которые организованы иерархически, избыточность данных — это существенная проблема. Впрочем, она имеет место и в реляционных базах. Такая избыточность не только означает ненужный расход места на диске и замедление обработки, но также может привести и к серьезному повреждению данных. Если вы храните один и тот же элемент данных в двух разных таблицах базы данных, то одна его копия может быть изменена, а другая, что находится во второй таблице, может остаться прежней. Такая ситуация приводит к расхождениям, и может случиться так, что вы не сможете сказать, какой из двух вариантов является правильным. Желательно сводить избыточность данных к минимуму. Определенная избыточность необходима, чтобы первичный ключ одной таблицы служил внешним ключом другой. Однако любой другой избыточности старайтесь избегать. Самый распространенный метод уменьшения избыточности в проекте называется нормализацией. Он состоит в том, что одна таблица из базы данных разбивается на две или несколько простых.
Правда, после того как вы уберете большую часть избыточности из проекта базы данных, то, возможно, обнаружите, что ее производительность стала никуда не годной. Операторы очень часто используют избыточность специально для того, чтобы ускорить обработку данных. В предыдущем примере в таблице ORDERS для определения источника каждого заказа имеется только название фирмы-клиента. При оформлении заказа, чтобы получить адрес этой фирмы, вам необходимо соединить таблицу ORDERS с таблицей CLIENT. Если в результате такого соединения таблиц программа, которая распечатывает заказы, будет работать очень медленно, то вам, возможно, захочется выполнять избыточное хранение адреса фирмы-клиента, т.е. еще и в таблице ORDERS, а не только в CLIENT. Преимущество такой избыточности состоит в более быстрой распечатке заказов, но это происходит за счет замедления и усложнения любого обновления адреса клиента.
Совет 4
Совет 4
Распространенная среди пользователей практика состоит в том, чтобы вначале проектировать базу данных с малой избыточностью и с высокой степенью нормализации, а затем, обнаружив, что важные приложения работают медленно, выборочно добавлять избыточность и уменьшать нормализацию. Главное слово здесь — это "выборочно". Добавляемая избыточность предназначена для определенной цели, и так как она представляет определенный риск, предпринимайте соответствующие меры к тому, чтобы избыточность вызывала проблем не больше, чем решала.
Эта таблица SALES ведет к аномалиям изменения
Рисунок 5.2. Эта таблица SALES ведет к аномалиям изменения
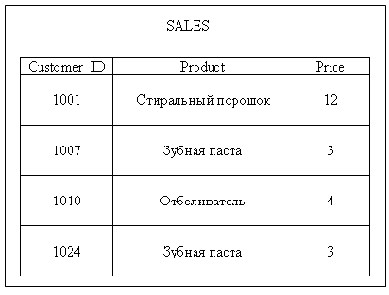
Ваша компания продает моющие средства для дома и предметы личной гигиены, и за один и тот же товар все покупатели платят одинаково. Все данные содержатся в таблице SALES — например, о продажах стирального порошка, зубной пасты и отбеливателя. Теперь предположим, что покупатель 1001 уехал и больше ничего у вас не приобретает. И так как он не собирается больше ничего приобретать, то вам не интересно, что же он приобретал раньше. Поэтому вы хотите удалить его строку из таблицы. Однако если вы это сделаете, то не только потеряете данные о том, что покупатель 1001 приобретал стиральный порошок, но йотом, что стиральный порошок стоит 12 долларов. Такая ситуация называется аномалией удаления. Удаляя одни данные (о том, что покупатель 1001 приобретал стиральный порошок), вы нечаянно удалите другие (о том, что стиральный порошок стоит 12 долларов).
В той же таблице можно наблюдать и аномалию вставки. Скажем, вы хотите добавить к своим товарам еще и сухой дезодорант по цене 2 доллара. Но эти данные нельзя будет поместить в таблицу SALES до тех пор, пока сухой дезодорант не потребуется какому-нибудь покупателю.
Трудность с изображенной на рисунке таблицей SALES заключается в том, что эта таблица слишком универсальна. В ней есть данные и о том, что именно приобрели у вас покупатели, и о том, сколько стоят купленные товары. Эту таблицу необходимо разбить на две другие, и каждая из них будет посвящена только одной теме (Рисунок 5.3).
Механическое повреждение
Механическое повреждение
При механическом повреждении носителя данных, на котором была открыта таблица базы данных, данные этой таблицы могут быть испорчены. Главная защита против подобной неприятности — резервное копирование.
Ненормальная форма
Ненормальная форма
Ненормальность иногда полезна. Возможно, вы увлеклись нормализацией, и вас занесло слишком далеко. Ведь базу данных можно разбить на такое количество таблиц, что вся она станет громоздкой и неэффективной. Ее работа может застопориться. Так что часто оптимальная структура должна быть в какой-то степени денормализованной. На самом деле базы данных, используемые в практической деятельности, никогда не нормализованы до уровня ДКНФ. Впрочем, чтобы исключить возможность повреждения данных, происходящего из-за аномалий изменений, максимально нормализуйте проектируемую вами базу данных.
После этого мосты еще не сожжены. Если производительность вас не удовлетворяет, проверьте свой проект — можно ли с помощью некоторой денормализации увеличить производительность, не жертвуя при этом целостностью. Выборочно добавляя избыточность и проводя денормализацию, вы получите базу данных, которая будет и эффективной, и защищенной от аномалий.
Нормализация базы данных
Нормализация базы данных
Среди способов организации данных есть такие, которые лучше всех остальных, а есть такие, которые более логичны, некоторые — проще. Кроме того, имеются и такие, которые, как только начинается использование базы данных, лучше других предотвращают несоответствие данных.
Если правильно не организовать структуру базы данных, то эта база станет жертвой множества разных неприятностей (которые называются аномалиями изменения). Чтобы их предотвратить, можно нормализовать структуру базы данных. Нормализация обычно влечет за собой разделение в базе данных одной таблицы на две или несколько простых.
Аномалии изменения так называются потому, что проявляются в таблице базы данных при добавлении в нее, изменении в ней или удалении из этой таблицы данных.
Иллюстрацией того, каким образом могут проявляться аномалии изменения, является таблица, приведенная на Рисунок 5.2.
Обеспечение целостности
Обеспечение целостности
База данных представляет ценность лишь тогда, когда вы в достаточной степени уверены, что находящиеся в этой базе данные правильные. Например, неправильные данные в медицинских, авиационных и космических базах данных могут привести к человеческим жертвам. Неправильные данные в других приложениях приводят не к таким плачевным последствиям, но нанести ущерб все же могут. Поэтому проектировщик базы данных должен гарантировать, что в нее неправильные данные никогда не попадут.
Некоторые неприятности нельзя остановить на уровне базы данных. Об их заблаговременном предотвращении (перед тем как они нанесут ущерб базе) должен позаботиться прикладной программист. Каждый, кто каким-либо образом отвечает за работу с базой данных, должен осознавать, какие опасности угрожают целостности ее данных, и принять все меры, чтобы свести эти опасности к нулю.
В базах данных целостность может быть нескольких видов, причем довольно-таки разных. Разными могут быть и неприятности, которые представляют угрозу целостности. В следующих разделах рассказывается о трех видах целостности: смысловой, доменной и ссылочной. Кроме того, рассматриваются некоторые угрозы целостности баз данных.
Области возможных трудностей
Области возможных трудностей
Покушения на целостность данных приходится ждать с самых разных сторон. Некоторые из этих неприятностей возникают только в многотабличных базах, в то время как другие могут произойти даже в базах, в которых имеется только одна таблица. Необходимо уметь распознавать эти угрозы и сводить вероятность их появления к минимуму.
Ограничения столбцов
Ограничения столбцов
Пример ограничения столбца показан в следующем операторе языка определения данных DDL:
| CREATE TABLE CLIENT ( | ||
| ClientName | CHARACTER (30), | NOT NULL,, |
| Address1 | CHARACTER (30), | |
| Address2 | CHARACTER (30), | |
| City | CHARACTER (25), | |
| State | CHARACTER (2), | |
| PostalCode | CHARACTER (10), | |
| Phone | CHARACTER (13), | |
| Fax | CHARACTER (13), | |
| ContactPerson | CHARACTER (30) ) ; | |
| ) ; |
В этом операторе ограничение NOT NULL, примененное к столбцу ClientName, указывает на то, что этот столбец не может принимать неопределенное значение. Другое ограничение, которое можно применять к столбцу, — это UNIQUE. Оно указывает на то, что каждое значение, находящееся в столбце, должно быть уникальным. Ограничение CHECK (проверка) особенно полезно тем, что может принимать в качестве аргумента любое корректное выражение. Рассмотрим следующий пример:
| CREATE TABLE TESTS ( | ||
| TestName | CHARACTER (30) | NOT NULL, |
| StandardCharge | NUMBER (6,2) | |
| CHECK (StandardCharge >= 0.0 | ||
| AND StandardCharge <= 200.0) | ||
| ); |
В VetLab стандартная плата за проведение анализа всегда должна быть больше или равна нулю. Кроме того, ни один из стандартных анализов не стоит больше 200 долларов. Благодаря ограничению CHECK в столбец StandardCharge не попадет никакое значение, находящееся вне диапазона 0 <= STANDARD_CHARGE <= 200. А вот еще способ установить то же самое ограничение:
CHECK (StandardCharge BETWEEN 0.0 AND 2 00.0)
Ограничения таблиц
Ограничения таблиц
Ограничение PRIMARY KEY указывает на то, что столбец, к которому оно применено, является первичным ключом. Таким образом, это ограничение относится ко всей таблице и эквивалентно комбинации двух ограничений столбца: NOT NULL и UNIQUE. Это ограничение, как показано в следующем примере, можно задавать в операторе CREATE:
| CREATE TABLE CLIENT ( | ||
| ClientName | CHARACTER (30), | PRIMARY KEY, |
| Address1 | CHARACTER (30), | |
| Address2 | CHARACTER (30), | |
| City | CHARACTER (25), | |
| State | CHARACTER (2), | |
| PostalCode | CHARACTER (10), | |
| Phone | CHARACTER (13), | |
| Fax | CHARACTER (13), | |
| ContactPerson | CHARACTER (30) ) ; | |
| ) ; |
Утверждения
Утверждение (assertion) задает ограничение для более чем одной таблицы. В следующем примере для создания утверждения применяется условие поиска, составленное для столбцов из двух таблиц
| CREAE TABLE ORDERS ( | ||
| OrderNumber | INTEGER | NOT NULL, |
| ClientName | CHARACTER (30), | |
| TestOrdered | CHARACTER (30), | |
| Salesperson | CHARACTER (30) , | |
| OrderDate | DATE | |
| ); | ||
| CREATE TABLE RESULTS ( | ||
| ResultNumber | INTEGER | NOT NULL, |
| OrderNumber | INTEGER | |
| Result | CHARACTER(50) , | |
| DateReported | DATE, | |
| PrelimFinal | CHARACTER (1), | |
| ); | ||
| CREATE ASSERTION | ||
| CHECK (NOT EXISTS SELECT * FROM ORDERS, RESULTS | ||
| WHERE ORDERS.OrderNumber = RESULTS. OrderNumber | ||
| AND ORDERS.OrderDate > RESULTS.DateReported) ; |
Благодаря этому утверждению дата анализа не будет предшествовать дате заказа теста.
Ограничения
Ограничения
В этой главе об ограничениях говорилось как о механизме, благодаря которому в табличный столбец могут быть введены только данные из домена этого столбца. Ограничение (constraint) — это правило, за исполнением которого следит СУБД. После определения базы данных можно создавать определения таблиц с заданными в этих определениях ограничениями (такими, например, как NOT NULL). Благодаря СУБД вы никогда не сможете успешно выполнить никакой транзакции, если она нарушает какое-либо ограничение.
Помни: В вашем распоряжении имеются ограничения трех разных видов.
Ограничение столбца накладывает определенное условие на столбец в таблице. Ограничение таблицы — это ограничение, относящееся ко всей таблице. Утверждением является ограничение, которое может относиться к более чем одной таблице.Ошибка оператора
Ошибка оператора
Ваши исходные данные могут быть правильными, но оператор при вводе поймет их неправильно. Ошибка такого рода может привести к тем же трудностям, что и ввод неправильных данных. И некоторые из средств для их преодоления такие же. Проверки с помощью диапазонов допустимых значений в этом случае полезны, но не являются панацеей. Есть еще одно решение. Оно состоит в том, чтобы все вводимые данные независимо проверялись еще и вторым оператором. Такой подход обходится дорого, потому что независимая проверка удваивает количество работников и затраченное на работу время. Хотя в некоторых случаях, когда целостность данных очень важна, дополнительные усилия и затраты себя оправдывают.
Первая нормальная форма
Первая нормальная форма
Чтобы быть в первой нормальной форме (1НФ), таблица должна обладать такими качествами.
Быть двумерной, т.е. состоять из строк и столбцов. В каждой строке должны находиться данные, соответствующие объекту или части объекта. В каждом столбце должны находиться данные, относящиеся к одному из атрибутов описываемого объекта. В каждой табличной ячейке (пересечении строки и столбца) должно находиться только одно значение. В каждом столбце должны быть только однотипные данные. Если, например, в какой-либо строке в столбце находится фамилия сотрудника, то тогда и во всех остальных строках в этом столбце также должны быть фамилии сотрудников. У каждого столбца должно быть уникальное имя. Никакие две строки не могут быть одинаковыми (т.е. каждая строка должна быть уникальной). Порядок расположения столбцов и строк не должны иметь значения.Таблица (отношение), находящаяся в первой нормальной форме, хотя и имеет "иммунитет" к некоторым видам аномалий изменения, но все равно подвержена остальным. Первой нормальной форме соответствует таблица SALES (см. Рисунок 5.2), но, как уже говорилось, эта таблица подвержена аномалиям удаления и вставки. Так что эта нормальная форма может быть полезной в одних приложениях и ненадежной в других.
Первичные ключи
Первичные ключи
Чтобы реализовать в базе данных VetLab идею ключей, при создании таблицы можно сразу указывать ее первичный ключ. В следующем примере будет достаточно одного столбца (при условии, что у фирм-клиентов VetLab разные названия):
| CREATE TABLE CLIENT ( | ||
| ClientName | CHARACTER (30), | PRIMARY KEY, |
| Address1 | CHARACTER (30), | |
| Address2 | CHARACTER (30), | |
| City | CHARACTER (25), | |
| State | CHARACTER (2), | |
| PostalCode | CHARACTER (10), | |
| Phone | CHARACTER (13), | |
| Fax | CHARACTER (13), | |
| ContactPerson | CHARACTER (30) ) ; |
Здесь ограничение NOT NULL (не может быть неопределенным значением), которое было в предыдущем определении таблицы CLIENT, заменено другим ограничением — PRIMARY KEY (первичный ключ). Второе ограничение подразумевает первое, потому что первичный ключ не может иметь неопределенное значение.
Несмотря на то что большинство СУБД позволяет создавать таблицу без единого ключа, важно помнить, что все таблицы базы данных должны иметь первичный ключ. Поэтому нужно ввести ограничение NOT NULL в таблицы TESTS, EMPLOYEE, ORDERS и RESULTS вместе с ограничением PRIMARY KEY, как показано в следующем примере:
CREATE TABLE TESTS (
TestName CHARACTER (30) PRIMARY KEY,
StandardCharge CHARACTER (30) ) ;
Иногда в таблице ни один единичный столбец не может гарантировать уникальность строки. В таких случаях можно использовать составной ключ. Он является сочетанием столбцов, совместное использование которых гарантирует уникальность. Представьте, что некоторые клиенты VetLab — это фирмы, имеющие свои отделения в нескольких городах. В таком случае поля ClientName будет недостаточно, чтобы различить два разных отделения одного и того же клиента. Чтобы решить эту проблему, можно определить следующий составной ключ:
| CREATE TABLE CLIENT ( | ||
| ClientName | CHARACTER (30), | PRIMARY KEY, |
| Address1 | CHARACTER (30), | |
| Address2 | CHARACTER (30), | |
| City | CHARACTER (25), | PRIMARY KEY, |
| State | CHARACTER (2), | |
| PostalCode | CHARACTER (10), | |
| Phone | CHARACTER (13), | |
| Fax | CHARACTER (13), | |
| ContactPerson | CHARACTER (30) ) ; |
Внешние ключи
Внешний ключ — это столбец или группа столбцов в таблице, соответствующие первичному ключу (т.е. ссылающиеся на первичный ключ) из другой таблицы базы данных. Внешний ключ сам по себе может и не быгь уникальным, но должен однозначно называть столбец в той таблице, на которую он ссылается.
Если столбец ClientName — это первичный ключ таблицы CLIENT, то каждая строка этой таблицы должна иметь в столбце ClientName уникальное значение. В свою очередь, в таблице ORDERS ClientName является внешним ключом. Этот внешний ключ соответствует первичному ключу таблицы CLIENT, но в таблице ORDERS он может и не быть уникальным. На самом деле вы, конечно же, надеетесь, что внешний ключ не является уникальным. Ведь если бы каждая из фирм ваших клиентов сделала у вас только один заказ и больше этого не повторяла, то ваш бизнес довольно быстро бы прекратился. На самом деле вы надеетесь, что каждой строке таблицы CLIENT соответствует много строк таблицы ORDERS, показывая этим, что почти все ваши клиенты постоянно пользуются вашими услугами.
Следующее определение таблицы ORDERS показывает, каким образом в операторе CREATE можно задавать внешние ключи:
| CREATE TABLE ORDERS ( | ||
| OrderNumber | INTEGER | NOT NULL, |
| ClientName | CHARACTER (30), | |
| TestOrdered | CHARACTER (30), | |
| Salesperson | CHARACTER (30), | |
| OrderDate | DATE ) ; | |
| CONSTRAINT BRANCHFK FOREIGN KEY (ClientName) | ||
| REFERENCES CLIENT (ClientName), | ||
| CONSTRAINT TestFK FOREIGN KEY (TestOrdered) | ||
| REFERENCES TESTS (TestName), | ||
| CONSTRAINT SalesFK FOREIGN KEY (Salesperson) | ||
| REFERENCES EMPLOYEE (EmployeeName),) ; |
Внешние ключи таблицы ORDERS связывают ее с первичными ключами таблиц CLIENT, TESTS и EMPLOYEE.
Поддержание индекса
Поддержание индекса
Если индекс создан, то его необходимо поддерживать. К счастью, вместо вас индексы поддерживает ваша система СУБД, которая обновляет их каждый раз, когда вы обновляете соответствующие таблицы данных. На этот процесс требуется немного дополнительного времени, но эти затраты того стоят. После того как вы создали индекс и СУБД его поддерживает, индекс всегда готов ускорять обработку ваших данных. И неважно, сколько раз он будет для этого использоваться.
Совет 2
Совет 2
Ясно, что лучше всего создавать индекс тогда, когда создается соответствующая ему таблица данных. Если индекс создается в самом начале и тогда же начинает поддерживаться, то вам не придется мучиться позднее с его созданием. Тогда на эту операцию придется тратить целый сеанс, длящийся довольно долго. Попробуйте предвидеть все способы, которые вам потребуются для доступа к данным, а затем для каждой такой возможности создайте свой индекс.
В некоторых продуктах СУБД имеется возможность отключать поддержку индексов. Такое, возможно, придется делать в некоторых практических приложениях, где на обновление индексов уходит много времени, которое нужно экономить. Иногда даже приходится производить обновление индексов специальной операцией, выполняемой в промежутках между часами пик.
Превышение технических возможностей базы данных
Превышение технических возможностей базы данных
Система базы данных может работать безукоризненно годами, а затем периодически начать выдавать ошибки, которые постепенно становятся все более серьезными. Это означает наступление одного из пределов емкости системы. Существуют пределы количества строк таблицы, а также предел столбцов, ограничений и других характеристик. Поэтому старайтесь контролировать соответствие текущего размера и содержимого вашей базы данных техническим характеристикам вашей СУБД. Если вы обнаружили, что предел какого-либо свойства уже близок, займитесь улучшением возможностей системы. Или заархивируйте старые данные, к которым вы больше не обращаетесь, а затем удалите их из базы данных.
Проектирование базы данных
Проектирование базы данных
При проектировании базы данных выполните следующие основные действия (подробно о каждом из них рассказывается в последующих разделах).
Решите, какие объекты должны быть в вашей базе данных. Установите, какие из этих объектов должны быть таблицами, а какие — столбцами этих таблиц. Определите таблицы в соответствии с тем, как вы решили организовать объекты.Возможно, вы захотите назначить ключом какой-либо столбец таблицы или комбинацию ее столбцов. Ключи позволяют быстро найти в таблице нужную вам строку.
В последующих разделах подробно описываются эти действия, а также рассматриваются некоторые другие вопросы, связанные с проектированием базы данных.
Работа с индексами
Работа с индексами
Спецификация SQL:2003 к теме индексов не обращается, но это не значит, что они являются редкой или даже необязательной частью системы баз данных. Индексы поддерживаются каждой реализацией SQL, но общего соглашения по их поддержке не существует. В главе 4 было показано, как создать индекс с помощью RAD-инструмента Microsoft Access. Чтобы разобраться, как индексы используются в конкретной системе управления базами данных, необходимо обратиться к ее документации.
Смысловая целостность
Смысловая целостность
Каждая таблица базы данных соответствует какому-либо объекту реального мира. Такой объект может быть физическим или умозрительным, но его существование в некотором смысле не зависит от базы данных. Если таблица полностью соответствует объекту, который она моделирует, то она обладает смысловой целостностью. Чтобы иметь такую целостность, таблица должна иметь первичный ключ. Этот ключ однозначно определяет каждую строку таблицы. Если его нет, то нет и уверенности, что вы получите нужную вам строку.
Чтобы поддержать целостность объекта, необходимо для столбца или группы столбцов, из которых состоит первичный ключ, указать NOT NULL. Кроме того, для первичного ключа еще необходимо ограничение UNIQUE. В некоторых реализациях SQL такое ограничение указывается непосредственно в определении таблицы. В других же реализациях его приходится задавать уже после того, как будет указано, каким образом данные следует добавлять в таблицу, изменять и удалять из нее. Проще всего добиться, чтобы первичный ключ был и NOT NULL, и UNIQUE, — это использовать ограничение PRIMARY KEY, как показано в следующем примере:
| CREATE TABLE CLIENT ( | ||
| ClientName | CHARACTER (30), | PRIMARY KEY, |
| Address1 | CHARACTER (30), | |
| Address2 | CHARACTER (30), | |
| City | CHARACTER (25), | |
| State | CHARACTER (2), | |
| PostalCode | CHARACTER (10), | |
| Phone | CHARACTER (13), | |
| Fax | CHARACTER (13), | |
| ContactPerson | CHARACTER (30) ) ; |
Альтернативой этому способу является использование ограничения NOT NULL в сочетании с UNIQUE:
| CREATE TABLE CLIENT ( | ||
| ClientName | CHARACTER (30), | NOT NULL,, |
| Address1 | CHARACTER (30), | |
| Address2 | CHARACTER (30), | |
| City | CHARACTER (25), | |
| State | CHARACTER (2), | |
| PostalCode | CHARACTER (10), | |
| Phone | CHARACTER (13), | |
| Fax | CHARACTER (13), | |
| ContactPerson | CHARACTER (30) ) ; | |
| UNIQUE (ClientName)) ; |
Ссылочная целостность
Ссылочная целостность
Даже если в базе данных для каждой таблицы установлены целостность объекта и доменная целостность, то этой базе все равно грозят неприятности, происходящие из-за того, что связь одной таблицы с другой не согласована. В большинстве хорошо спроектированных баз данных в каждой таблице имеется как минимум один столбец, который ссылается на столбец из другой таблицы той же базы. Такие ссылки играют важную роль при поддержании общей целостности базы данных. Впрочем, те же ссылки делают возможными аномалии обновления.
Аномалии обновления — это неприятности, которые могут происходить после обновления значений в строке базы данных.
В целом отношения между таблицами не являются равноправными. Обычно одна таблица зависит от другой. Скажем, у вас, например, имеется база данных с таблицами CLIENT (фирма-клиент) и ORDERS (заказы). Вы можете намеренно ввести в таблицу CLIENT данные фирмы-клиента еще до того, как ею будут сделаны какие-либо заказы. Однако в таблицу ORDERS нельзя будет ввести ни одного заказа, если в первой, CLIENT, не будет записи для клиента, делающего этот заказ. Получается, что таблица ORDERS зависит от таблицы CLIENT. Такой порядок часто называют родительско-дочерним отношением таблиц, при котором CLIENT — это родительская, a ORDERS — дочерняя таблица. Дочерний элемент базы данных зависит от родительского. Обычно первичный ключ родительской таблицы — это столбец (или группа столбцов), который имеется и в дочерней таблице. И там он уже является внешним ключом. Во внешнем ключе могут находиться неопределенные значения, и ему не нужно быть уникальным.
Аномалии обновления возникают несколькими способами. Например, фирма-клиент не делает у вас заказов, и вы хотите удалить ее данные из базы. И если она уже сделала у вас некоторые заказы, данные о которых записаны в таблице ORDERS, то удаление ее данных из таблицы CLIENT может вызвать трудности. Дело в том, что тогда в дочерней таблице ORDERS остались бы записи, для которых не было бы соответствующих записей в главной таблице CLIENT. Аналогичные трудности могут возникнуть и тогда, когда запись в дочернюю таблицу добавляется, а соответствующее добавление в родительскую еще не сделано. Все изменения первичного ключа, происходящие в любой строке родительской таблицы, должны отражаться в соответствующих внешних ключах всех дочерних таблиц. Если этого не произойдет, образуются аномалии обновления.
Большинство трудностей, связанных со ссылочной целостностью, можно свести к минимуму, если тщательно управлять процессом обновления. В некоторых случаях необходимо каскадное удаление из родительской таблицы и ее дочерних таблиц. Чтобы при удалении строки из родительской таблицы произошли каскадные удаления, необходимо из всех дочерних таблиц удалить строки, значение внешнего ключа которых равно значению первичного ключа строки, удаляемой из главной таблицы. Рассмотрим следующий пример:
| CREATE TABLE CLIENT ( | ||
| ClientName | CHARACTER (30), | PRIMARY KEY, |
| Address1 | CHARACTER (30), | |
| Address2 | CHARACTER (30), | |
| City | CHARACTER (25), | NOT NULL, |
| State | CHARACTER (2), | |
| PostalCode | CHARACTER (10), | |
| Phone | CHARACTER (13), | |
| Fax | CHARACTER (13), | |
| ContactPerson | CHARACTER (30) ) ; | |
| CREATE TABLE TESTS ( | ||
| TestName | CHARACTER (30) | PRIMARY KEY, |
| StandardCharge | CHARACTER (30) ) ; | |
| CREATE TABLE EMPLOYEE ( | ||
| EmployeeName | CHARACTER (30) | PRIMARY KEY, |
| Address1 | CHARACTER (30), | |
| Address2 | CHARACTER (30), | |
| City | CHARACTER (25), | |
| State | CHARACTER (2), | |
| PostalCode | CHARACTER (10), | |
| HomePhone | CHARACTER (13), | |
| OfficeExtension | CHARACTER (4), | |
| HireDate | DATE, | |
| JobClassification | CHARACTER (10), | |
| HourSalComm | CHARACTER (1) ) ; | |
| CREATE TABLE ORDERS ( | ||
| OrderNumber | INTEGER | PRIMARY KEY, |
| ClientName | CHARACTER (30), | |
| TestOrdered | CHARACTER (30), | |
| Salesperson | CHARACTER (30), | |
| OrderDate | DATE ) ; | |
| CONSTRAINT NameFK FOREIGN KEY (ClientName) | ||
| REFERENCES CLIENT (ClientName) | ||
| ON DELETE CASCADE, | ||
| CONSTRAINT TestFK FOREIGN KEY (TestOrdered) | ||
| REFERENCES TESTS (TestName) | ||
| ON DELETE CASCADE, | ||
| CONSTRAINT SalesFK FOREIGN KEY (Salesperson) | ||
| REFERENCES EMPLOYEE (EmployeeName) | ||
| ON DELETE CASCADE ) ; |
Ограничение NameFK делает поле ClientName внешним ключом, который указывает на столбец ClientName таблицы CLIENT. Когда в таблице CLIENT удаляется строка, то в таблице ORDERS автоматически удаляются все строки, у которых в столбце ClientName имеется то же значение, что и в столбце ClientName удаляемой строки таблицы CLIENT. Происходит каскадное удаление— вначале в таблице CLIENT, а затем в таблице ORDERS. To же самое верно для внешних ключей таблицы ORDERS, которые являются первичными ключами таблиц TESTS и EMPLOYEE.
Возможно, вы не хотите производить каскадное удаление, а вместо этого хотите заменить внешний ключ подчиненной таблицы значением NULL. Проанализируйте следующий вариант предыдущего примера:
| CREATE TABLE ORDERS ( | ||
| OrderNumber | INTEGER | PRIMARY KEY, |
| ClientName | CHARACTER (30), | |
| TestOrdered | CHARACTER (30), | |
| Salesperson | CHARACTER (30), | |
| OrderDate | DATE ) ; | |
| CONSTRAINT NameFK FOREIGN KEY (ClientName) | ||
| REFERENCES CLIENT (ClientName), | ||
| CONSTRAINT TestFK FOREIGN KEY (TestOrdered) | ||
| REFERENCES TESTS (TestName), | ||
| CONSTRAINT SalesFK FOREIGN KEY (Salesperson) | ||
| REFERENCES EMPLOYEE (EmployeeName),) ; | ||
| ON DELETE SET NULL ) ; |
Ограничение SalesFK определяет поле Salesperson внешним ключом, который указывает на столбец EmployeeName таблицы EMPLOYEE. Если сотрудница, работавшая вашим представителем при оформлении заказов, уходит из компании, вы удаляете ее строку из таблицы EMPLOYEE. Co временем ее место займет другой работник. А сейчас удаление строки с ее данными из таблицы EMPLOYEE приводит к заменам значений. Эти замены состоят в том, что в таблице ORDERS во всех строках с заказами, оформленными этим представителем, столбцу Salesperson присваивается неопределенное значение.
Есть и другой способ предохранить базу от несогласованных данных. Он состоит в том, чтобы отказаться от разрешения добавлять строки в дочернюю таблицу, пока в родительской таблице не появится соответствующая им строка. Если вы откажетесь разрешать добавление строк в дочерней таблице, пока не будет нужной строки в родительской таблице, то таким образом предотвратите появление "строк-сирот" в дочерней таблице. Это позволит легко поддерживать согласованность таблиц. Еще одна возможность состоит в том, чтобы запретить изменять первичный ключ таблицы. В этом случае можно не беспокоиться об обновлении внешних ключей в других таблицах, которые зависят от этого первичного ключа.
базы данных VetLab
Таблица 5.1. Таблицы базы данных VetLab.
| Таблица | Столбцы |
| CLIENT (фирма-клиент) | Client Name (название фирмы-клиента) |
| Address 1 (адрес 1) | |
| Address 2 (адрес 2) | |
| City (город) | |
| State (штат) | |
| Postal Code (почтовый код) | |
| Phone (телефон) | |
| Fax (факс) | |
| Contact Person (контактный представитель) | |
| TESTS (анализы) | Test Name (название анализа) |
| Standard charge (стандартная цена) | |
| EMPLOYEE (сотрудник) | Employee Name (фамилия сотрудника) |
| Address 1 (адрес 1) | |
| Address 2 (адрес 2) | |
| City (город) | |
| State (штат) | |
| Postal Code (почтовый код) | |
| Home Phone (домашний телефон) | |
| Office Extension (телефонный номер в офисе) | |
| Hire Date (дата приема на работу) | |
| Job classification (трудовая классификация) | |
| Hourly/Salary/Commission (почасовая оплата/зарплата/комиссионные) | |
| ORDERS (заказы) | Order Number (номер заказа) |
| Client Name (название фирмы-клиента) | |
| Test ordered (заказанный анализ) | |
| Responsible Salesperson (сотрудник, принявший заказ) | |
| Order Date (дата заказа) | |
| RESULTS (результаты) | Result Number (номер результата) |
| Order Number (номер заказа) | |
| Result (результат) | |
| Date Reported (сообщенная дата) | |
| Preliminary / Final (предварительный/окончательный) |
Таблицы, определенные в табл. 5.1, можно создать или с помощью инструмента для быстрой
разработки приложений (Rapid Application Development, RAD), или с помощью языка определения
данных (Data Definition Language, DDL), входящего в состав SQL, как показано ниже.
| CREATE TABLE CLIENT ( | ||
| ClientName | CHARACTER (30), | NOT NULL, |
| Address1 | CHARACTER (30), | |
| Address2 | CHARACTER (30), | |
| City | CHARACTER (25), | |
| State | CHARACTER (2), | |
| PostalCode | CHARACTER (10), | |
| Phone | CHARACTER (13), | |
| Fax | CHARACTER (13), | |
| ContactPerson | CHARACTER (30) ) ; | |
| CREATE TABLE TESTS ( | ||
| TestName | CHARACTER (30) | NOT NULL, |
| StandardCharge | CHARACTER (30) ) ; | |
| CREATE TABLE EMPLOYEE ( | ||
| EmployeeName | CHARACTER (30) | NOT NULL, |
| Address1 | CHARACTER (30), | |
| Address2 | CHARACTER (30), | |
| City | CHARACTER (25), | |
| State | CHARACTER (2), | |
| PostalCode | CHARACTER (10), | |
| HomePhone | CHARACTER (13), | |
| OfficeExtension | CHARACTER (4), | |
| HireDate | DATE, | |
| JobClassification | CHARACTER (10), | |
| HourSalComm | CHARACTER (1) ) ; | |
| CREATE TABLE ORDERS ( | ||
| OrderNumber | INTEGER | NOT NULL, |
| ClientName | CHARACTER (30), | |
| TestOrdered | CHARACTER (30), | |
| Salesperson | CHARACTER (30), | |
| OrderDate | DATE ) ; | |
| CREATE TABLE RESULTS ( | ||
| ResultNumber | INTEGER | NOT NULL, |
| OrderNumber | INTEGER | |
| Result | CHARACTER (50), | |
| DateReported | DATE, | |
| PrelimFinal | CHARACTER (1) ) ; |
Эти таблицы относятся друг к другу посредством общих атрибутов (столбцов).
Таблица CLIENT связана с таблицей ORDERS с помощью столбца ClientName. Таблица TESTS связана с таблицей ORDERS с помощью столбца TestName (TestOrdered). Таблица EMPLOYEE связана с таблицей ORDERS с помощью столбца ЕmployeeName (Salesperson). Таблица RESULTS связана с таблицей ORDERS с помощью столбца OrderNumber.Есть простой способ сделать таблицу неотъемлемой частью реляционной базы. Надо связать эту таблицу с помощью общего столбца как минимум с еще одной таблицей из той же базы. Отношения между таблицами показаны на Рисунок 5.1.
Таблица CLIENT
Таблица 5.2. Таблица CLIENT
| ClientName | Address1 | Address2 | City | State |
| Butternut Animal Clinic | 5 Butternut Lane | Hudson | NH | |
| Amber Veterinary, Inc. | 470 Kolvir Circle | Amber | Ml | |
| Vets R Us | 2300 Geoffrey Road | Suite 230 | Anaheim | CA |
| Doggie Doctor | 32 Terry Terrace | Nutley | NJ | |
| The Equistrian Center | Veterinary Department | 7890 Paddock Parkway | Gallup | NM |
| Dolphin Institute | 1002 Marine Drive | Key West | FL | |
| J.C.Campbell, Credit Vet | 2500 Main Street | Los Angeles | CA | |
| Wenger's Worm Farm | 15 Bait Boulevard | Sedona | AZ |
Строки следуют в таком порядке, что значения в столбце ClientName располагаются не по алфавиту. Строки находятся в том порядке, в каком их кто-то вводил.
Индекс для этой таблицы CLIENT может выглядеть примерно так, как табл. 5.3.
Индекс по названию клиента для таблицы CLIENT
Таблица 5.3. Индекс по названию клиента для таблицы CLIENT
| ClientName | Указатель к таблице данных |
| Amber Veterinary, Inc. | 2 |
| Butternut Animal Clinic | 1 |
| Doggie Doctor | 4 |
| Dolphin Institute | 6 |
| J.C.Campbell, Credit Vet | 7 |
| The Equistrian Center | 5 |
| Vets R Us | 3 |
| Wenger's Worm Farm | 8 |
В индексе находятся поле, которое является его основой (в данном случае это поле ClientName), и указатель к таблице данных. Значение указателя, расположенное в каждой строке индекса, является номером соответствующей строки таблицы данных.
SALES разбита на две другие
Рисунок 5.3. Таблица SALES разбита на две другие
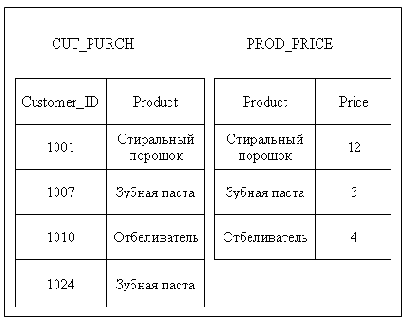
На Рисунок 5.3 изображено, что таблица SALES разделена на две новые таблицы.
Таблица CUST_PURCH (покупки) содержит данные о сделанных у вас покупках. Таблица PROD_PRICE (цена товара) содержит данные о ценах ваших товаров.Вот теперь можно удалять из таблицы CUST_PURCH строку с данными о покупателе 1001, не теряя при этом других данных, — о том, что стиральный порошок стоит 12 долларов. Данные о ценах теперь хранятся в другой таблице, PROD_PRICE. И еще, данные о сухом дезодоранте можно заносить в таблицу PROD_PRICE, независимо от того, купил кто-то этот товар или нет. Дело в том, что информация о покупках хранится не в этой таблице, а в CUST_PURCH.
Нормализацией называется процесс разделения одной таблицы на множество других, каждая из которых посвящена отдельной теме. Нормализация, которая решает одну проблему, может не оказывать никакого влияния на другие. И чтобы в конце концов получить такие таблицы, которые посвящены каждая единственной теме, может потребоваться несколько последовательных нормализации. В базе данных у каждой таблицы должна быть одна и только одна главная тема. Ведь если таблица посвящена хотя бы двум темам, то в такой таблице иногда бывает трудно что-то понять.
Таблицы можно классифицировать по видам тех аномалий изменения, которым эти таблицы подвержены. В своей статье, выпущенной в 1970 году (первой, где была описана реляционная модель), доктор И.Ф. Кодд (E.F. Codd) диагностирует три источника аномалий изменения и для "лечения" от этих аномалий выписывает три "лекарства". Это первая, вторая и третья нормальные формы (1НФ, 2НФ, ЗНФ). В последующие годы И.Ф. Кодд и другие специалисты открыли как другие виды аномалий, так и средства против них — новые нормальные формы. Нормальная форма Бойса-Кодда (НФБК) (Boyce-Codd normal form, BCNF), четвертая нормальная форма (4НФ) и пятая нормальная форма (5НФ) — каждая из них обеспечивала еще более высокую защиту от аномалий изменения, чем их предшественницы. В 1981 году появилась статья, написанная Р. Фейджином (R. Fegin), где описана доменно-ключевая нормальная форма (ДКНФ) (domain/key normal form, DKNF). Эта последняя нормальная форма гарантирует отсутствие аномалий изменения.
Нормальные формы являются вложенными в том смысле, что таблица, находящаяся в 2НФ, автоматически находится и в ШФ. Аналогично, таблица, которая находится в ЗНФ, находится ив 2НФ и т.д. Для большинства приложений приведения базы данных в ЗНФ вполне достаточно, чтобы обеспечить в этой базе высокую степень целостности. Впрочем, чтобы была абсолютная уверенность в целостности базы данных, необходимо привести ее в ДКНФ.
После проведения максимально возможной нормализации своей базы данных вам для увеличения ее производительности, вероятно, захочется выполнить выборочную денормализацию. В таком случае надо полностью отдавать себе отчет, с какими аномалиями вы, возможно, столкнетесь.
Таблицы и связи базы данных VetLab
Рисунок 5.1. Таблицы и связи базы данных VetLab
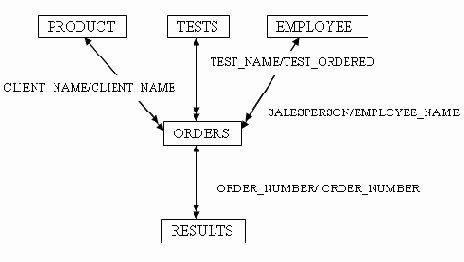
На Рисунок 5.1 показаны четыре различных отношения типа "один ко многим". В изображении отношения одна стрелка указывает на сторону "один", а двойная — на сторону "многие".
Один клиент может сделать множество заказов, но каждый заказ делается одним и только одним клиентом. Каждый анализ может быть указан во многих заказах, но каждый заказ оформляется на один и только один анализ. Каждый заказ принимается одним и только одним сотрудником (т.е. представителем вашей компании), но каждый представитель может принимать (и, как вы надеетесь, принимает) множество заказов. В результате выполнения каждого заказа может получиться несколько предварительных результатов и один окончательный, но каждый результат относится к одному и только одному заказу.Как видно на рисунке, атрибут, который связывает одну таблицу с другой, может в каждой из этих таблиц называться по-своему. Однако тип данных у этих атрибутов должен совпадать.
Домены, символьные наборы, сопоставления и трансляции
Хотя главными компонентами базы данных являются таблицы, но другие ее элементы также играют определенную роль. В главе 1 домен табличного столбца был определен как набор всех значений, которые допустимы для этого столбца. Создание с помощью ограничений четко определенных доменов табличных столбцов — это важная часть проектирования базы данных.
Реляционными базами данных пользуются не только те, кто разговаривает на американском варианте английского языка. С этими базами можно работать, используя и другие языки, даже те, у которых другие символьные наборы. Даже если база данных создана с использованием только английского языка, некоторые приложения могут запросить специальные символьные наборы. SQL:2003 позволяет точно определить тот набор, который вам нужно использовать. Фактически можно для каждого табличного столбца использовать отдельный символьный набор. В языках, отличных от SQL, подобной гибкости обычно нет.
Сопоставление, или последовательность сопоставления, — это набор правил, которые определяют, каким образом сравниваются друг с другом строки, состоящие из элементов определенного символьного набора. Каждый символьный набор имеет свое сопоставление по умолчанию. В сопоставлении по умолчанию для символьного набора ASCII В следует после А, а С — после В. Поэтому при сравнении считается, что А меньше В, а С больше В. С другой стороны, SQL:2OO3 дает возможность применять к символьному набору и другие сопоставления. Повторяю снова, что в других языках подобной степени гибкости обычно нет.
Иногда данные в базе кодируются с помощью одного символьного набора, но работать с ними нужно с помощью другого набора. У вас, например, есть данные, закодированные в немецком символьном наборе, но те немецкие символы, которые не входят в набор ASCII, на вашем принтере не печатаются. Трансляция — это функциональная возможность SQL:2003, позволяющая преобразовывать символьные строки из одного набора в другой. Трансляция, например, позволяет преобразовывать один символ в два, в частности немецкий u — в ue из ASCII, или может преобразовывать символы из нижнего регистра в верхний. Можно даже преобразовать один алфавит в другой, например алфавит языка иврит в символы ASCII.
Третья нормальная форма
Третья нормальная форма
Все-таки есть аномалии изменения, против которых таблицы во второй нормальной форме беззащитны. Эти аномалии связаны с транзитивными зависимостями.
Помни: Транзитивная зависимость имеет место тогда, когда один атрибут зависит от второго, а второй, в свою очередь, от третьего. Удаления в таблице, имеющей такие зависимости, могут вызвать ненужную потерю информации. Отношение в третьей нормальной форме — это отношение во второй нормальной форме, не имеющее транзитивных зависимостей.
Снова посмотрим на таблицу SALES (продажи) (см. Рисунок 5.2), которая, как вам известно, находится в первой нормальной форме. Пока для каждого значения CustomerlD (идентификатор покупателя) можно вводить только одну строку, то имеется первичный ключ, состоящий из одного атрибута, поэтому таблица находится во второй нормальной форме. Однако таблица все равно подвержена аномалиям. А что если покупателю 1010, к примеру, не повезет с отбеливателем и он вернет свою покупку, получив назад деньги? Вы собираетесь удалить из таблицы третью строку, в которой записаны данные о том, что покупатель 1010 приобрел отбеливатель. Но тут возникает проблема. Если строка будет удалена, то также будут удалены данные о том, что цена отбеливателя составляет 4 доллара. Такая ситуация является примером транзитивной зависимости. Атрибут Price (цена) зависит от атрибута Product (товар), который, в свою очередь, зависит от первичного ключа CustomerlD.
Проблема транзитивной зависимости решается с помощью разделения таблицы SALES на две. Две таблицы, CUST_PURCH (покупки) и PROD_PRICE (цена товара), составляют базу данных, находящуюся в третьей нормальной форме (см. Рисунок 5.3).
Ускорение работы базы данных с помощью ключей
Ускорение работы базы данных с помощью ключей
В проектировании баз данных используется хорошее правило: в таблице каждая строка отличается от любой другой, т.е. каждая строка должна быть уникальной. Иногда вам может потребоваться для определенной цели — например, для статистического анализа — извлечь из своей базы некоторые данные и создать на их основе таблицы, где строки не обязательно являются уникальными. Для данного конкретного случая правило отсутствия дублирования может не выполняться. Однако в общем его нужно строго придерживаться.
Ключ — это атрибут или сочетание атрибутов, которое однозначно определяет строку в таблице. Чтобы получить доступ к строке, необходимо иметь способ, позволяющий отличить эту строку от всех остальных. Так как ключи уникальны, они позволяют выполнять такой доступ. Более того, ключ никогда не должен содержать неопределенное значение. При использовании неопределенных ключей две строки, содержащие такие ключевые поля, были бы неотличимы друг от друга.
Что касается примера с ветеринарной лабораторией, то здесь в качестве ключей вы можете назначить подходящие для этого столбцы. В таблице CLIENT хороший ключ получается из столбца ClientName. Этот ключ может отличить любого клиента от всех остальных. Таким образом, ввод значения в этот столбец становится обязательным для каждой строки таблицы CLIENT. Из столбцов TestName и EmployeeName получаются хорошие ключи для таблиц TESTS и EMPLOYEE. To же относится к столбцам OrderNumber и ResultNumber таблиц ORDERS и RESULTS соответственно. В любом случае надо проверять, вводится ли в каждую строку уникальное значение ключа.
Ключи могут быть двух видов: первичные и внешние. Ключи, о которых говорилось в предыдущем абзаце, на самом деле являются первичными. Благодаря им гарантируется уникальность строк. О внешних ключах рассказывается в этом разделе чуть позже.
Определение отношений между элементами базы
В этой главе...
Что должно быть в базе данных Определение отношений между элементами базы данных Связывание таблиц с помощью ключей Проектирование целостности данных Нормализация базы данных В этой главе будет представлен пример создания многотабличной базы данных. Первый шаг при проектировании такой базы — решить, что в ней должно быть, а чего не должно. Второй шаг состоит в том, чтобы установить, каким образом имеющиеся в базе элементы будут связаны друг с другом, и создать таблицы с учетом этой информации. Я расскажу, как использовать ключи для получения быстрого доступа к индивидуальным табличным записям и индексам.
База данных должна не просто хранить данные, но и защищать их от повреждений. Далее в этой главе обсуждаются методы защиты целостности данных. Одним из самых важных методов является нормализация, поэтому я расскажу о различных "нормальных" формах и проблемах, решаемых с их помощью.
В таблице SALESJRACK составной
Рисунок 5.4. В таблице SALESJRACK составной ключ состоит из столбцов CustomerlD и Product
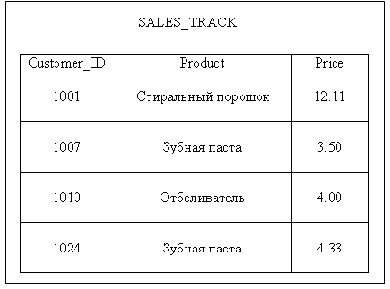
На Рисунок 5.4 столбец CustomerlD однозначно строку не определяет. В двух строках его значения равны 1001. Еще в двух равны 1010. Однако строку однозначно определяет комбинация столбцов CustomerlD и Product. Вместе эти столбцы и являются составным ключом.
Если бы не то условие, что одни покупатели имеют скидку, а другие нет, то таблица не была бы во второй нормальной форме, потому что столбец Price (цена), являющийся неключевым атрибутом, зависел бы только от столбца Product (товар). Но так как часть покупателей имеет скидку, то PRICE зависит и от CustomerlD, и от Product, так что таблица все же находится во второй нормальной форме.
При проектировании структуры базы данных
Внимание
При проектировании структуры базы данных важно учитывать интересы ее будущих пользователей, а также лиц, принимающих решения на основе ее информации. Если созданная вами "разумная" структура не будет соответствовать способу, каким эти люди работают с информацией, то в лучшем случае ваша система может разочаровать своих пользователей. Она может даже выдавать неверную информацию, что намного хуже, чем просто быть трудной в использовании. Такого не должно быть! Хорошо подумайте, перед тем как принимать решение о структуре таблиц. Рассмотрим пример, который показывает процесс создания многотабличной базы данных. Скажем, вы только что основали VetLab — клиническую микробиологическую лабораторию, где проводятся анализы проб, присланных из ветеринарных фирм. Конечно, вам бы хотелось иметь данные:
о клиентах; о выполненных анализах; о сотрудниках; о заказах; о результатах. У каждого их этих объектов имеются связанные между собой атрибуты. Для клиента такие атрибуты — название, адрес и другая информация для контакта. Для анализа — название и стандартная оплата. Для каждого сотрудника — его адрес, телефон, должность, квалификация и уровень оплаты. О заказе необходимо знать, кто его заказчик, когда заказ был оформлен и какой именно анализ в нем указан. А что касается результатов анализов, то необходимо знать данные, полученные при его проведении, был ли анализ предварительным или окончательным, а также номер его заказа.
Внимание
Не попадитесь на удочку, создавая индексы для получения относящихся к заказам данных, которые вы вряд ли когда-нибудь будете использовать. С поддержкой индекса связана определенная потеря производительности, потому что эта поддержка является дополнительной операцией, которую компьютер должен выполнять каждый раз, когда модифицирует поле индекса или добавляет (удаляет) строку в таблице данных. Чтобы добиться оптимальной производительности, создавайте только те индексы, которые действительно собираетесь использовать в качестве ключей получения данных, и только для таблиц, имеющих большое количество строк. Ведь в противном случае индексы только ухудшат производительность. Совет 3
Совет 3
Вам, возможно, потребуется составить нечто похожее на месячный или квартальный отчет, где нужны данные, выстроенные в каком-либо необычном порядке. В таком случае, перед тем как генерировать отчет, создайте индекс. Затем, после того как отчет будет готов, удалите этот индекс. Он не должен обременять СУБД, которой пришлось бы его поддерживать в течение долгого времени между отчетами.
Вторая нормальная форма
Вторая нормальная форма
Чтобы оценить вторую нормальную форму, необходимо понимать, что такое функциональная зависимость. Функциональная зависимость — это связь между атрибутами. Один атрибут функционально зависит от другого, если значение второго атрибута определяет значение первого. Значение первого атрибута можно определить, зная значение второго.
Предположим, например, что у таблицы имеются атрибуты (столбцы): StandardCharge (стандартная плата), NumberOfTests (число анализов) и TotalCharge (общая плата), которые связаны следующей формулой:
TotalCharge = StandardCharge * NumberOfTests
В таком случае столбец TotalCharge функционально зависим от двух других: Standard-Charge и NumberOfTests. Если известны значения StandardCharge и NumberOfTests, то можно определить значение TotalCharge.
Каждая таблица в первой нормальной форме должна иметь уникальный первичный ключ. Этот ключ может состоять из одного или множества столбцов. Ключ, состоящий из множества столбцов, называется составным. Чтобы таблица была во второй нормальной форме (2НФ), все ее неключевые атрибуты (столбцы) должны зависеть от всего ключа. Таким образом, каждое отношение в 1НФ, которое имеет ключ, состоящий из одного атрибута, автоматически находится во второй нормальной форме. Если у отношения имеется составной ключ, то все неключевые атрибуты должны зависеть от всех компонентов ключа. Пусть у вас есть таблица с неключевыми атрибутами, которые не выполняют это условие. Тогда вам, возможно, захочется разбить таблицу на не менее чем две новые, чтобы в каждой из них все неключевые атрибуты зависели от всех компонентов первичного ключа.
Звучит достаточно запутанно? Тогда для ясности рассмотрим пример. Пусть имеется таблица SALES_TRACK (данные о продажах), аналогичная таблице SALES (продажи) (см. Рисунок 5.2). Правда, вместо того чтобы записывать для каждого покупателя только одну покупку, вы вводите для него строку каждый раз, когда он впервые покупает какой-либо вид товара.
Кроме того, первые покупатели товара (те, у кого значения столбца CustomerlD лежат в диапазоне 1001-1009) получают скидку. Некоторые строки этой таблицы приведены на Рисунок 5.4.
Ввод неправильных данных
Ввод неправильных данных
В документах или файлах с исходной информацией, которыми вы пользуетесь для заполнения своей базы, могут быть неправильные данные. Они могут быть неправильным вариантом правильных данных или быть совсем не теми данными, которые вам нужны. Проверки с помощью диапазонов допустимых значений показывают, имеют ли данные доменную целостность. Хотя такие проверки и помогают преодолеть некоторые трудности, но, откровенно говоря, далеко не все. Если в полях имеются неправильные значения, не выходящие из допустимого диапазона, то в результате проверок ничего подозрительного обнаружено не будет.
Зачем нужен индекс
Зачем нужен индекс
Предположим, мне нужно обрабатывать таблицу в том порядке, при котором значения из поля ClientName будут выстроены по алфавиту. При этом у меня есть индекс, в котором значения из этого поля выстроены именно по алфавиту. Тогда свою работу я смогу выполнять так же быстро, как если бы сами записи таблицы данных были выстроены в том же порядке. У меня есть возможность последовательно перемещаться по строкам индекса и при этом немедленно переходить, используя указатель индекса, на те строки таблицы данных, которые соответствуют строкам индекса.
При использовании индекса время обработки таблицы пропорционально N, где N — количество ее строк. А при выполнении той же операции, но без индекса, время обработки таблицы
пропорционально NlgN, где igN — логарифм N по основанию 2. Для небольших таблиц разница между этими значениями получается незначительная, но для больших — огромная. Некоторые операции с большими таблицами без помощи индексов требуют слишком много времени.
Например, у вас есть таблица с 1000000 записей (N = 1000000) и на обработку каждой записи уходит одна миллисекунда (одна тысячная секунды). Если у вас есть индекс, то на обработку всей таблицы уйдет только 1000 секунд, т.е. меньше 17 минут. Однако, чтобы получить тог же результат без индекса, таблицу придется обрабатывать 100000x20 раз. Таким образом, этот процесс должен занять 20000 секунд, т.е. больше пяти с половиной часов. Думаю, вы согласитесь, что разница между семнадцатью минутами и пятью с половиной часами довольно-таки существенная. Это и есть та разница, которая создается индексированием записей.
Злой умысел
Злой умысел
Не следует исключать возможности умышленной порчи данных. Ваша первая линия обороны — это запрещение доступа к базе данных потенциально опасным пользователям, а также ограничение доступа всем остальным только тем, что им нужно. Вторая линия —- хранение резервных копий данных в безопасном месте. Периодически проверяйте, насколько защищена ваша база данных.
Добавление данных только в выбранные столбцы
Добавление данных только в выбранные столбцы
Иногда нужно где-то отметить, что объект существует, даже если по нему еще нет всех данных. Если у вас для таких объектов есть таблица базы данных, то строку по новому объекту можно вставить в нее, не заполняя значениями все столбцы этой строки. И если вы хотите, чтобы таблица была в первой нормальной форме, то необходимо вставить столько данных, чтобы можно было отличать новую строку от всех остальных строк этой таблицы. (О первой нормальной форме см. в главе 5.) Для этого в новой строке достаточно вставить первичный ключ. Кроме этого ключа вставляйте все остальные данные, которые известны об этом объекте. В тех столбцах, куда данные не вводятся, остаются значения NULL.
Ниже приведен пример такого частичного ввода строки.
INSERT INTO CUSTOMER (CustomerlD, FirstName, LastName)
VALUES (:vcustid, 'Tyson1, 'Tylor') ;
Вы вставляете только уникальный идентификационный номер клиента, а также его имя и фамилию. А в остальных столбцах этой строки будут находиться значения NULL.
Добавление данных в виде отдельных записей
Добавление данных в виде отдельных записей
В большинстве СУБД поддерживается ввод данных с помощью форм. Такая возможность позволяет создать экранную форму, в которой для каждого табличного столбца из базы данных имеется свое поле. Находящиеся в форме метки полей позволяют легко определить, какие данные следует вводить в каждое поле. Оператор вручную вводит в форму все данные, предназначенные для одной строки. После того как СУБД примет новую строку, она очищает форму, чтобы в нее можно было вводить данные для следующей строки. Таким образом можно легко добавить в таблицу данные в виде отдельных строк одну за другой.
Ввод данных с помощью форм легко использовать, кроме того, при таком вводе допускается меньше ошибок, чем при вводе списков значений, отделяемых друг от друга запятыми. Основная трудность ввода данных с помощью форм состоит в том, что он не является стандартным. В различных системах СУБД имеются собственные методы создания форм. Для оператора, занятого вводом данных, не имеет значения, каким образом создана форма ввода. Можно сделать та, что форма в любой СУБД будет выглядеть в основном одинаково. А вот разработчику приложений при переходе к новым инструментам разработки приходится учиться с самого начала. При вводе данных с помощью форм встречается и другая трудность. Она состоит в том, что в некоторых реализациях нельзя выполнять полную проверку правильности вводимых данных.
Самый лучший способ поддерживать на высоком уровне целостность данных в базе — это не вводить неправильные данные. Предотвратить неправильный ввод можно, применяя ограничения к полям формы ввода. Это гарантирует, что в базу данных попадут только те значения, которые имеют правильный тип данных и являются частью заранее определенного диапазона. Конечно, с помощью такого ограничения нельзя предотвратить все возможные ошибки, но "отловить" некоторые все же можно.
Если в таблицу из базы данных вводятся значения, предназначенные для отдельной строки, то в команде INSERT используется следующий синтаксис:
INSERT INTO таблица_1 [(столбец_1, столбвц_2, ..., столбец_n)]
VALUES (значение_1, значение_2, ..., значение_n) ;
Совет 2
Совет 2
Бывает так, что средства проектирования форм вашей СУБД не могут осуществить все нужные проверки, гарантирующие целостность данных. В таком случае вам придется создавать собственные процедуры ввода, в которых вводимые значения присваиваются переменным и проверяются с помощью кода самой прикладной программы. Затем, убедившись, что все значения, введенные для табличной строки, являются правильными, программа может добавить эту строку в таблицу с помощью команды SQL INSERT (вставить).
Квадратные скобки ([]) означают, что список имен столбцов не является обязательным. По умолчанию порядок расположения столбцов в списке является таким же, как и в таблице. Если расположить значения, находящиеся после ключевого слова VALUES (значения), в том же порядке, в каком столбцы находятся в таблице, то эти элементы попадут в нужные столбцы — неважно, указаны при этом столбцы явно или нет. А если требуется расположить эти значения в порядке, который не совпадает с расположением столбцов в таблице, то тогда имена столбцов необходимо перечислить в требуемом порядке.
Чтобы ввести, например, запись в таблицу CUSTOMER (покупатель), используйте следующий синтаксис:
INSERT INTO CUSTOMER (CustomerlD, FirstName, LastName,
Street, City, State, Zipcode, Phone)
VALUES (:vcustid, 'David1, 'Taylor', '235 Nutley Ave.',
'Nutley', 'NJ', '07110', '(201) 555-1963') ;
После ключевого слова VALUES первым стоит vcustid — базовая переменная-счетчик, значение которой с помощью программного кода увеличивается на единицу, как только в таблицу введена новая строка. Это дает гарантию, что не будет дублирования значений в столбце CustomerlD (идентификатор покупателя). CustomerlD является первичным ключом для этой таблицы и поэтому должен оставаться уникальным. Остальные значения в операторе являются не переменными с элементами данных, а самими элементами данных. Конечно, элементы данных для этих столбцов также можно, если хотите, поместить в переменные. Оператор INSERT работает одинаково хорошо с аргументами ключевого слова VALUES, выраженными как в форме переменных, так и в форме значений.
Добавление новых данных
Добавление новых данных
В базе данных каждая таблица появляется на свет пустой, т.е. сразу после своего создания (или с помощью DDL из SQL, или с помощью RAD-инструмента) такая таблица является не чем иным, как структурной оболочкой, не содержащей данных. Чтобы таблица стала полезной, в нее необходимо поместить некоторые данные. Эти данные могут быть уже в цифровом виде, т.е. введенными в компьютер, или еще нет.
Если данные еще не в цифровом виде, то кто-то должен будет вводить их построчно с помощью клавиатуры и монитора. Кроме того, данные можно вводить и с помощью оптических сканеров и систем распознавания речи. Правда, для ввода данных такие устройства используются пока что достаточно редко. Если данные уже находятся в цифровом виде, но, возможно, не в формате, используемом в таблицах базы данных, тогда данные прежде всего надо преобразовать в соответствующий формат, а затем вставить их в базу. Даже если данные находятся уже в цифровом виде и в нужном формате, то может возникнуть необходимость перенести их в новую базу данных.В зависимости от того состояния, в котором находятся данные, их или сразу можно перевести в базу с помощью одной операции, или, возможно, потребуется вводить в виде отдельных записей одну за другой. Каждая такая запись будет соответствовать одной строке из какой-либо таблицы базы данных.
Добавление в таблицу группы строк
Добавление в таблицу группы строк
Добавлять в таблицу строки одну за другой, используя для этого оператор INSERT, становится ужасно скучным — особенно если это растягивается на целый день. Даже вводить данные в экранную форму, тщательно продуманную с точки зрения эргономики, через некоторое время становится утомительным. Ясно, что если у вас есть надежный способ автоматического ввода данных, вы будете стараться использовать его вместо ввода вручную везде, где это возможно.
Автоматический ввод, например, можно использовать тогда, когда данные уже представлены в электронном виде, благодаря тому, что кто-то уже ввел вручную эти данные в компьютер. Незачем повторять эту рутинную работу. Перенести данные из одного файла в другой можно с минимальным участием человека. Если вам известны характеристики исходных данных и нужная форма таблицы, в которую должны быть перенесены данные, то компьютер может в принципе выполнить такой перенос данных автоматически.
Манипуляции данными из базы
Глава 6. Манипуляции данными из базы
Копирование из внешнего файла данных
Копирование из внешнего файла данных
Предположим, что вы создаете базу данных для нового приложения. Некоторые из нужных вам данных уже имеются в каком-либо файле. Это может быть плоский файл или таблица базы данных, работающей в СУБД, отличающейся от той, которую используете вы. Данные могут быть в коде ASCII, EBCDIC или в каком-нибудь другом закрытом внутреннем формате. Так что же делать?
Прежде всего — это надеяться и молиться, чтобы нужные вам данные были представлены в каком-нибудь широко используемом формате. Если это достаточно популярный формат, то у вас имеется хороший шанс достать утилиту преобразования формата, которая может преобразовать данные в один или несколько других популярных форматов. А затем как минимум один из этих форматов можно импортировать в вашу среду разработки. А если повезет, то можно будет преобразовать текущий формат данных с помощью встроенных средств среды. Вероятно, самыми распространенными на персональных компьютерах форматами являются Access, dBASE и Paradox. Если нужные вам данные находятся в одном из этих форматов, преобразование должно пройти легко. Ну а если формат данных является не таким распространенным, то, видимо, преобразование все-таки придется провести в два этапа.
И с последней надеждой можно всегда обратиться к специальным профессиональным службам преобразования данных. Они специализируются на оказании услуг по преобразованию компьютерных данных из одного формата в другой. У них есть возможность обрабатывать сотни разных форматов — о большинстве из которых никто никогда и не слышал. Передайте одной из этих служб ленту или диск с данными в первоначальном формате, и вы получите назад те желанные, но преобразованные в любой из форматов, который только укажете.
Обновление имеющихся данных
Обновление имеющихся данных
Все течет, все изменяется. Если вам не нравится нынешнее положение дел, то надо немного подождать. Через некоторое время существующее положение изменится.
И так как мир постоянно преобразуется, то надо также обновлять и базы данных, с помощью которых моделируются его компоненты. Покупатель, возможно, поменял адрес. Может измениться количество какого-либо товара на складе, будем надеяться не в результате воровства, а потому что товар хорошо расходится. Это типичные примеры тех событий, из-за которых приходится обновлять базу данных.
В языке SQL для изменения данных, хранящихся в таблице, имеется оператор UPDATE (обновить). С помощью одного такого оператора можно изменить в таблице одну строку, несколько или все ее строки. В операторе UPDATE используется следующий синтаксис:
UPDATE имя_таблицы
SET столбец_1 - выражение_1, столбец_2 = выражение_2,
. . . , столбец_n = выражение__n
[WHERE предикаты] ;
Предложение WHERE (где) не является обязательным. Оно указывает, какие строки должны обновляться. Если это предложение не используется, то будут обновляться все строки таблицы. В свою очередь предложение SET (установить) указывает новые значения изменяемых столбцов.
Проанализируйте с помощью табл. 6.1 таблицу CUSTOMER (покупатель), имеющую столбцы Name (имя и фамилия), City (город), Area-Code (телефонный код региона) и Telephone (телефон).
Обновление представлений
Обновление представлений
Созданные таблицы автоматически поддерживают возможности вставки, обновления И удаления данных. А вот к представлениям это относится не всегда. Обновляя представление, вы на самом деле обновляете исходную таблицу. Вот две потенциальные проблемы, возникающие при обновлении представлений.
Некоторые представления берут свои данные не менее чем из двух таблиц, Если вы обновляете только представление, то как же узнать, какая из исходных таблиц была обновлена вместе с ним? В определении представления могут находиться выражения, относящиеся к предложению SELECT. Тогда каким образом это выражение можно обновлять?Предположим, что вы создаете представление СОМР из таблицы EMPLOYEE (сотрудник), используя се поля EmpName (фамилия), SALARY (оклад) и Comm (комиссионные). Для этого вы используете следующий оператор:
CREATE VIEW COMP AS
SELECT EmpName, Salary+Comm AS Pay
FROM EMPLOYEE ;
Можно ли в представлении обновить столбец PAY (оплата), используя следующий оператор?
UPDATE COMP SET Pay = Pay + 100 ;
Нет, этот подход не сработает потому, что в таблице EMPLOYEE нет столбца Pay, и в ней он обновлен не будет, а следовательно, не будет обновлен и в представлении. Представление не может показать того, чего нет в исходной таблице.
Помни: Когда вы думаете об обновлении представлений, не забывайте следующее правило. Столбец представления обновлять нельзя, если он не соответствует столбцу таблицы этого представления.
Перемещение данных
Перемещение данных
Помимо команд INSERT и UPDATE, можно воспользоваться командой MERGE (слияние), чтобы добавить данные в таблицу или представление. Команда MERGE позволяет производить "слияние" данных исходных таблиц, представления — в нужные таблицы или сами представления. Эта же команда позволяет вставить новые строки в нужную таблицу или обновить существующие строки. Таким образом, команда MERGE представляет собой весьма удобный способ копирования уже существующих данных из одного местоположения в новое, необходимое пользователю.
Возьмем, к примеру, базу данных VetLab (см. главу 5). Предположим, что некоторые работники, занесенные в таблицу EMPLOYEE, — это продавцы, которые уже приняли заказы, а другие — это работники, не связанные напрямую с продажами, или продавцы, которые еще не взяли заказы. Только что закончившийся год был прибыльным, поэтому вы решили дать премии по 100 долларов каждому, кто принял по крайней мере один заказ, и по 50 долларов всем остальным. Для начала давайте создадим таблицу BONUS (бонус) и вставим в нее записи для каждого работника, который появляется хотя бы однажды в таблице ORDERS, задавая каждой записи значение премии по умолчанию 100 долларов.
Затем воспользуемся командой MERGE, чтобы вставить новые записи для тех работников, которые не имеют заказов, давая им премии 50 долларов. Ниже приведен программный код, который позволяет создать и заполнить таблицу BONUS.
| СREARE TABLE BONUS ( | ||
| EmployeeName | CHARACTER (30) | PRIMARY KEY |
| Bonus | NUMERIC | DEFAULT 100 ) ; |
INSERT INTO BONUS (EmployeeName)
(SELECT EmployeeName FROM EMPLOYEE, ORDERS
WHERE EMPLOYEE.EmployeeName = ORDERS.Salesperson
GROUP BY EMPLOYEE.EmployeeName) ;
Теперь сделаем запрос для таблицы BONUS и посмотрим, что она содержит.
| SELECT * FROM BONUS ; | |
| EmployeeName | BONUS |
| ---------------- | ------- |
| Brynna Jones | 100 |
| Chris Bancroft | 100 |
| Greg Bosser | 100 |
| Kyle Weeks | 100 |
Затем выполним команду MERGE, чтобы назначить премии по 50 долларов для всех остальных работников.
MERGE INTO BONUS
USING EMPLOYEE
ON (BONUS.EmployeeName = EMPLOYEE.EmployeeName)
WHEN NOT MATCHED THEN INSERT
(BONUS.EmployeeName, BONUS,bonus)
VALUES (EMPLOYEE.EmployeeName, 50) ;
Записи для людей в таблице EMPLOYEE, которые не соответствуют записям для тех же людей, но уже в таблице BONUS, будут вставлены в таблицу BONUS. Теперь запрос таблицы BONUS дает следующее:
| SELECT * FROM BONUS ; | |
| EmployeeName | BONUS |
| ---------------- | ------- |
| Brynna Jones | 100 |
| Chris Bancroft | 100 |
| Greg Bosser | 100 |
| Kyle Weeks | 100 |
| Neth Doze | 50 |
| Matt Bak | 50 |
| Sam Saylor | 50 |
| Nic Foster | 50 |
Первые четыре записи, созданные с помощью команды INSERT, располагаются в алфавитном порядке по именам работников. Остальные записи, добавленные с помощью команды MERGE, располагаются в том порядке, в котором они были в таблице EMPLOYEE.
Перенос всех строк из одной таблицы в другую
Перенос всех строк из одной таблицы в другую
Много проще, чем импортировать внешние данные, извлекать данные, уже находящиеся водной из таблиц вашей базы, и комбинировать их с данными из другой таблицы. В самом простом случае структура второй таблицы идентична структуре первой. Это означает, что каждый столбец первой таблицы имеет соответствующий столбец во второй, а типы данных соответствующих столбцов совпадают. В таком случае содержимое двух таблиц можно комбинировать с помощью реляционного оператора UNION (объединение). В результате получается виртуальная таблица, в которой содержатся данные исходных таблиц. О реляционных операторах, в том числе о UNION, рассказывается в главе 10.
Перенос выбранных столбцов и строк из одной таблицы в другую
Перенос выбранных столбцов и строк из одной таблицы в другую
Часто бывает так, что данные исходной таблицы не соответствуют в точности структуре той таблицы, в которую вы собираетесь их поместить. Возможно, соответствуют друг другу только некоторые из столбцов — и это как раз те столбцы, которые вы хотите перенести. Комбинируя операторы SELECT с помощью оператора UNION, можно указать, какие столбцы из исходных таблиц должны войти в полученную в результате виртуальную таблицу. Используя в операторах SELECT предложения WHERE, можно помещать в виртуальную таблицу только те строки, которые удовлетворяют определенным условиям. Предложения WHERE достаточно подробно описываются в главе 9.
Предположим, у вас имеются две таблицы, PROSPECT (потенциальный клиент) и CUSTOMER (покупатель), и вам нужно составить список всех жителей штата Мэн, данные о которых находятся в обеих таблицах. Тогда можете создать виртуальную таблицу с нужной информацией, используя следующую команду:
SELECT FirstName, LastName
FROM PROSPECT
WHERE State = 'ME'
UNION
SELECT FirstName, LastName
FROM CUSTOMER
WHERE State = 'ME'
В этом коде заключено следующее:
Операторы SELECT говорят о том, что у созданной таблицы будут столбцы FirstName (имя) и LastName (фамилия). Предложения WHERE ограничивают количество строк в этой таблице, выбирая лишь те, у которых в столбце State (штат) находится значение 'ME' (штат Мэн). Столбца State в созданной таблице не будет, но он находится в двух исходных таблицах: в PROSPECT и CUSTOMER. Оператор UNION объединяет результаты, полученные при выполнении SELECT, отдельно с PROSPECT и отдельно с CUSTOMER, удаляет все дублированные строки, а затем выводит окончательный результат на экран.Другой способ копировать данные в базе из одной ее таблицы в другую состоит в том, чтобы разместить оператор SELECT в операторе INSERT. Такой метод (подвыборка) виртуальной таблицы не создает, а просто дублирует выбранные данные. Например, вы можете взять все строки из таблицы CUSTOMER и вставить их в таблицу PROSPECT. Конечно, эта операция удастся только в том случае, если у обеих этих таблиц одинаковая структура. Далее, если нужно отобрать только тех покупателей, которые живут в штате Мэн, то достаточно простого оператора SELECT, имеющего в предложении WHERE всего лишь одно условие. Соответствующий код показан в следующем примере:
INSERT INTO PROSPECT
SELECT * FROM CUSTOMER
WHERE State = 'ME' ;
Получение данных
Получение данных
Задача, которую выполняют пользователи, манипулируя данными чаще всего состоит в том, чтобы получить из базы выбранную информацию. Допустим, вы хотите получить содержимое одной определенной строки, находящейся в таблице среди тысяч других. Или, возможно, требуется получить все строки, удовлетворяющие какому-либо условию или комбинации условий. А может быть, вы хотите получить из таблицы все ее строки. Для решения всех этих задач предназначен оператор SQL SELECT.
Проще всего с помощью оператора SELECT получить все данные, хранящиеся во всех строках определенной таблицы. Для этого используется следующий синтаксис:
SELECT * FROM CUSTOMER ;
Помни: Звездочка (*)— это символ-маска, который означает "все". В данном примере этот символ стоит вместо перечня всех имен столбцов из таблицы CUSTOMER. В результате выполнения этого оператора на экран выводятся все данные, находящиеся во всех строках и столбцах этой таблицы.
Операторы SELECT могут быть намного сложнее, чем тот, который приведен в примере. Некоторые из них могут быть настолько сложными, что в них становится почти невозможно разобраться. Это связанно с тем, что есть возможность к основному оператору присоединять еще и множество уточняющих предложений. Подробно об уточняющих предложениях рассказывается в главе 9. В этой же главе кратко говорится о предложении WHERE — самом распространенном способе ограничить количество строк, возвращаемых оператором
SELECT.
Оператор SELECT с предложением WHERE имеет такой общий вид:
SELECT список_столбцов FROM имя_таблицы
WHERE условие ;
Список столбцов указывает, какие столбцы таблицы следует отобразить при выводе. Этот оператор отобразит только те столбцы, которые вы запросите. Предложение FROM определяет имя той таблицы, столбцы которой требуется отобразить. А предложение WHERE исключает те строки, которые не удовлетворяют указанному условию. Условие может быть простым (например, WHERE CUSTOMER_STATB= 'NH', где CUSTOMER_STATE означает "штат, где проживает клиент", a NH — "штат Нью-Хэмпшир") или составным (например, WHERE CUSTOMER_STATE= 'NH' AND STATUS='Active', где STATUS означает "статус", a Active — "активный").
Следующий пример показывает, как выглядит составное условие внутри оператора SELECT:
SELECT FirstName, LastName, Phone FROM CUSTOMER
WHERE State= 'NH'
AND Status='Active' ;
Этот оператор возвращает фамилии и телефонные номера всех активных клиентов, живущих в штате Нью-Хэмпшир. Ключевое слово AND означает следующее: чтобы строка была возвращена, она должна соответствовать сразу двум условиям, State= 'NH' и Status='Active'.
Представление ORDERS_BY_STATE
Рисунок 6.1. Представление ORDERS_BY_STATE, предназначенное для менеджера по маркетингу
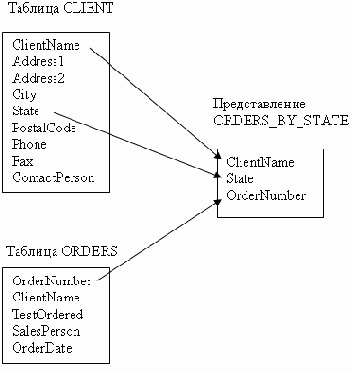
Представление для менеджера по маркетингу создается с помощью следующего оператора:
CREATE VIEW ORDERS_BY_STATE
(ClientName, State, OrderNumber)
AS SELECT CLIENT. ClientName, State, OrderNumber
FROM CLIENT, ORDERS
WHERE CLIENT.ClientName = ORDERS.ClientName;
В новом представлении имеются три столбца: ClientName (название фирмы-клиента), State (штат) и OrderNumber (номер заказа). ClientName находится как в CLIENT, так и в ORDERS и используется для связи между этими двумя таблицами. Новое представление получает информацию из столбца State таблицы CLIENT и берет для каждого заказа значение из столбца OrderNumber таблицы ORDERS. В приведенном примере имена столбцов нового представления объявляются явно. Впрочем, если имена точно такие же, как и у соответствующих столбцов исходных таблиц, то такое объявление не обязательно. Пример, приведенный в следующем разделе, демонстрирует похожий оператор CREATE VIEW, в котором имена столбцов для представления явно не указываются, а только подразумеваются.
Представление REPORTINGJAG (задержка
Рисунок 6.2. Представление REPORTINGJAG (задержка результатов), предназначенное для чиновника из службы контроля качества
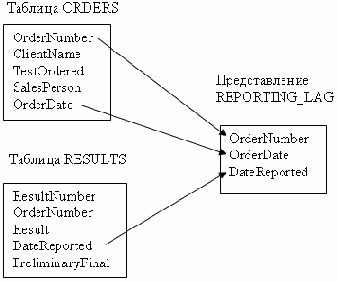
Ниже приведен код, с помощью которого создается представление, приведенное на Рисунок 6.2.
CREATE VIEW REPORTING_LAG
AS SELECT ORDERS.OrderNumber, OrderDate, DateReported
FROM ORDERS, RESULTS
WHERE ORDERS. OrderNumber = RESULTS. OrderNumber
AND RESULTS.PreliminaryFinal = 'F' ;
В представлении REPORTTNG_LAG содержится информация из таблицы ORDERS по датам заказов и из таблицы RESULTS по датам окончательных результатов. В этом представлении появляются только строки, у которых в столбце PRELIMJFINAL (предварительный-окончательный), взятом из таблицы RESULTS, находится значение 'F (от слова "final" — окончательный).
З Представление созданное
Рисунок 6.З. Представление, созданное, чтобы показать скидки в честь дня рождения
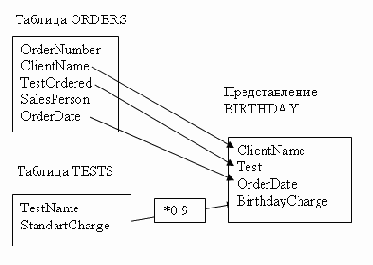
Представления можно создавать как на основе множества таблиц, что и делалось в предыдущих примерах, так и на основе всего лишь одной таблицы. Если вам не нужны определенные столбцы и строки какой-либо таблицы, то создайте представление, в котором нет этих строк и столбцов, а затем работайте уже не с таблицей, а с представлением. Этот подход защищает пользователя от путаницы и не отвлекает внимание, которые бывают при просмотре участков таблицы, не относящихся к делу.
Совет 1
Совет 1
Еще одной причиной создания представлений является обеспечение безопасности исходных таблиц базы данных. Одни столбцы ваших таблиц следует открыть, а другие, наоборот, скрыть. В таком случае можно создать представление только с теми столбцами, которые вы хотите сделать доступными, затем предоставить к нему широкий доступ, а доступ к исходным таблицам этого представления— ограничить. В главе 13 объясняется, каким образом обеспечивается безопасность баз данных, и описывается, как предоставлять полномочия на доступ к данным и лишать их.
Создание представлений
Создание представлений
Структура базы данных, спроектированной в соответствии с разумными принципами — включая и подходящую нормализацию, — обеспечивает максимальную целостность данных. Однако такая структура часто не позволяет обеспечить лучший способ их просмотра. Одни и те же данные могут использоваться разными приложениями, и у каждого из них может быть своя специализация. Одним из самых сильных качеств SQL является возможность выводить данные в виде представлений, чья структура отличается от структуры тех таблиц базы, в которых реально хранятся эти данные. Таблицы, столбцы и строки которых используются при создании представления, называются базовыми. В главе 3 говорилось о представлениях как о части языка определения данных (Data Definition Language, DDL). А в этом разделе представления рассматриваются как одно из средств, предназначенных для получения данных и манипуляции ими.
Оператор SELECT всегда возвращает результат в виде виртуальной таблицы. Представление же принадлежит к особой разновидности этих таблиц. От остальных виртуальных таблиц оно отличается тем, что в метаданных базы хранится его определение. Представление других виртуальных таблиц похоже на реальную таблицу базы данных. Работать с представлением можно так же, как и с настоящей таблицей базы данных. Разница здесь в том, что совокупность данных, находящихся в представлении, не является физически независимой частью базы данных. Представление извлекает их из одной или множества таблиц, из которых и были выбраны его столбцы. В каждом приложении могут быть свои собственные, непохожие друг на друга представления, но созданные на основе одних и тех же данных.
Обратите внимание на базу данных VetLab (см. главу 5). Эта база состоит из пяти таблиц: CLIENT (фирма-клиент), TESTS (анализы), EMPLOYEE (сотрудник), ORDERS (заказы) и RESULTS (результаты). Предположим, что главному менеджеру по маркетингу компании VetLab необходимо посмотреть, из каких штатов в эту компанию приходят заказы. Часть этой информации находится в таблице CLIENT, а часть — в ORDERS. А чиновнику из службы контроля качества требуется сравнить дату оформления заказа на один из анализов и дату получения его окончательного результата. Для этого сравнения требуются некоторые данные из таблицы ORDERS и RESULTS. В каждом конкретном случае можно создать представления, предоставляющие в точности те данные, которые требуются.
Создание представлений из таблиц
Создание представлений из таблиц
Для менеджера по маркетингу можно создать представление ORDERS_BY_STATE (заказы по штатам), приведенное на Рисунок 6.1.
Создание представления с модифицированным атрибутом
Создание представления с модифицированным атрибутом
В примерах из двух предыдущих разделов предложения SELECT содержат только имена столбцов. Впрочем, в любом предложении SELECT может находиться не только имя, но и выражение. Предположим, что владелец VetLab отмечает свой день рождения и хочет в честь этого события предоставить всем своим клиентам 10-процентную скидку. Он может на основе двух таблиц, ORDERS и TESTS, создать представление BIRTHDAY (день рождения).
Вполне возможно, что оно будет создано так, как показано в следующем примере:
CREATE VIEW BIRTHDAY
(ClientName, Test, OrderDate, BirthdayCharge)
AS SELECT ClientName, TestOrdered, OrderDate,
StandardCharge * .9
FROM ORDERS, TESTS
WHERE TestOrdered = TestName ;
Обратите внимание, что в представлении BIRTHDAY второй столбец — Test (анализ) — соответствует столбцу TestOrdered (заказанный анализ) из таблицы ORDERS, который также соответствует столбцу TestName (название анализа) из таблицы TESTS. Как создать это представление, можно увидеть на Рисунок 6.3.
Создание представления с условием выборки
Создание представления с условием выборки
Как видно в примере на Рисунок 6.2, для чиновника из службы контроля качества требуется представление, отличающееся от того, которое использует менеджер по маркетингу.
Таблица CUSTOMER
Таблица 6.1. Таблица CUSTOMER
| Name | City | AreaCode | Telephone |
| Abe Abelson | Springfield | (714) | 555-1111 |
| Bill Bailey | Decatur | (714) | 555-2222 |
| Chuck Wood | Philo | (714) | 555-3333 |
| Don Stetson | Philo | (714) | 555-4444 |
| Dolph Stetson | Philo | (714) | 555-5555 |
Время от времени списки покупателей изменяются, по мере того как эти люди переезжают, изменяются номера телефонов и т.д. Предположим, что Эйб Эйбелсон (Abe Abelson) переехал из Спрингфилда в Канкаки. Тогда запись этого покупателя, находящуюся в таблице CUSTOMER, можно обновить с помощью следующего оператора UPDATE:
UPDATE CUSTOMER
SET City = 'Kankakee1, Telephone = '666-6666'
WHERE Name = 'Abe Abelson1 ;
В результате его выполнения в записи произошли изменения, которые показаны в табл. 6.2.
Таблица CUSTOMER после
Таблица 6.2. Таблица CUSTOMER после обновления одной строки оператором update
| Name | City | AreaCode | Telephone |
| Abe Abelson | Kankakee | (714) | 666-6666 |
| Bill Bailey | Decatur | (714) | 555-2222 |
| Chuck Wood | Philo | (714) | 555-3333 |
| Don Stetson | Philo | (714) | 555-4444 |
| Dolph Stetson | Philo | (714) | 555-5555 |
Похожий оператор можно использовать, чтобы обновить сразу множество строк. Предположим, что город Файло переживает резкий рост населения и ему теперь требуется собственный телефонный код региона. Все строки покупателей, проживающих в этом городе, можно сразу изменить с помощью одного оператора UPDATE:
UPDATE CUSTOMER
SET AreaCode = '(619)'
WHERE City = 'Philo' ;
Теперь таблица CUSTOMER выглядит так, как показано в табл. 6.3.
Таблица CUSTOMER после
Таблица 6.3. Таблица CUSTOMER после обновления нескольких строк оператором update
| Name | City | Area-Code | Telephone |
| Abe Abelson | Kankakee | (714) | 666-6666 |
| Bill Bailey | Decatur | (714) | 555-2222 |
| Chuck Wood | Philo | (619) | 555-3333 |
| Don Stetson | Philo | (619) | 555-4444 |
| Dolph Stetson | Philo | (619) | 555-5555 |
Обновить в таблице все строки даже легче, чем только некоторые из них. Ведь в таком случае не надо использовать ограничивающее предложение WHERE. Представьте, что город Рантул значительно увеличился в размерах и в его состав вошли не только Канкаки, Декейтер и Файло, но и все остальные города и городки, упомянутые в базе данных. Тогда все строки можно сразу изменить с помощью одного оператора:
UPDATE CUSTOMER
SET City = 'Rantoul' ;
Результат показан в табл. 6.4.
Таблица CUSTOMER после
Таблица 6.4. Таблица CUSTOMER после обновления всех строк оператором update
| Name | City | Area-Code | Telephone |
| Abe Abelson | Rantoul | (714) | 666-6666 |
| Bill Bailey | Rantoul | (714) | 555-2222 |
| Chuck Wood | Rantoul | (619) | 555-3333 |
| Don Stetson | Rantoul | (619) | 555-4444 |
| Dolph Stetson | Rantoul | (619) | 555-5555 |
В предложении WHERE, используемом для ограничения тех строк, к которым применяется оператор UPDATE, может находиться подвыборка. Подвыборка дает возможность обновлять строки одной таблицы на основе содержимого другой.
Предположим, что вы оптовый продавец и в вашей базе данных находится таблица VENDOR (поставщик) с названиями всех фирм-производителей, у которых вы покупаете товары. У вас также есть таблица PRODUCT (товар) с названиями всех продаваемых вами товаров и ценами, которые вы за них назначаете. В таблице VENDOR имеются столбцы VendorlD (идентификатор поставщика), VendorName (название поставщика), Street (улица), City (город), State (штаг) и Zip (почтовый код). А в таблице PRODUCT имеются столбцы ProductID (идентификатор товара), ProductName (название товара), VendorlD (идентификатор поставщика) и SalePrice (цена при продаже).
Предположим, поставщик Cumulonimbus Corporation принял решение поднять цены на все виды товаров на 10%. И для того чтобы поддержать планку своей прибыли, вам также придется поднять на 10% цены продажи продуктов, получаемых от этого поставщика. Это можно сделать с помощью следующего оператора UPDATE:
UPDATE PRODUCT
SET SalePrice = (SalePrice * 1.1)
WHERE VendorlD IN
(SELECT VendorlD FROM VENDOR
WHERE VendorName = 'Cumulonimbus Corporation') ;
Подстрока находит то значение из столбца VendorlD, которое соответствует Cumulonimbus Corporation. Затем полученное значение можно использовать для поиска в таблице PRODUCT тех строк, которые следует обновить. Цены всех товаров, полученных от Cumulonimbus Corporation, повышаются на 10%, а цены остальных остаются прежними. О подвыборках более подробно рассказывается в главе 11.
Удаление устаревших данных
Удаление устаревших данных
С течением времени данные могут устаревать и становиться бесполезными. Ненужные данные, находясь в таблице, только замедляют работу системы, расходуют память и путают пользователей. Возможно, лучше перенести старые данные в архивную таблицу, а затем поместить архив с этой таблицей вне системы. Таким образом, в случае такого маловероятного события, когда потребуется снова взглянуть на эти данные, их можно будет восстановить. А в остальное время они не будут замедлять ежедневную обработку данных. Впрочем, независимо от того, было ли решено архивировать устаревшие данные или нет, все же наступит время, когда их надо будет удалить. Для удаления строк из таблицы, находящейся в базе данных, в языке SQL предназначен оператор DELETE (удалить).
С помощью единственного оператора DELETE можно удалить как все строки таблицы, так и некоторые из них. Строки, предназначенные для удаления, можно выбрать, используя в операторе DELETE необязательное предложение WHERE. Синтаксис оператора DELETE такой же, как и в операторе SELECT, за исключением того, что столбцы указывать не надо. При удалении строки удаляются все данные, находящиеся в ее столбцах.
Предположим, например, что ваш клиент Дэвид Тейлор переехал на Таити и больше ничего у вас покупать не собирается. Вы можете удалить его данные из таблицы CUSTOMER, используя следующий оператор:
DELETE FROM CUSTOMER
WHERE FirstName = 'David' AND LastName = 'Taylor' ;
Если у вас только один покупатель, которого зовут Дэвид Тейлор, то этот оператор будет выполнен безупречно. А если существует вероятность, что Дэвидом Тейлором зовут как минимум двух ваших покупателей? Чтобы удалить данные именно того из них, к кому вы потеряли интерес, добавьте в предложение WHERE дополнительные условия (для таких столбцов, как, например. Street, Phone или CustomerlD).
Вывод информации, выбранной из одной
В этой главе...
Работа с данными Получение из таблицы нужных данных Вывод информации, выбранной из одной или множества таблиц Обновление информации, находящейся в таблицах и представлениях Добавление новой строки в таблицу Изменение всех или только некоторых данных, находящихся в строке таблицы Удаление строки таблицы В главах 3 и 4 вы узнали, что для обеспечения целостности информации, которая хранится в базе данных, очень важно создать хорошую структуру этой базы. Впрочем, для пользователя интерес представляет не структура базы данных, а ее содержимое, т.е. сами данные. С данными можно выполнять четыре следующих действия: добавлять в таблицы, получать и выводить, изменять, а также удалять из таблиц.
В принципе, манипуляции данными выполнять достаточно просто. Легко разобраться, каким образом можно добавить в таблицу одну или сразу несколько строк данных. Изменение, удаление и получение строк из таблиц баз данных также не представляют особого труда. Главная трудность манипуляций с базами данных состоит в выборе строк, которые требуется изменить, удалить или получить. Иногда получение данных напоминает складывание мозаики из ее фрагментов, которые перемешаны с фрагментами сотен других таких мозаик. Нужные данные обычно перемешаны с ненужными, причем последних во много раз больше. К счастью, вам требуется лишь точно указать, что именно вам нужно сделать с помощью оператора SELECT, а весь поиск выполнит компьютер.
SQL во встроенных инструментах
Оператор SELECT — это не единственное средство получения данных из базы. СУБД, как правило, имеют встроенные наглядные средства для манипуляций с данными. С помощью этих средств данные можно добавлять в базу, удалять их из нее, изменять хранящиеся в ней данные, а также отправлять запросы в базу.
В системах клиент/сервер реляционной базе данных, находящейся на сервере, обычно понятен только SQL. При разработке приложения для работы с базой данных с помощью СУБД или инструмента RAD вы обычно работаете с формами, поля которых соответствуют полям таблиц, входящих в базу данных. Поля форм ввода можно группировать по определенному принципу, а также сопровождать пояснительным текстом. Пользователь, работая на клиентской машине, может легко проверять или изменять данные в этих полях.
Допустим, что он меняет значения некоторых полей. При этом клиентская часть СУБД принимает значения, введенные пользователем с экранной формы, создает соответствующий оператор языка SQL, UPDATE, а затем отправляет этот оператор на сервер. Серверная часть СУБД выполняет этот оператор. Так что пользователи, работающие с реляционными базами данных, непосредственно или опосредованно, т.е. с помощью процесса трансляции, пользуются языком SQL.
Во многих клиентских частях СУБД имеется возможность выбора: использовать их встроенные средства или напрямую язык SQL. В некоторых случаях из СУБД нельзя "выжать" с помощью встроенных средств все то, что можно получить с помощью SQL. Так что в любом случае полезно изучить основы SQL, даже если вы большую часть времени пользуетесь встроенными средствами. Для выполнения операции, выходящей за пределы возможностей встроенных средств, необходимо понимать, каким образом работает язык SQL и что он может делать.
но зато увеличивается производительность выборок.
Внимание
Даже если эта операция и создает избыточные данные — данные о покупателях теперь хранятся в обеих таблицах, в PROSPECT и CUSTOMER, — но зато увеличивается производительность выборок. Чтобы избежать избыточности и поддерживать согласованность данных, делайте так, чтобы строки в одной таблице не вставлялись, не изменялись и не удалялись без вставки, изменения и удаления соответствующих строк в другой таблице. Может возникнуть еще одна проблема. Возможно, что оператор INCERT продублирует первичные ключи. Если существует один-единственный потенциальный клиент, имеющий ключ ProspectID, который совпадает с соответствующим первичным ключом CustomerlD покупателя, введенного в таблицу PROSPECT, тогда операция вставки будет неудачной.